一. 前言
在如今社群網路蓬勃的時代,從網路充斥著許多文字資料,要如何有效的分析文字讓電腦可以知道我們餵進去的文字是什麼,所以才會有許多將文字、文章等轉成數字、向量的方法。
方法其實已經有很多,像是BOW(Bag of word)、one-hot represtation、tf-idf等,今天拿到了一篇文章,要將文章輸入 ML 模型,必須將句子或文章轉換成電腦看得懂的樣子(向量或數字),但怎麼樣表示才能真正代表這個句子或文章的意義呢?過去較長使用的方法為BOW(Bag of word)來表示一個句子或一個文本,但通常這樣的表示會造成一些上下文或語意的流失,近期NLP的任務大致上都是先經過word embedding(詞向量)層,再去做一些任務的預測,詞向量在向量空間中,相同語意的詞會靠很近,不同語意的詞會離很遠,如下圖,此圖來源如[1]所示,可以看到在不同詞向量可以將食物的詞聚再一起,旅遊相關的詞聚再一起: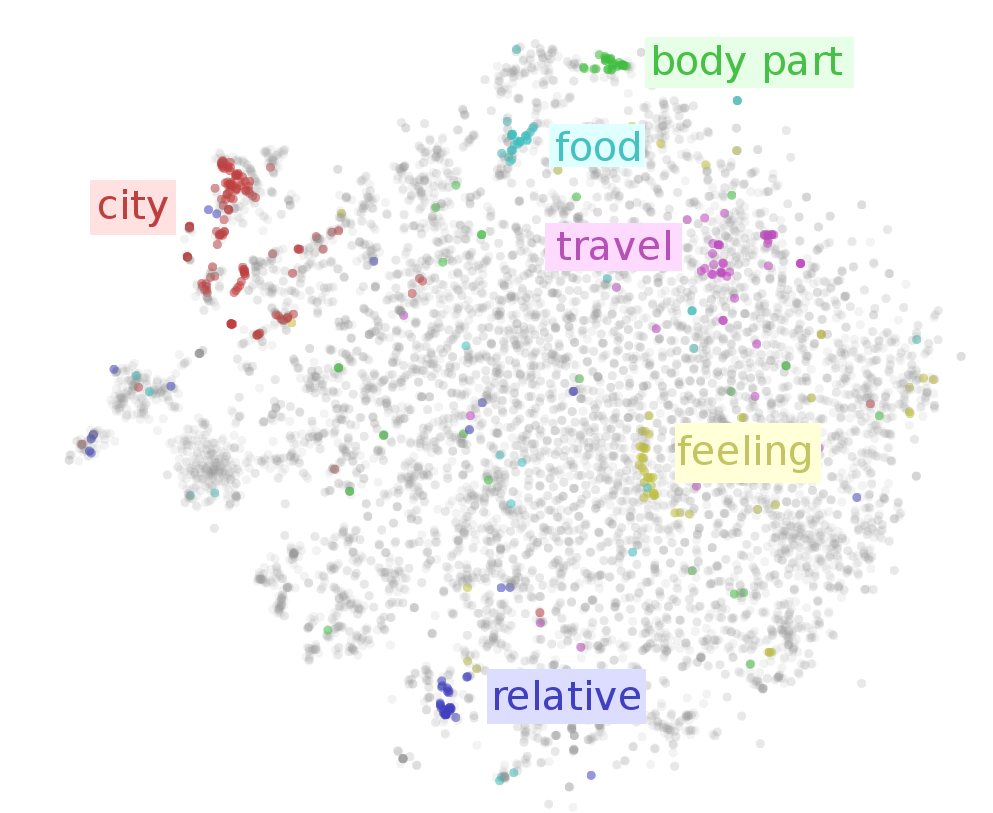
若可以訓練出一個具有代表性詞的向量表示方式,更能讓電腦更了解文章或句子的語意,目前的NLP在進行主要任務之前都會先做word embedding這個動作,這更凸顯了其重要性,BERT的Fine tune其實也是相同的意思,先透過原本的BERT對句子文字進行編碼,再Fine tune下游任務,而且效果也是很好~~
相關的word2vec、doc2vec的原理大家可以參考我之前寫的這篇[2]~不想看也沒關係,應該明天或後天就會寫了XD。目前會以下列的主題為主來介紹詞的相關表示方式:
今天主要只是介紹為何要使用這個技術~明天會開始探討相關的方法~~
參考資料
[1] On word embeddings - Part 1
[2] 讀paper之心得:word2vec 與 doc2vec

