Warm-up 訓練是由這篇 Paper 提出的一種方法,主要的想法是提供模型在正式訓練前,做一個類似暖機的動作,由於模型在初始狀態時,過高的學習率容易導致模型不穩定,所以會先逐步增加學習率倒打壹定的 epochs 後,再進行正常的訓練。有關 Warm-up 較細節的解說可以參考前人的這篇文章。
我們假設 warmup epochs 為5個,學習率為0.1,那麼在前五個 epochs 會得到學習率分別為[0.2, 0.4, 0.6, 0.8, 1.0]的數值,而在 warmup 結束後,學習率又回從[0.1, 0.0999, 0.0996...]開始慢慢遞減。
第一個實驗我們就開始準備 warmup 訓練,warmup 訓練的學習率衰減有兩種策略,分別是 sin-decay 和 gradual-decay,第一個實驗我使用 sin 函數作為學習率衰退。
LR = 0.1
WARMUP_EPOCH = 5
model = alexnet_modify()
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
def scheduler(epoch, lr):
if epoch < WARMUP_EPOCH:
warmup_percent = (epoch+1) / WARMUP_EPOCH
return LR * warmup_percent
else:
return np.sin(lr)
callback = tf.keras.callbacks.LearningRateScheduler(scheduler,verbose=1)
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
callbacks=[callback],
verbose=True)
得出的結果:
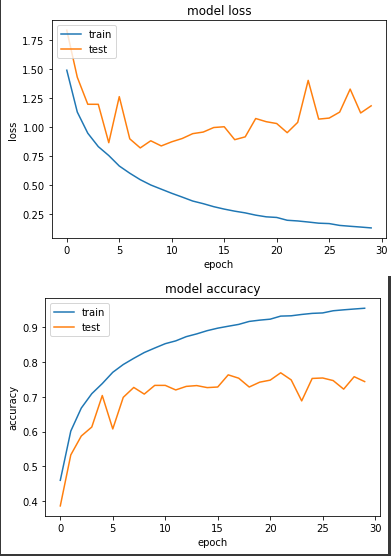
前五個 warm-up:
Epoch 00001: LearningRateScheduler 0.020000000000000004.
loss: 1.4896 - sparse_categorical_accuracy: 0.4602 - val_loss: 1.8346 - val_sparse_categorical_accuracy: 0.3867
Epoch 00002: LearningRateScheduler 0.04000000000000001.
loss: 1.1285 - sparse_categorical_accuracy: 0.6014 - val_loss: 1.4291 - val_sparse_categorical_accuracy: 0.5330
Epoch 00003: LearningRateScheduler 0.06.
loss: 0.9458 - sparse_categorical_accuracy: 0.6674 - val_loss: 1.1956 - val_sparse_categorical_accuracy: 0.5872
Epoch 00004: LearningRateScheduler 0.08000000000000002.
loss: 0.8303 - sparse_categorical_accuracy: 0.7087 - val_loss: 1.1954 - val_sparse_categorical_accuracy: 0.6130
Epoch 00005: LearningRateScheduler 0.1.
loss: 0.7531 - sparse_categorical_accuracy: 0.7377 - val_loss: 0.8639 - val_sparse_categorical_accuracy: 0.7034
最好:
Epoch 00022: LearningRateScheduler 0.09727657241617098.
loss: 0.1944 - sparse_categorical_accuracy: 0.9312 - val_loss: 0.9504 - val_sparse_categorical_accuracy: 0.7686
最終:
Epoch 00030: LearningRateScheduler 0.09606978125185672.
loss: 0.1284 - sparse_categorical_accuracy: 0.9538 - val_loss: 1.1822 - val_sparse_categorical_accuracy: 0.7434
和前一天的實驗三相比,準確度並沒有比較好,前五個 warm-up epoch 也沒有進步的比較快。
第二個實驗使用 gradual-decay ,和第一個不同的是它的衰退呈現指數型。
LR = 0.1
WARMUP_EPOCH = 5
model = alexnet_modify()
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
def scheduler(epoch, lr):
if epoch < WARMUP_EPOCH:
warmup_percent = (epoch+1) / WARMUP_EPOCH
return LR * warmup_percent
else:
return lr**1.0001
callback = tf.keras.callbacks.LearningRateScheduler(scheduler,verbose=1)
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
callbacks=[callback],
verbose=True)
得出的結果:
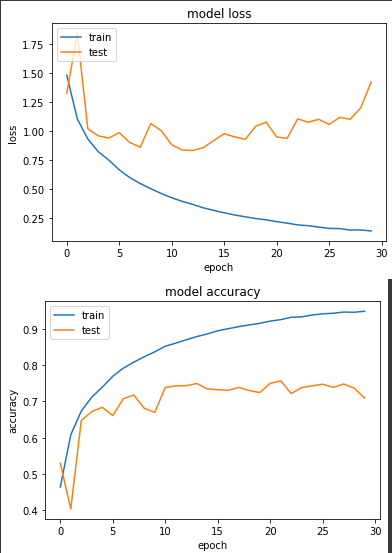
前五個 warm-up:
Epoch 00001: LearningRateScheduler 0.020000000000000004.
loss: 1.4836 - sparse_categorical_accuracy: 0.4637 - val_loss: 1.3275 - val_sparse_categorical_accuracy: 0.5295
Epoch 00002: LearningRateScheduler 0.04000000000000001.
loss: 1.1076 - sparse_categorical_accuracy: 0.6081 - val_loss: 1.8452 - val_sparse_categorical_accuracy: 0.4032
Epoch 00003: LearningRateScheduler 0.06.
loss: 0.9335 - sparse_categorical_accuracy: 0.6735 - val_loss: 1.0221 - val_sparse_categorical_accuracy: 0.6477
Epoch 00004: LearningRateScheduler 0.08000000000000002.
loss: 0.8239 - sparse_categorical_accuracy: 0.7122 - val_loss: 0.9601 - val_sparse_categorical_accuracy: 0.6721
Epoch 00005: LearningRateScheduler 0.1.
loss: 0.7514 - sparse_categorical_accuracy: 0.7395 - val_loss: 0.9415 - val_sparse_categorical_accuracy: 0.6840
最好:
Epoch 00022: LearningRateScheduler 0.0996090197648015.
loss: 0.2075 - sparse_categorical_accuracy: 0.9262 - val_loss: 0.9396 - val_sparse_categorical_accuracy: 0.7571
最終:
Epoch 00030: LearningRateScheduler 0.09942532736309981.
loss: 0.1406 - sparse_categorical_accuracy: 0.9493 - val_loss: 1.4240 - val_sparse_categorical_accuracy: 0.7097
和上面的結果差不多,也仍不及前一天的實驗三。會有這樣的結果也不意外,因為前一天的實驗三,我們的學習率在0.1變成0.01時很剛好的有個明顯loss下降的特徵,而且這邊的 learning rate decay 策略(sin和gradual都是)在 learning rate 的下降幅度都非常小,到第30個 epoch 時,learning rate 仍接近0.1,故我認為 warm-up 策略在多個 epoch 或者是在 warm-up epochs 之後,改用以每個 step 來下降會更為適合!

