想要進行資料分析,要做的第一件事當然是收集資料,所幸現在是2021,我們不需要為了股票資料請一堆工讀生幫忙手動輸入資料,這部分已經有一堆公司/政府部門替我們做了,我們只要利用網路爬蟲,就可以把所有資料儲存下來,至於合法性的問題可以參考這篇。
抓取資料的部分估計會分成兩天說明
畢竟我打這行時已經只剩40分就Day 4了
前半部分會著重於簡單的基本資料,包括清單、成交紀錄等基礎資料,第二天會著重於三大法人、籌碼等分析會用到的進階資料,所有程式碼皆存放於Colab上,建議閱讀時實際測試一次,學習效果會更好。
如果想要一支股票的相關資訊,我們會需要知道一個股票的股票代碼,這個股票代碼就像人類的身分證字號,一個股票只會有一個特定的代碼,只要知道股票代碼,我們就可以依此來查閱該股票的相關資料,完整的股票清單請點這。
2330即是台積電專有代碼
由於台股清單是一個很常用的資料,很多股市的資料分析都會包括在內,因此我們暫時還不需要使用爬蟲,只需要從別人的資料擷取我們需要的部分就行了。
import pandas as pd
import requests
link = "https://quality.data.gov.tw/dq_download_json.php?nid=11549&md5_url=bb878d47ffbe7b83bfc1b41d0b24946e"
# Slice to Stock list
df = pd.DataFrame(requests.get(link).json())[["證券代號", "證券名稱"]]
df = df.rename(columns={"證券代號": "STOCK_ID", "證券名稱": "STOCK_NAME"})
df.to_csv("data/stock_id.csv", index=False, header=True)
df.head()
台股清單抓下來後,你可能會發現台灣的上市股票有上千種,如果真的要全部分析的話,複雜程度和麻煩程度都會直線的上升,因此我們先聚焦在足夠好的股票,而直接參考元大台灣50這種指數型股票也省下我們初步篩選的時間,然而ETF股票構成是會變動的,手動輸入資料不是不行,但如果要擴展到美股ETF這種動輒500種的股票,容易打錯不說,每個月都要手動更新500支股票怎麼想都很反人類。
根據Google結果,我們找到了近期的ETF50成份股,由於他沒提供CSV或API提供給我們下載/串接,所以我們必須使用爬蟲程式把網頁的圖表,手動轉換成Python的圖表格式。
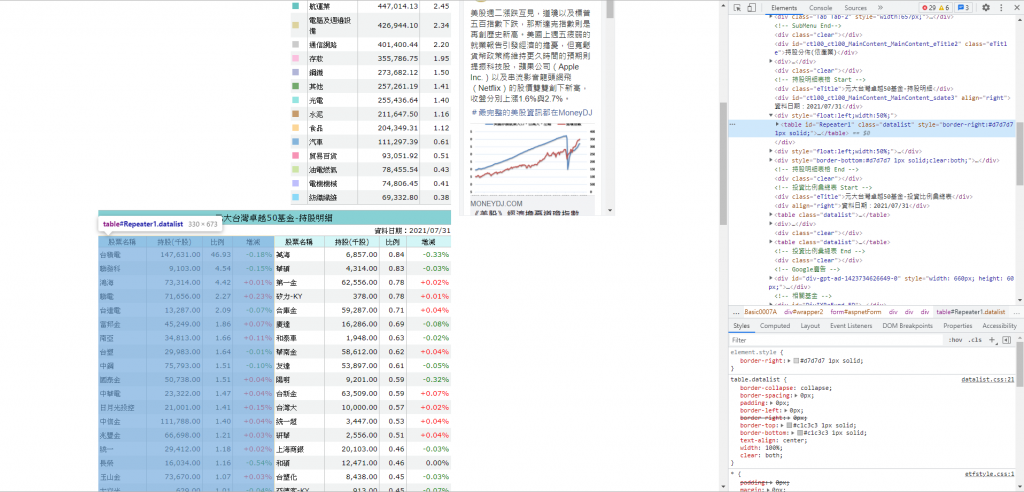
通過Chrome 開發者工具 F12可以清楚地得知我們要的區塊在哪
# Request html
retry_strategy = Retry(total=3)
adapter = HTTPAdapter(max_retries=retry_strategy)
http = requests.Session()
http.mount("https://", adapter)
http.mount("http://", adapter)
response = http.get("https://www.moneydj.com/ETF/X/Basic/Basic0007a.xdjhtm?etfid=0050.TW")
# Parser html
soup = BeautifulSoup(response.content, "html.parser")
df = pd.DataFrame()
row_index = 0
# Locate the table by find the sibling html tag which have id attribute
first_table = soup.find(id="ctl00_ctl00_MainContent_MainContent_sdate3").find_next_sibling()
stock_tag = first_table.find_all("td")
for i in range(0, len(stock_tag), 4):
stock_name = stock_tag[i].text.strip()
df.loc[row_index, "STOCK_NAME"] = stock_name
df.loc[row_index, "持股(千股)"] = stock_tag[i + 1].text.strip()
df.loc[row_index, "比例"] = stock_tag[i + 2].text.strip()
df.loc[row_index, "增減"] = stock_tag[i + 3].text.strip()
row_index += 1
stock_tag = first_table.find_next_sibling().find_all("td")
for i in range(0, len(stock_tag), 4):
stock_name = stock_tag[i].text.strip()
df.loc[row_index, "STOCK_NAME"] = stock_name
df.loc[row_index, "持股(千股)"] = stock_tag[i + 1].text.strip()
df.loc[row_index, "比例"] = stock_tag[i + 2].text.strip()
df.loc[row_index, "增減"] = stock_tag[i + 3].text.strip()
row_index += 1
# Combine with Stock ID
stock_df = pd.read_csv("data/stock_id.csv")
result_df = pd.merge(df, stock_df, how="left", on=["STOCK_NAME"])
result_df = result_df[["STOCK_ID", "STOCK_NAME", "持股(千股)", "比例", "增減"]]
拿到了ETF50的成份股清單,現在我們可以用它來提取個股的成交紀錄,理論上政府是有提供歷年的日/週成交紀錄,然而由於未知原因,你可以發現該資料從6月開始就沒再更新了。
還好現在我們有另一個選擇,Yahoo股市有維護自己的股市資料庫,甚至有專門的API提供串接,我們只需要提供股票代碼即可查詢歷年成交紀錄、報表、歷年股利等資料。
import pandas as pd
import yfinance as yf
etf50_df = pd.read_csv("data/ETF50.csv")
etf50_id = etf50_df.loc[:, "STOCK_ID"].astype(str) + ".TW"
etf50_id = etf50_id.str.cat(sep=" ")
# Download etf50 recent 1 years data
df = yf.download(etf50_id, group_by="Ticker", period="1y", interval="1d")
# rotate Ticker axis and convert to (Date,Ticker) index
df = df.stack(level=0).rename_axis(["Date", "Ticker"]).reset_index(level=1)
# drop index
df = df.reset_index(level=0)
df = df.rename(columns={"Ticker": "STOCK_ID"})
df = df[["STOCK_ID", "Date", "Adj Close", "Close", "High", "Low", "Open", "Volume"]]
df.to_csv("data/ETF50_10years.csv", index=False, header=True)
由於明天的爬蟲程式會需要大量網路存取動作,建議使用Google Colab來測試以避免存取過多,而被伺服器端封鎖IP,如果對Google Colab還不熟的話麻煩參考這篇。
我絕對不會說我一個晚上就被Ban了兩次

