一. 神經網路
目前許多強大的NLP Model現在都是以神經網路為基礎的模型,所以需要先了解以及認識神經網路的架構,一個神經網路的圖如下,X經過一個Neuron計算後得到Y,可以想像成是一個 WX = Y 這樣的一個式子: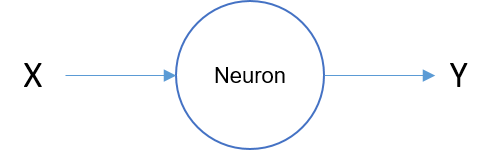
多個Neuron如下,X是一組特徵,2層Layers: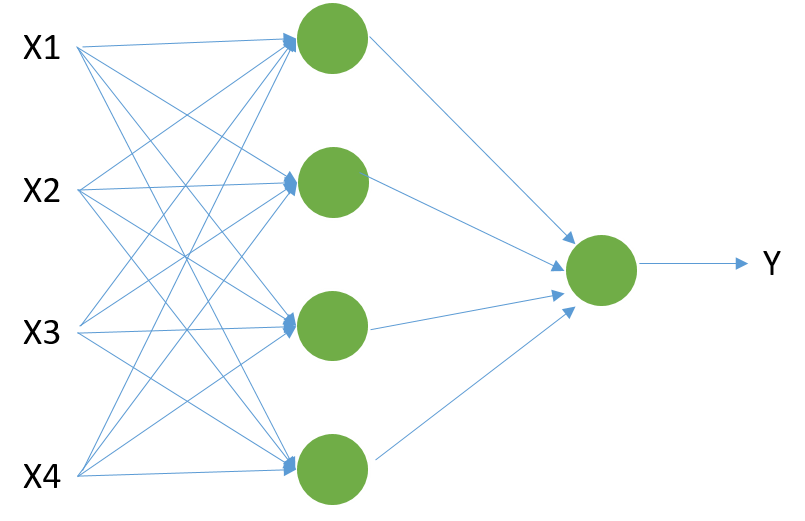
沒錯,神經網路包含了一個輸入層(input layer)、一個以上的隱藏層(hidden layers)、以及一個輸出層(output layer),然後不斷的經過SGD、BP等方法進行裡面的權重學習,至於訓練方式,可以參考李宏毅老師youtube的影片或是coursera上吳恩達老師開的課程,說明的非常詳盡,這邊主要是有模型的概念即可~
下面這張圖是吳恩達老師上課時舉出來深度學習在監督式學習的一些任務: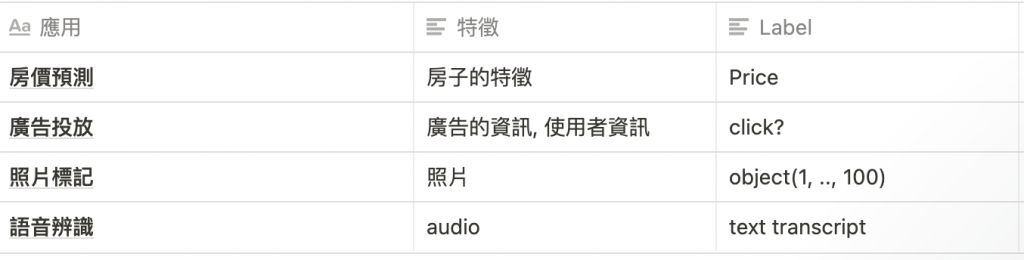
二. Sequence Model
各位可以看到上述一般的NN模型在input data當中是互相獨立的,並無法考慮其他feature帶來的效益。那如果像我們今天要處理的一個句子/文章,由前面的一些模型像是n-gram、word2vec這些模型都考慮了上下文以及過去的文字,畢盡當一個人在閱讀一篇文章或一個句子時,我們會理解每個字的含義,再往下讀對吧正常是不會不管這一點,重新開始思考。人類的思考是連續的,但是上述的神經網絡無法做到這一點所以就有了時序模型(Sequence Model)的出現拉~~
那其中最基本、最典型的model非RNN(遞迴神經網路)莫屬拉~RNN模型算是一種可以無限記憶前面發生什麼事情的神經網路,把每一次輸入所產生的狀態都保存下來,也就是隱藏層,然後再跟著下一次的輸入一起輸出給下一個單元,示意圖如下,圖片來自Coupy的'NLP 深度學習馬拉松':
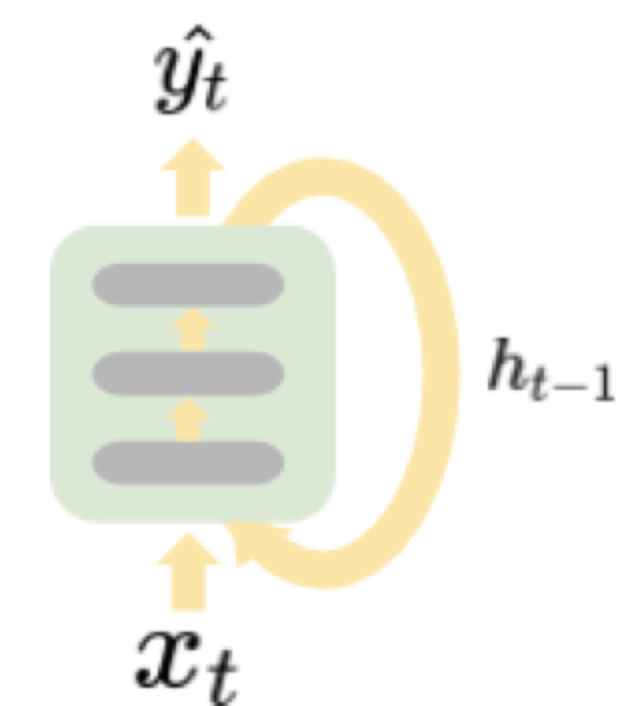
從上面可以知道,X(t)經過一個RNN單元後會產生2個output,一個是Y(t)與h(t),h(t)會在作為下次的input與X(t+1)在經過這個RNN單元,最後output Y(t+1),Y的部分就是看任務需要output幾個,這個明天再介紹時會說到~將上述這張圖展開會如下,圖片一樣來自Coupy的'NLP 深度學習馬拉松':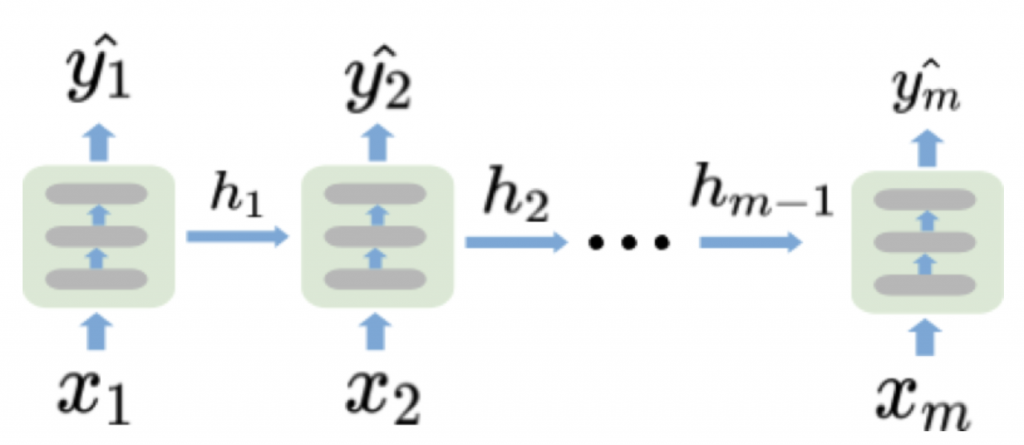
從這些圖片就可以了解h(t)就是這個時間點的狀態,將他加入下個時間點的輸入X(t+1),讓後面的資訊都可以考慮到前面的資訊,這就是RNN~~
明天會開始說明LSTM/GRU這些RNN的變形~~

