大家應該聽到爛了,學習率(Learning rate)指的是模型每做完一次 back propagation 後產生的 gradient 再乘上該值來對權重更新,而學習率越大,代表模型權重被更新的變化量也會跟著變大,而這個學習率該設定多少也是個麻煩的超參數,因此也有其他學者從其他面向如不同的優化器 (Optimizers) 來著手研究。但是今天我們比較單純,我們都使用 SGD 作為優化器,但用不同的學習率來觀察訓練的結果。
這次我們使用我自己修改較為精簡版的 alexnet 頭開始訓練,但因為怕 oxford_flowers102 過多的分類,導致模型可能需要非常多個 epochs 來跑,所以改用 tfds 提供的 cifar10 當參考,此資料集只有10個分類,訓練和測試資料集分別是50000和10000張。

from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, BatchNormalization, Activation, MaxPooling2D, Flatten, Dense
def alexnet_modify():
model = Sequential()
model.add(Conv2D(32, (11, 11), padding='valid', input_shape=(227,227,3)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(3, 3)))
model.add(Conv2D(64, (7, 7), padding='valid'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(3, 3)))
model.add(Conv2D(96, (3, 3), padding='valid'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(3, 3)))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(3, 3)))
model.add(Flatten())
model.add(Dense(128))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dense(64))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dense(NUM_OF_CLASS))
return model
而原先 alexnet 的 input size 是227x227,但 cifar10 這個資料集的解析度都是32x32,所以要做 resize 的動作。
第一個實驗,我們將學習率固定為0.1來訓練15個 epochs。
LR = 0.1
model = alexnet_modify()
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
loss: 0.3053 - sparse_categorical_accuracy: 0.8906 - val_loss: 0.8681 - val_sparse_categorical_accuracy: 0.7557
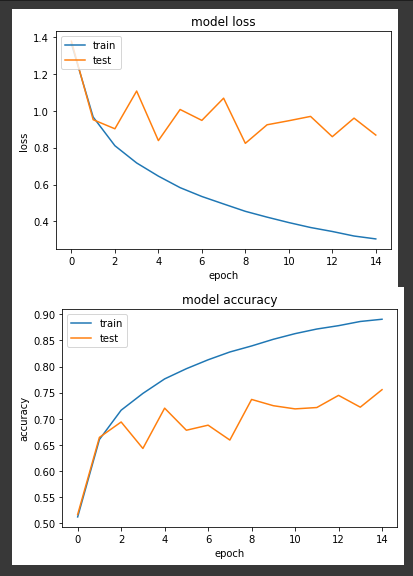
我們可以看到準確度的呈現為震盪向上
第二個實驗將學習率縮小固定為0.001,一樣15個epochs。
LR = 0.001
model = alexnet_modify()
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
loss: 0.8821 - sparse_categorical_accuracy: 0.6962 - val_loss: 0.9843 - val_sparse_categorical_accuracy: 0.6574
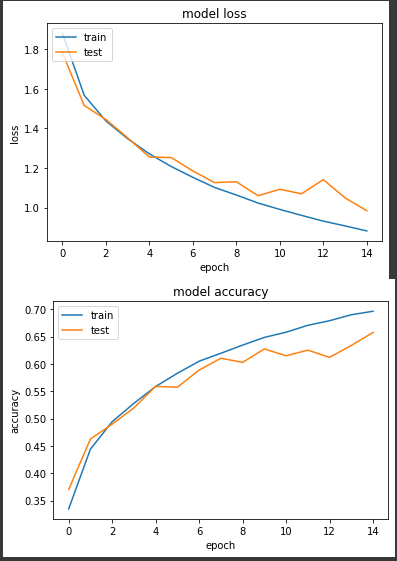
得到的準確度有比較平穩的上升,但同樣的 epoch 最後準確度卻沒有實驗一來得高。
第三個實驗,我們來實驗學習率衰減的做法,簡單來說,當模型一開始還是混亂狀態時,較高的學習率有助於模型快速收斂,但是到了後期過高的學習率會導致模型不對的在各個局部最佳解中跳耀,而很難繼續深入學習,所以我們使用 learning rate decay 這個策略來讓學習率隨著 epoch 數量增加來降低。
LR = 0.1
model = alexnet_modify()
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
def scheduler(epoch):
step = EPOCHS //3
power = (epoch//step)+1
new_lr = LR**(power)
return new_lr
callback = tf.keras.callbacks.LearningRateScheduler(scheduler, verbose=1)
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
callbacks=[callback],
verbose=True)
我們降低的原則分成三個部分,前5個 epochs 我們學習率為0.1,中間5個 epochs 為0.01,最後5個 epochs 學習率降至0.001來實驗。
loss: 0.3802 - sparse_categorical_accuracy: 0.8687 - val_loss: 0.6588 - val_sparse_categorical_accuracy: 0.7798
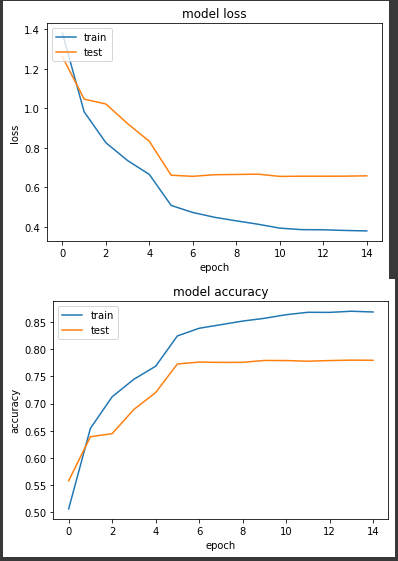
前期準確度穩定上升,但在第6個 epoch 進步趨緩,最終準確度來到77.9%
以上實驗結論來看,使用 learning rate decay 可以讓模型的訓練穩定一些。

