那我就延續上一篇的實作吧!
已經將會用到的套件裝上,並且在網站的控制室找到所需的資訊位置,接下來就是撰寫程式啦!
下面我先用express套件來簡單架設伺服器,以便我用來觀看爬蟲下來的結果。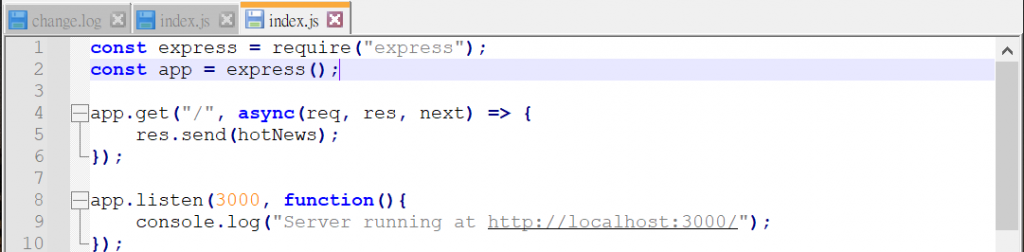
然後再利用superagent套件,用.get()的方法來訪問指定頁面,資料將會放在res中。
接下來就是用cheerio套件來獲取所需要的資料,頁面返回的資料會在res中,用.load()的方法去尋找指定id中的那些項目,比如說我是要找新聞標題,那標題的資訊在id = pane-news中下拉的…的項目中,就以下方程式碼第27行為例,接下來就是標示出新聞標題以及連結,最後存放在hotNews矩陣中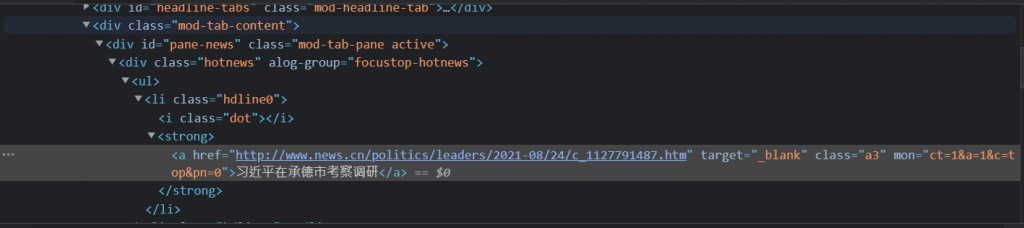

下面就是伺服器中跑出的結果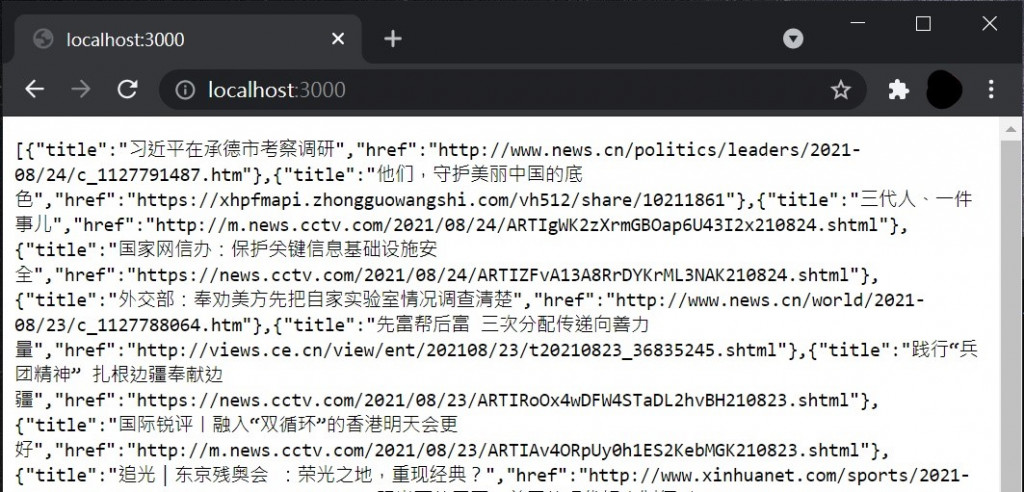
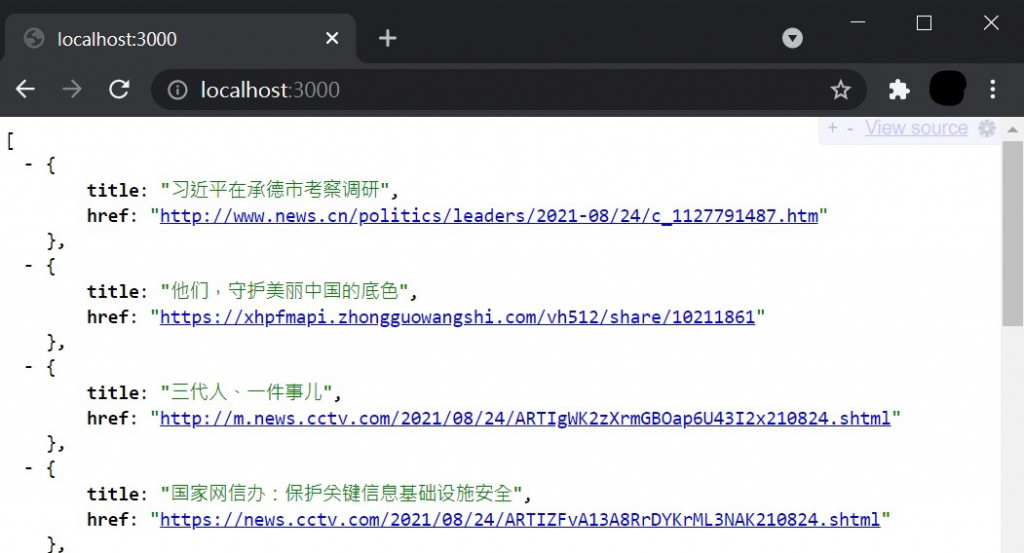
像上面那樣很難看清楚所收集的資料有哪些,所以我在chrome加裝了JSONView擴充功能,使結果能夠更整齊