今天我們將繼續介紹正則表達式,這次的任務圍繞在自然語言處理中流程的文本清理(text cleaning)。我們或許都曾聽過Garbage in, garbage out這諺語:錯誤、無意義的數據會誘導電腦做出錯誤的決策,其後果往往比沒有數據而不作為更具有毀滅性。在大數據時代,我們不再比照過去手刻有限的規則來建構一套專家系統(expert system),而是仰賴資料的特性,讓電腦學習其規則後做出決策。正因為如此,資料是某具有代表性(潔淨度)就成了至關重要的議題。
Garbage In, Garbage Out
圖片來源:David Dibert Photos
在序章我們見識到語料庫中含有HTML標籤,另外如藉由網路抓取(web scraping)而得到的原始文字資料也經常夾雜著大量無意義的字符: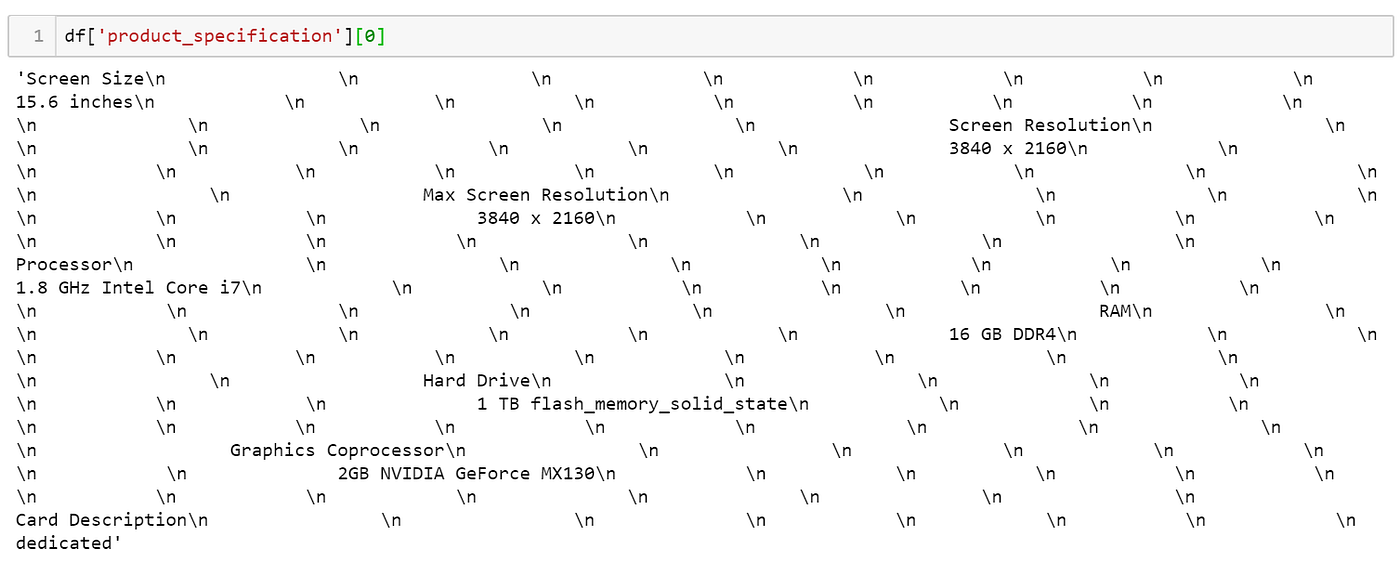
以下是常見的無意義字符分類:
就讓我們來看看如何清理以下HTML代碼:
為了運用正則表達式來製造pattern,我們先引入模組 re 。這時候我們使用 re.sub() 這個函式,並且傳遞三個必要引數(required arguments):
import re
raw_text = """
<html>
<head>
<title>My Garden - Tomatoes</title>
</head>
<body>
<h1>Garden Tomatoes</h1>
<p>I decided to plant some tomatoes this spring. They're really taking off and I hope to have lots of tomatoes to give to all my friends and family this summer!</p>
<p>Here are a few things I like about tomatoes:</p>
<ol>
<li>They taste great.</li>
<li>They're good for me.</li>
<li>They're easy to grow!</li>
</ol>
<p>Here's a picture of my garden:</p>
<img src="http://www.mygardensite.com/images/my-garden-001.jpg" alt="a picture of my garden" />
<p>Here's a <a href="http://www.welovetomatoes.com">link</a> to check out more interesting things about tomatoes!</p>
</body>
</html>
"""
text_no_tags = re.sub(r"<.*?>", '', raw_text)
print(text_no_tags)
來看看執行結果: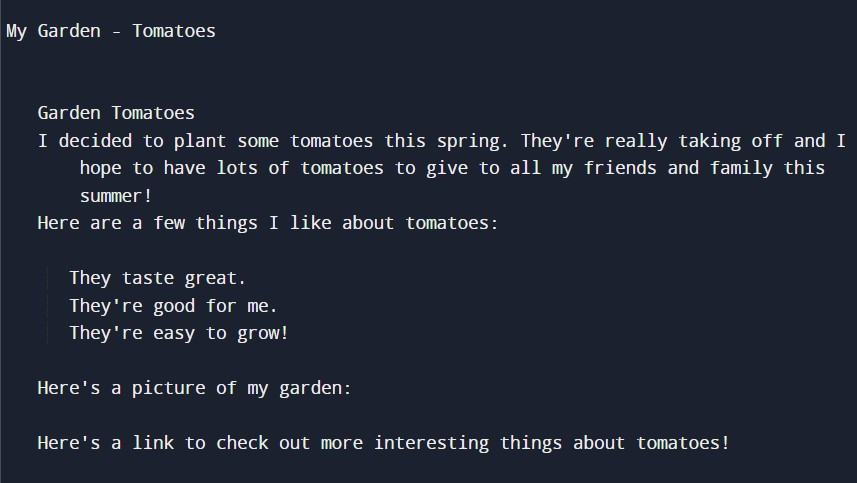
是不是將標籤都清除了呢?接下來我們將字串中多餘的空白一並去除!
這裡我們使用了代表 whitspace、tab、換行的元字元(metacharacter) \s。由於無意義空格佔了兩個半格以上的空間,因此pattern可以設計為 \s{2,},程式碼如下:
# to remove redundant whitespaces
text_no_whitespace = re.sub(r"\s{2,}", ' ', text_no_tags)
print(text_no_whitespace)
我們來檢視一下清除空白的文件:
關於正則表達式如何進行資料清理就先介紹到這裡,明天我們將介紹文本前處理的步驟,bis morgen!


 iThome鐵人賽
iThome鐵人賽