一. BOW
BOW的全名為Bag-of-words,中文是'一袋文字',意思就是將詞都丟進一個袋子裡,所以又稱'詞袋'模型,假設有n個句子(或文章),總共有m個詞,最後會形成nxm的矩陣,如下圖:
每個句子會有m個元素,若有出現在這個句子的詞,該詞的位置的地方會加1,以上圖為例,S1這個句子中出現1次W1,W2出現0次,W3出現3次,以此類推。
雖然這樣的表示方式非常簡便且快速,但缺點也是滿多的:
二. TF-IDF
全名為 Term Frequency - Inverted Document Frequency,其實就是由兩個部分相乘。分別為'Term Frequency(詞頻)'與 'Inverted Document Frequency(逆詞頻)',通常表示文本/句子中的每個詞的重要程度為何,也滿多人利用BOW與TFIDF的方式來表示文本/句子。
詞頻(TF):
這個代表的意思就是詞出現的頻率,越多代表越重要,公式為: 一個詞出現在某一文件的次數/該文件中所有單詞的數量,如下圖,該圖為維基提供的圖,i表示第i個詞,j表示第j篇文章,k表示第j篇文章的所有詞,舉一個例子,若'優秀'在一篇文章文章出現20次,但這篇文章有5000個字,另一篇文章'優秀'出現10次,但這篇只有100個字,所以 tf('優秀', '文件一'): 為 1/250,tf('優秀', '文件二'): 為 1/10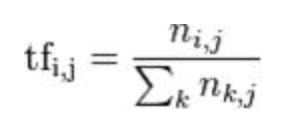
逆詞頻(IDF):
這個是用來制衡詞頻帶來的一些負面影響,像是'的'這個詞出現非常多次而且每篇文章都有,但這個詞本身比不重要。用idf來抑制剛剛的情況,每個「詞」在所有「文件」站的重要性為何,公式如下該圖為維基提供的圖,D表示所有的文件,分母表示這個詞出現在幾篇文章當中,這樣像是'的',他的IDF都很低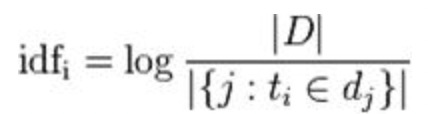
TF-IDF
將上述2者相乘即可~~
明天會利用python來實作TFIDF~

