今天要介紹處理不平衡資料的方法叫 SMOTE (Synthetic Minority Oversampling Technique),其原理就是透過將少數樣本以合成的方式來增加,讓資料集變得相對平衡,而這邊的合成方式是什麼?並沒有一定的方式,以一般資料數值分析為例,它從樣本的鄰近區間生成一個近似值來當新的少數樣本。
但是我們這次要介紹的都是圖片相關的分類任務,圖片的話要如何合成樣本呢?沒錯!就是使用 GAN 啦!所以今天的實驗分成兩階段。
本次文章因為主要想實驗利用 GAN 產生的樣本能夠對訓練任務帶來多少效益,所以不會著重在 GAN 的講解上,我們會使用 Conditional GAN ,這種可以指定標籤的生成器作為示範,其 Conditional GAN 的程式碼我會從 Keras 官方 Conditional GAN 教學文件修改來使用,比較不同的地方是 Keras 範例是使用完整的訓練集和測試及產生的,我則是使用6,8,9個只有100筆的不平衡資料來模擬真實情況。
實驗一:用 cGAN (Conditional GAN) 直接跑不平衡資料(6,8,9的樣本只有100筆)
dataset = tf.data.Dataset.from_tensor_slices((train_images_imbalanced, train_label_imbalanced))
def normalize_img(image, label):
return tf.cast(image, tf.float32) / 255., tf.one_hot(label, num_classes)
dataset = dataset.map(
normalize_img, num_parallel_calls=tf.data.experimental.AUTOTUNE)
dataset = dataset.cache()
dataset = dataset.shuffle(1000)
dataset = dataset.batch(128)
dataset = dataset.prefetch(tf.data.experimental.AUTOTUNE)
cond_gan = ConditionalGAN(
discriminator=discriminator, generator=generator, latent_dim=latent_dim
)
cond_gan.compile(
d_optimizer=tf.keras.optimizers.Adam(learning_rate=0.0003),
g_optimizer=tf.keras.optimizers.Adam(learning_rate=0.0003),
loss_fn=tf.keras.losses.BinaryCrossentropy(from_logits=True),
)
cond_gan.fit(dataset, epochs=20)
產出:
Epoch 30/30
g_loss: 0.7804 - d_loss: 0.6826
和 Keras 官網的 loss 比較,因為我們用不平衡資料,導致生成器(g_loss)偏高。
values = [6, 8, 9]
n_values = np.max(values) + 1
one_hot = np.eye(n_values)[values]
for v in one_hot:
fake = np.random.rand(128)
label = np.asarray(v, dtype=np.float32)
fake = np.concatenate((fake,label))
fake = cond_gan.generator.predict(np.expand_dims(fake, axis=0))
fake *= 255.0
converted_images = fake.astype(np.uint8)
converted_images = tf.image.resize(converted_images, (28, 28)).numpy().astype(np.uint8).squeeze()
plt.imshow(converted_images)
plt.show()
生成器產生的1,2,3: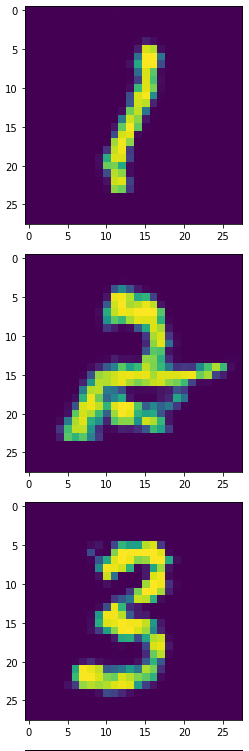
生成器產生的6,8,9: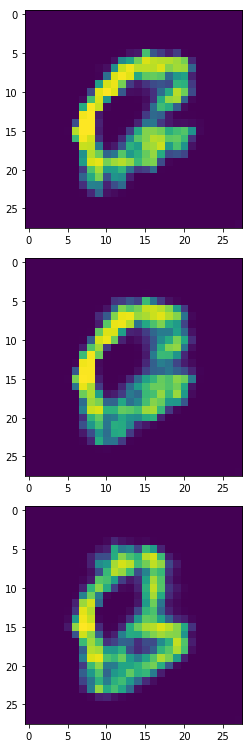
將生成器的6,8,9印出來後,長得很歪...看來我故意挑6,8,9這三組數字是真有搞到模型XD。
雖然這個生成器產生的樣本有些奇怪,但我們仍使用這些長歪的6,8,9來做分類任務,我們產生4900個合成樣本加上原本100個本來的樣本來 Oversampling。
DUP_COUNT=4900
idx_we_want = list(range(sum(counts[:6]))) + list(range(sum(counts[:7]) ,sum(counts[:7])+counts[7])) # [0,5] + [7,7]
train_label_imbalanced = train_labels_sorted[idx_we_want]
train_images_imbalanced = train_images_sorted[idx_we_want]
idx_we_want = list(range(sum(counts[:6]),sum(counts[:6])+100)) + list(range(sum(counts[:8]),sum(counts[:8])+100)) + list(range(sum(counts[:9]),sum(counts[:9])+100))
train_label_689 = train_labels_sorted[idx_we_want]
train_images_689 = train_images_sorted[idx_we_want]
train_label_689_dup = np.asarray([6,8,9]).repeat(DUP_COUNT)
values = [6, 8, 9]
n_values = np.max(values) + 1
one_hot = np.eye(n_values)[values]
train_images_689_dup = np.zeros((DUP_COUNT*3,28,28,1))
for bucket, v in enumerate(one_hot):
for idx in range(DUP_COUNT):
fake = np.random.rand(128)
label = np.asarray(v, dtype=np.float32)
fake = np.concatenate((fake,label))
fake = cond_gan.generator.predict(np.expand_dims(fake, axis=0))
fake *= 255.0
fake = fake.astype(np.uint8)
fake = tf.image.resize(fake, (28, 28)).numpy().astype(np.uint8).squeeze()
train_images_689_dup[bucket*DUP_COUNT+idx,:,:,0] = fake
train_label_imbalanced = np.concatenate((train_label_imbalanced, train_label_689, train_label_689_dup))
train_images_imbalanced = np.concatenate((train_images_imbalanced, train_images_689, train_images_689_dup), axis=0)
train_images_imbalanced, train_label_imbalanced = shuffle(train_images_imbalanced, train_label_imbalanced)
確認一下各個樣本數量是否正確
{0: 5923,
1: 6742,
2: 5958,
3: 6131,
4: 5842,
5: 5421,
6: 5000,
7: 6265,
8: 5000,
9: 5000}
訓練模型。
model = tf.keras.Sequential()
model.add(tf.keras.layers.Conv2D(32, [3, 3], activation='relu', input_shape=(28,28,1)))
model.add(tf.keras.layers.Conv2D(64, [3, 3], activation='relu'))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2)))
model.add(tf.keras.layers.Dropout(0.25))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(10))
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
ds_train_im,
epochs=EPOCHS,
validation_data=ds_test,
)
產出:
Epoch 55/60
loss: 0.0065 - sparse_categorical_accuracy: 0.9977 - val_loss: 0.8658 - val_sparse_categorical_accuracy: 0.8487
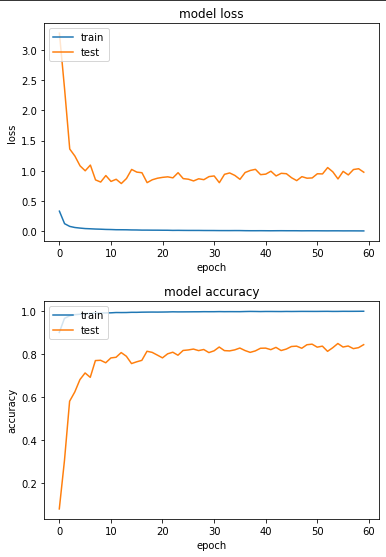
實驗二:用 cGAN (Conditional GAN) 跑 Oversampling 後的不平衡資料
有鑒於實驗一生成器效果不彰,所以這次實驗我嘗試將少量樣本透過 Oversampling 的方式放大50倍,再拿去做 GAN 來生成樣本。
idx_we_want = []
for idx in [0,1,2,3,4,5,7]:
idx_we_want += list(range(sum(counts[:idx]) ,sum(counts[:idx])+5000))
train_label_imbalanced = train_labels_sorted[idx_we_want]
train_images_imbalanced = train_images_sorted[idx_we_want]
idx_we_want = list(range(sum(counts[:6]),sum(counts[:6])+100)) + list(range(sum(counts[:8]),sum(counts[:8])+100)) + list(range(sum(counts[:9]),sum(counts[:9])+100))
train_label_689 = train_labels_sorted[idx_we_want]
train_images_689 = train_images_sorted[idx_we_want]
train_label_689 = train_label_689.repeat(50)
train_images_689 = train_images_689.repeat(50, axis=0)
train_label_imbalanced = np.concatenate((train_label_imbalanced, train_label_689))
train_images_imbalanced = np.concatenate((train_images_imbalanced, train_images_689), axis=0)
train_images_imbalanced, train_label_imbalanced = shuffle(train_images_imbalanced, train_label_imbalanced)
資料分佈,[0,1,2,3,4,5,7]拿前面的5000張,而[6,8,9]則是用前100張 repeat 50次,來產生等量的5000張。
{0: 5000,
1: 5000,
2: 5000,
3: 5000,
4: 5000,
5: 5000,
6: 5000,
7: 5000,
8: 5000,
9: 5000}
GAN 訓練結果:
Epoch 40/40
g_loss: 0.8425 - d_loss: 0.6364
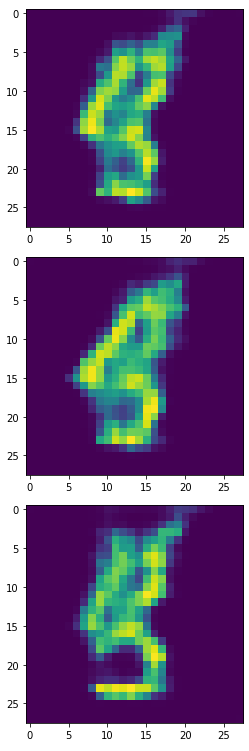
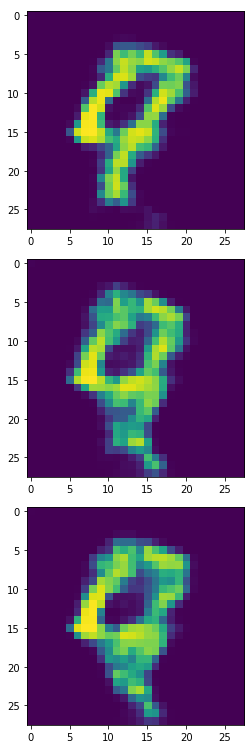
生成器產生的1,2,3:
生成器產生的6,8,9: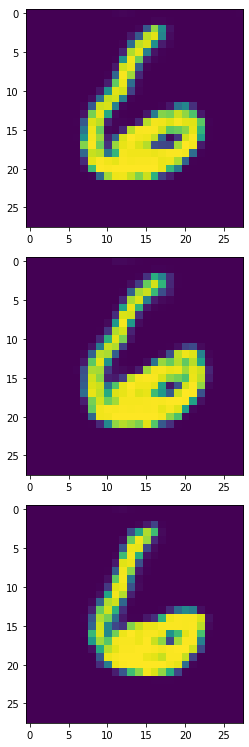
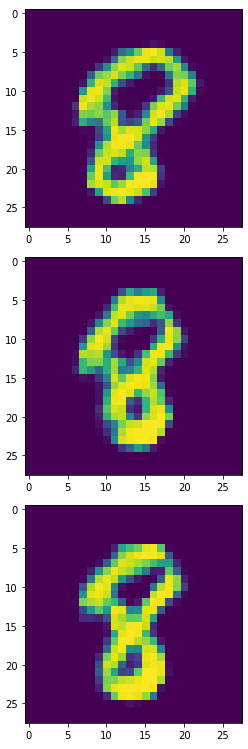
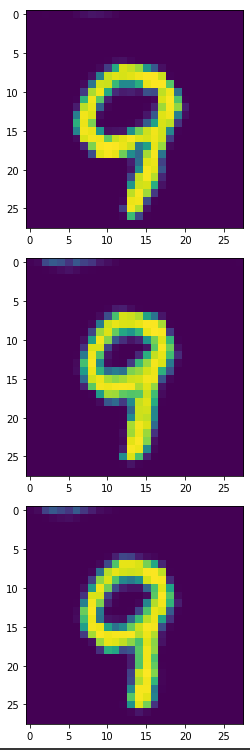
看起來6,8,9比實驗一更完整,我們一樣將此產出4900個合成樣本來訓練模型。
生成:
Epoch 57/60
loss: 0.0060 - sparse_categorical_accuracy: 0.9980 - val_loss: 0.8995 - val_sparse_categorical_accuracy: 0.8453
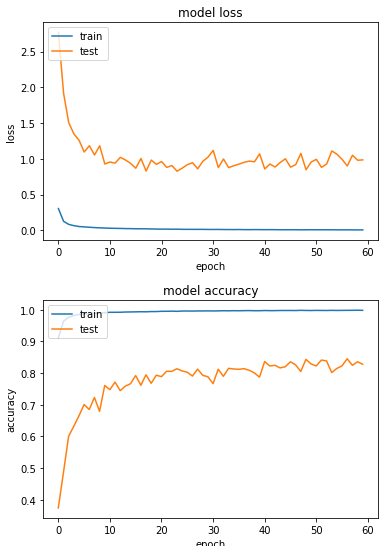
準確度84.5%,可惜並沒有比實驗一來的高。
以上就是這次使用 GAN 來產生合成樣本的實驗。


