昨天我們使用了降低多數樣本 Undersampling 的方式來解決少數樣本的問題,今天我們要用複製少數樣本 Oversampling 方式來實驗看看,當然,這種方式的缺點就是因為複製了少數樣本,等於是每次 epoch 都會重複看到這些複製的資料,對於泛化來說,最終的模型在遇到這些少量樣本的變形時,仍然缺乏良好的預測性。
首先,我們一樣要先準備好訓練資料,原本的訓練樣本分佈如下
{0: 5923,
1: 6742,
2: 5958,
3: 6131,
4: 5842,
5: 5421,
6: 5918,
7: 6265,
8: 5851,
9: 5949}
實驗一:複製60倍
我們針對 6,8,9 這三種標籤複製60倍(其他樣本數在5400~6800都有,這邊複製60倍讓他接近6000)
idx_we_want = list(range(sum(counts[:6]))) + list(range(sum(counts[:7]) ,sum(counts[:7])+counts[7])) # [0,5] + [7,7]
train_label_imbalanced = train_labels_sorted[idx_we_want]
train_images_imbalanced = train_images_sorted[idx_we_want]
idx_we_want = list(range(sum(counts[:6]),sum(counts[:6])+100)) + list(range(sum(counts[:8]),sum(counts[:8])+100)) + list(range(sum(counts[:9]),sum(counts[:9])+100))
train_label_689 = train_labels_sorted[idx_we_want]
train_images_689 = train_images_sorted[idx_we_want]
train_label_689 = train_label_689.repeat(60)
train_images_689 = train_images_689.repeat(60, axis=0)
train_label_imbalanced = np.concatenate((train_label_imbalanced, train_label_689))
train_images_imbalanced = np.concatenate((train_images_imbalanced, train_images_689), axis=0)
train_images_imbalanced, train_label_imbalanced = shuffle(train_images_imbalanced, train_label_imbalanced)
複製完成後,我們將分佈再次印出,確認數量無誤。
unique, counts = np.unique(train_label_imbalanced, return_counts=True)
dict(zip(unique, counts))
再來就可以訓練了
model = tf.keras.Sequential()
model.add(tf.keras.layers.Conv2D(32, [3, 3], activation='relu', input_shape=(28,28,1)))
model.add(tf.keras.layers.Conv2D(64, [3, 3], activation='relu'))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2)))
model.add(tf.keras.layers.Dropout(0.25))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(10))
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
ds_train_im,
epochs=EPOCHS,
validation_data=ds_test,
)
產出:
Epoch 28/30
loss: 0.0108 - sparse_categorical_accuracy: 0.9963 - val_loss: 0.5889 - val_sparse_categorical_accuracy: 0.9024
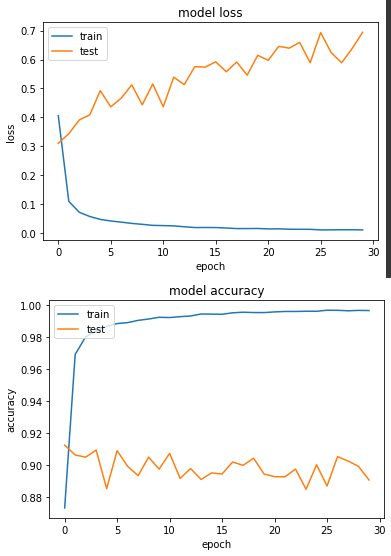
其準確度和昨天的 Undersampling 差不多。
實驗二:複製 30 倍
基於好奇,我想知道 Oversampling 方式如果複製的數量減半,那對模型會有什麼樣的影響?因此和實驗一相比,我將複製的數量縮減到30倍。
idx_we_want = list(range(sum(counts[:6]))) + list(range(sum(counts[:7]) ,sum(counts[:7])+counts[7])) # [0,5] + [7,7]
train_label_imbalanced = train_labels_sorted[idx_we_want]
train_images_imbalanced = train_images_sorted[idx_we_want]
idx_we_want = list(range(sum(counts[:6]),sum(counts[:6])+100)) + list(range(sum(counts[:8]),sum(counts[:8])+100)) + list(range(sum(counts[:9]),sum(counts[:9])+100))
train_label_689 = train_labels_sorted[idx_we_want]
train_images_689 = train_images_sorted[idx_we_want]
train_label_689 = train_label_689.repeat(30)
train_images_689 = train_images_689.repeat(30, axis=0)
train_label_imbalanced = np.concatenate((train_label_imbalanced, train_label_689))
train_images_imbalanced = np.concatenate((train_images_imbalanced, train_images_689), axis=0)
train_images_imbalanced, train_label_imbalanced = shuffle(train_images_imbalanced, train_label_imbalanced)
資料分佈:
{0: 5923,
1: 6742,
2: 5958,
3: 6131,
4: 5842,
5: 5421,
6: 3000,
7: 6265,
8: 3000,
9: 3000}
訓練產出:
Epoch 12/30
loss: 0.0292 - sparse_categorical_accuracy: 0.9910 - val_loss: 0.4467 - val_sparse_categorical_accuracy: 0.9079
準確度一樣有達90%。
以上兩個實驗都表示使用 Oversampling 來訓練對少數樣本的準確度都能有所提升,不過從實驗一和實驗二的 loss 來看,會發現訓練越久,loss 值是越來越大的,這代表發生了過擬合,下一篇會再介紹另一個方法。

