老實說我就是一菜鳥小白,學習程式設計也不過一年多吧,而且也不是特別拿手,就是希望能透由這次的自主學習多得到些樂趣,能夠繼續堅定我走程式設計這條路的心。這是我第一次做這種自我學習的文章,就是可能會有很多我理解錯的地方,還請希望不小心點進來並且觀看的大大們,如果不嫌棄的話可以幫助我糾正我的錯誤,感謝!
那拉回正題,前兩天關於node.js的初步練習就先告一段落了,接下來就是正式開始爬蟲學習。這篇呢,會先講講我第一次爬蟲的準備,下一篇才會有實作,所以這篇可能會比較短吧。
首先,關於node.js的部分,我所要使用的套件有express(就上篇提到過能夠簡單架設一http伺服器)、superagent(關於這套件我也不是很了解,不過這次是要來請求目標頁面)、cheerio(這個好像是常見的爬蟲套件,主要是獲取所需的資料資訊),大概就這三個。下面是將三個套件裝在專案中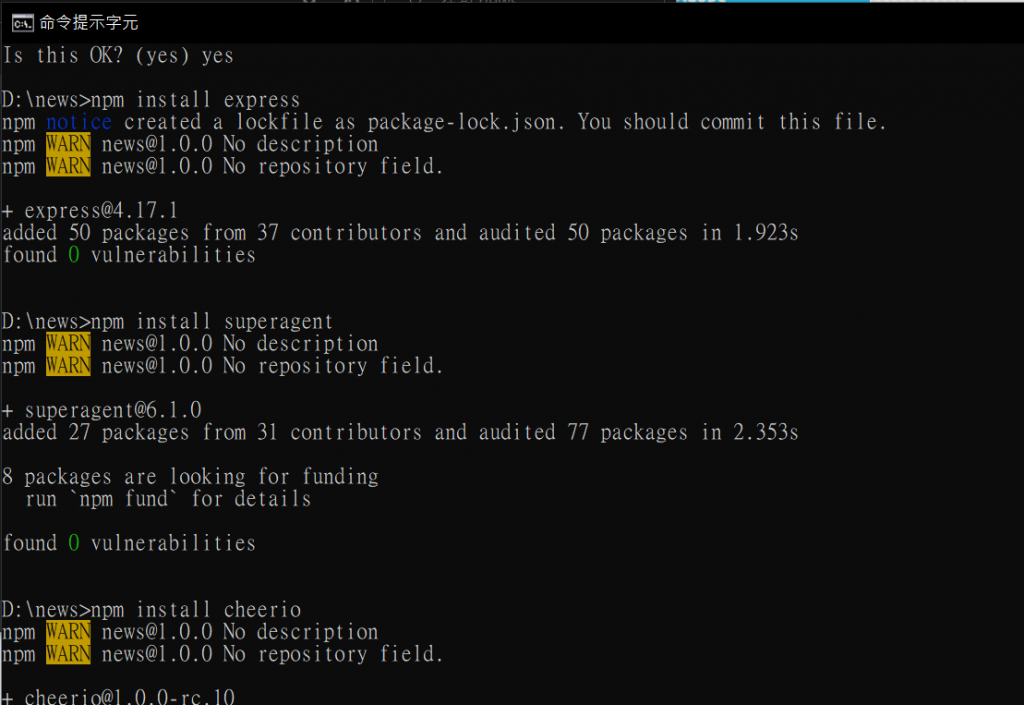
接下來是這次爬蟲的目標是新聞,百度新聞的熱點要聞。選新聞是因為感覺新聞標題一個個的,在頁面資訊中很容易分辨。那下面補充說如何快速找到所要資料的資訊結構。
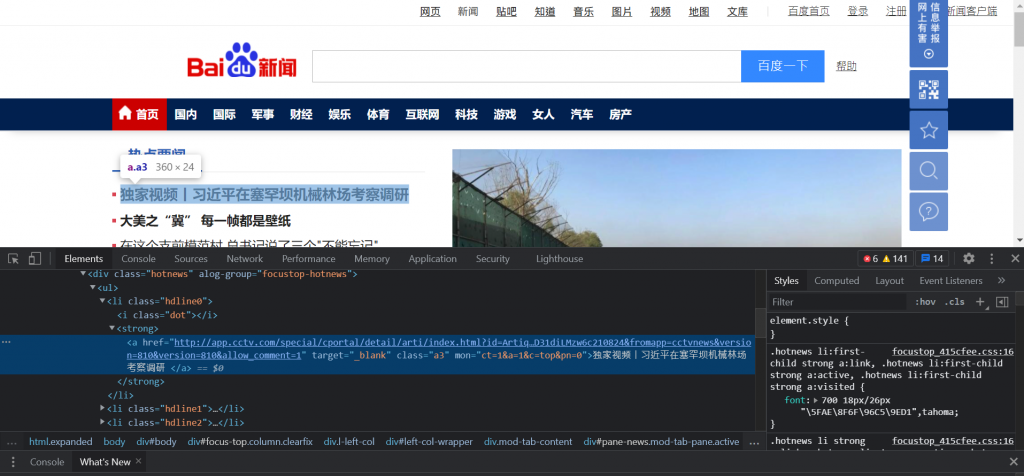
當然可以使用F12來打開控制台,但在茫茫資訊中想要找到所要的可能會花一些時間,所以只要將游標移置所要的資料上,點擊右鍵,選擇”檢查”,控制台出現的同時也會把資訊反白出來。