一. RNN會造成的問題
前一天看過了RNN的訓練流程,他是非常長一串,若今天我們需訓練一個非常長的文本訓練 RNN 時,會進行非常多次的反向傳播,這在讓我們計算梯度時會造成梯度消失(Gradient Vanishing)與梯度爆炸(Gradient Exploding)的問題。
那LSTM解決了上述的這個問題,它不會將前面的資訊都記錄下來,而是會選擇性紀錄前面的資訊,那至於LSTM是如何做到的,就是因為他有一個遺忘門的機制,讓他決定哪些資訊要保留,哪些要遺忘!
二. LSTM
LSTM全名為Long short-term memory(長短期記憶),其實整體上,LSTM與RNN的流程是一樣的,都是在向前傳播的時候處理資訊,但LSTM的架構與運算方式不同,如下圖,圖片一樣來自Coupy的'NLP 深度學習馬拉松':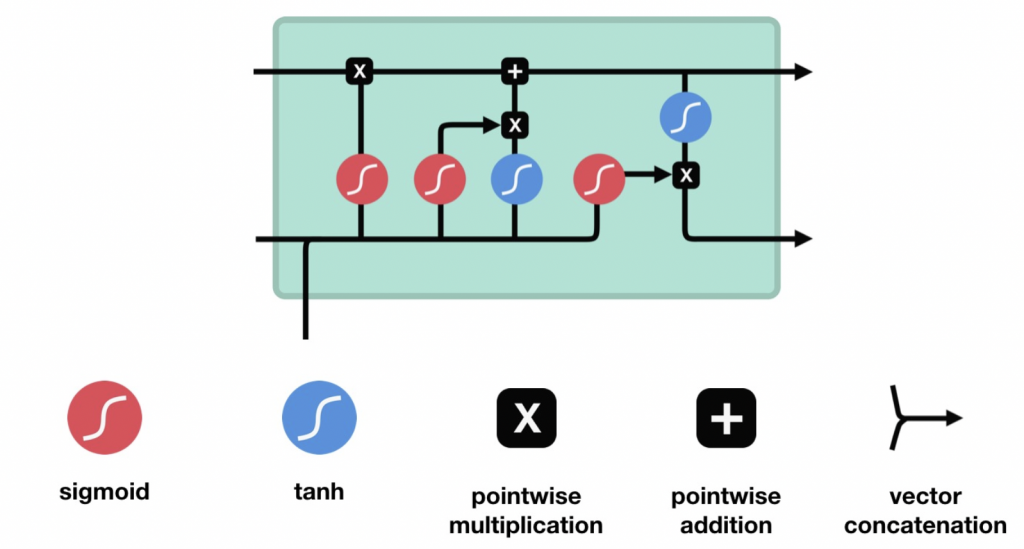
在計算時會決定哪些資訊該保留哪些該捨去,接下來來說明LSTM的三大門: 遺忘門、輸入門、輸出門
遺忘門,前面一個狀態h(t-1)會與現在的input X(t) 一起決定這邊要不要保留(這邊是用sigmoid來決定保留的%數,因為sigmoid是輸出0-1之間的數字),操作流程如下: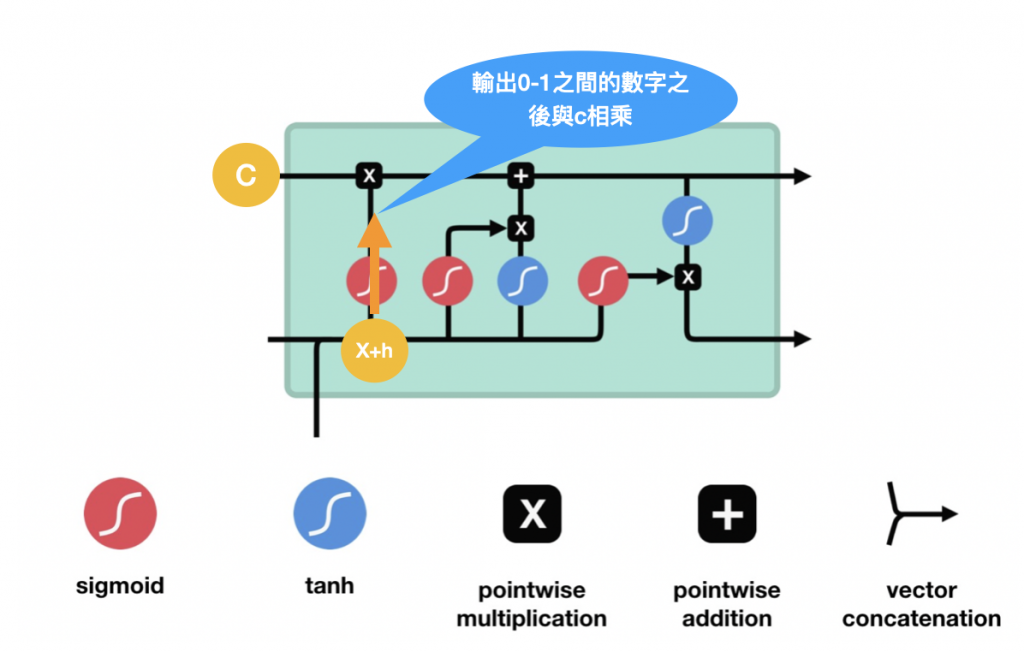
輸入門,用於更新單元現在的狀態。一樣先通過sigmoid輸出0-1之間的數字調整輸出值,0表示不重要,1表示重要。也將這動作傳輸給Tanh函數,最後將這兩個結果相乘,這個動作就是在說 Sigmoid的值來權衡Tanh輸出中哪些信息哪些是重要的,操作流程如下: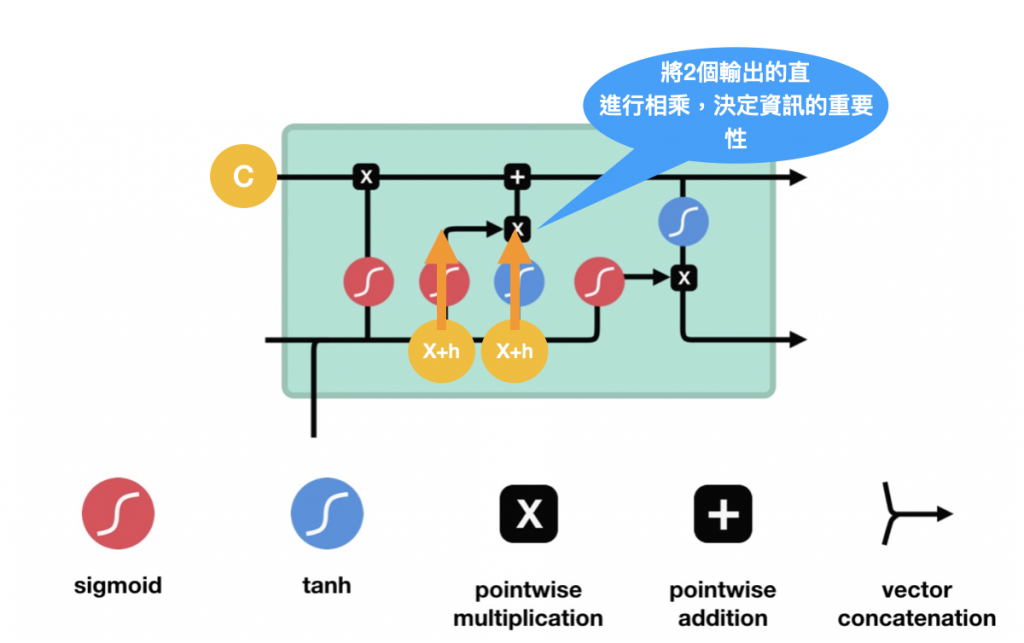
輸入門輸出後,C的值也可以開始跟著變動,往前進,會先乘上遺忘門輸出的值,如果是0表示前面的資訊不重要了可以捨棄,更新完C後C就可以送給下一個LSTM單元繼續做一樣的事囉~如下圖: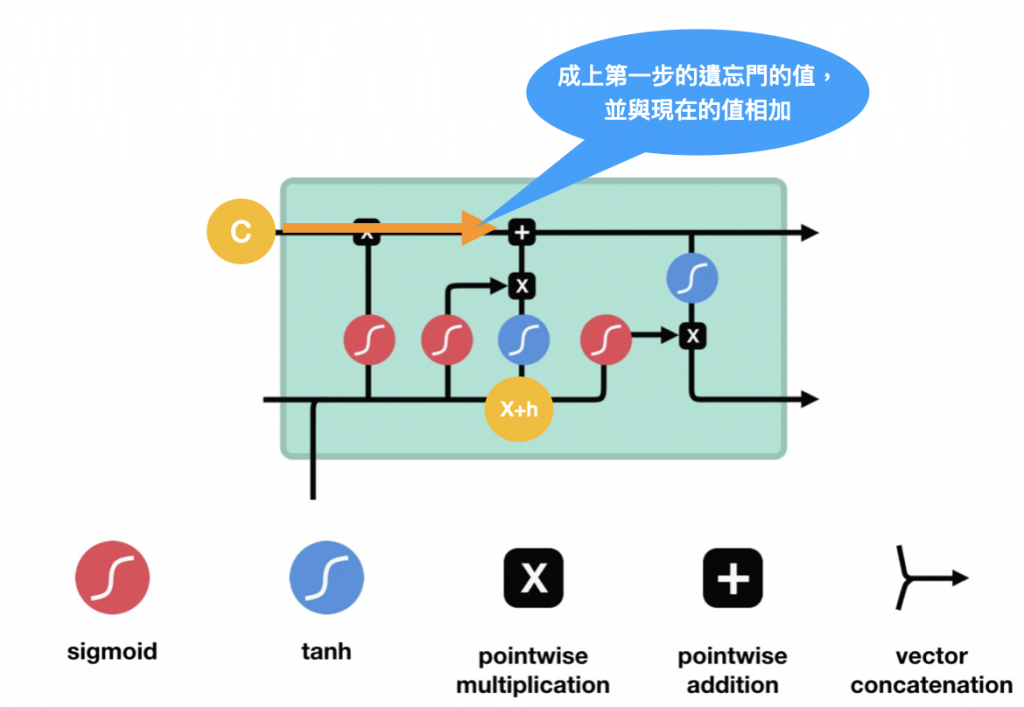
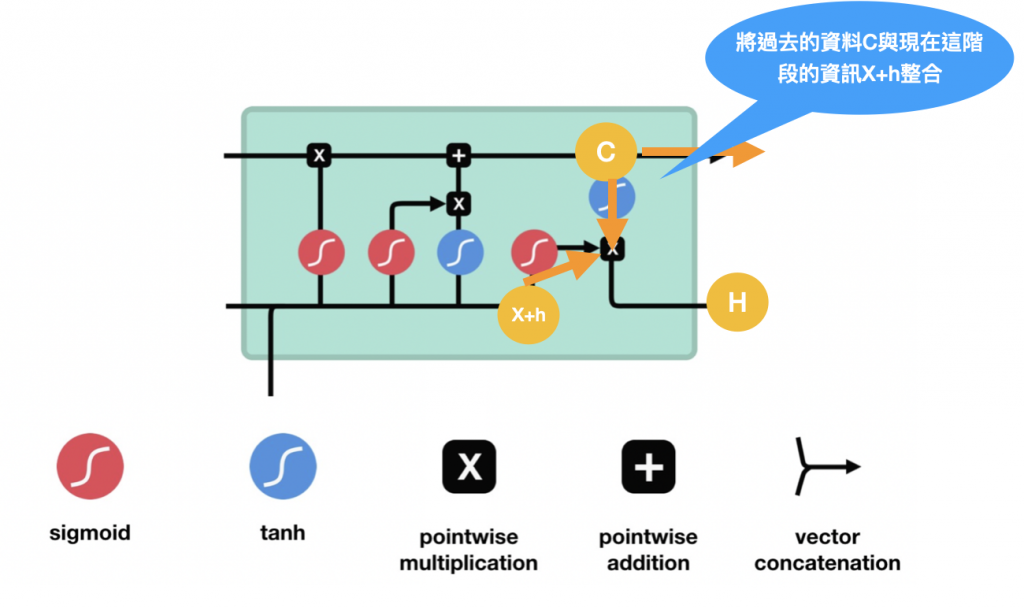
以上就是LSTM的操作流程~明天會再說明GRU的部分~~

