有興趣知道特徵臉方法 (Eigenfaces)的基本原理 - 主成分分析 (PCA),推薦你看看這篇生動也有趣的介紹
使用特徵臉方法 (Eigenfaces)來做人臉辨識實際上是:
用文字說明,不如實際操作。
face_recognition與dataset,分別用來存放人臉辨識的程式碼與資料集pip freeze應該跟我一樣:cmake==3.21.2
cycler==0.10.0
dlib==19.22.1
imageio==2.9.0
imutils==0.5.4
joblib==1.0.1
kiwisolver==1.3.2
matplotlib==3.4.3
networkx==2.6.3
numpy==1.21.2
opencv-contrib-python==4.5.3.56
Pillow==8.3.2
pyparsing==2.4.7
python-dateutil==2.8.2
PyWavelets==1.1.1
scikit-image==0.18.3
scikit-learn==0.24.2
scipy==1.7.1
six==1.16.0
threadpoolctl==2.2.0
資料集部分我們使用加州理工學院提供的人臉測試資料集。從這裡下載CALTECH臉部資料集;解壓縮後,裡面是450張不同人的正面照 此連結已失效,請使用其他網路上Open的人臉正面資料庫
這450張圖片請依照下面的順序依次建立子資料夾並分類 (資料夾名稱只是用做識別,你可以改成喜歡的名稱):
- man_1:image_0001.jpg ~ image_0021.jpg
- man_2:image_0022.jpg ~ image_0041.jpg
- man_3:image_0042.jpg ~ image_0046.jpg
- man_4:image_0047.jpg ~ image_0068.jpg
- woman_1:image_0069.jpg ~ image_0089.jpg
- man_5:image_0090.jpg ~ image_0112.jpg
- woman_2:image_0113.jpg ~ image_0132.jpg
- man_6:image_0133.jpg ~ image_0137.jpg
- man_7:image_0138.jpg ~ image_0158.jpg
- man_8:image_0159.jpg ~ image_0165.jpg
- woman_3:image_0166.jpg ~ image_0170.jpg
- woman_4:image_0171.jpg ~ image_0175.jpg
- woman_5:image_0176.jpg ~ image_0195.jpg
- man_9:image_0196.jpg ~ image_0216.jpg
- man_10:image_0217.jpg ~ image_0241.jpg
- man_11:image_0242.jpg ~ image_0263.jpg
- man_12:image_0264.jpg ~ image_0268.jpg
- woman_6:image_0269.jpg ~ image_0287.jpg
- man_13:image_0288.jpg ~ image_0307.jpg
- man_14:image_0308.jpg ~ image_0336.jpg
- woman_7:image_0337.jpg ~ image_0356.jpg
- woman_8:image_0357.jpg ~ image_0376.jpg
- man_15:image_0377.jpg ~ image_0398.jpg
- man_16:image_0404.jpg ~ image_0408.jpg
- woman_9:image_0409.jpg ~ image_0428.jpg
- woman_10:image_0429.jpg ~ image_0450.jpg
特別注意: 照片中399 ~ 403由於樣本數太少或是非一般照片照,所以排除在我們這次的資料集之外;請將這些照片與非jpg格式的檔案都刪除。
將整理好的資料集放到專案目錄下的dataset目錄下。這時你的專案結構應該會長這樣: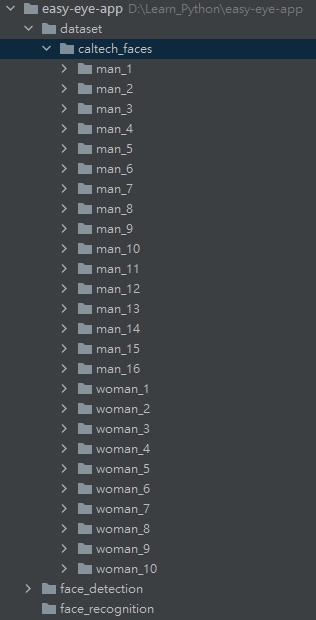
首先我們需要先撰寫將資料集載入的程式碼。在dataset目錄下新建一個檔案load_dataset.py,並新增下面的程式碼:
# 匯入必要套件
import ntpath
import os
import pickle
from itertools import groupby
import cv2
import numpy as np
from imutils import paths
# 匯入人臉偵測方法 (你可以依據喜好更換不同方法)
from face_detection.opencv_dnns import detect
def images_to_faces(input_path):
"""
將資料集內的照片依序擷取人臉後,轉成灰階圖片,回傳後續可以用作訓練的資料
:return: (faces, labels)
"""
# 判斷是否需要重新載入資料
data_file = ntpath.sep.join([ntpath.dirname(ntpath.abspath(__file__)), "faces.pickle"])
if os.path.exists(data_file):
with open(data_file, "rb") as f:
(faces, labels) = pickle.load(f)
return (faces, labels)
# 載入所有圖片
image_paths = list(paths.list_images(input_path))
# 將圖片屬於"哪一個人"的名稱取出 (如:man_1, man_2,...),並以此名稱將圖片分群
groups = groupby(image_paths, key=lambda path: ntpath.normpath(path).split(os.path.sep)[-2])
# 初始化結果 (faces, labels)
faces = []
labels = []
# loop我們分群好的圖片
for name, group_image_paths in groups:
group_image_paths = list(group_image_paths)
# 如果樣本圖片數小於15張,則不考慮使用該人的圖片 (因為會造成辨識結果誤差);可以嘗試將下面兩行註解看準確度的差異
if (len(group_image_paths)) < 15:
continue
for imagePath in group_image_paths:
# 將圖片依序載入,取得人臉矩形框
img = cv2.imread(imagePath)
rects = detect(img)
# loop各矩形框
for rect in rects:
(x, y, w, h) = rect["box"]
# 取得人臉ROI (注意在用陣列操作時,順序是 (rows, columns) => 也就是(y, x) )
roi = img[y:y + h, x:x + w]
# 將人臉的大小都轉成50 x 50的圖片
roi = cv2.resize(roi, (50, 50))
# 轉成灰階
roi = cv2.cvtColor(roi, cv2.COLOR_BGR2GRAY)
# 更新結果
faces.append(roi)
labels.append(name)
# 將結果轉成numpy array,方便後續進行訓練
faces = np.array(faces)
labels = np.array(labels)
with open(data_file, "wb") as f:
pickle.dump((faces, labels), f)
return (faces, labels)
接下來到face_recognition目錄下新增eigenfaces.py檔案:
import ntpath
import sys
# resolve module import error in PyCharm
sys.path.append(ntpath.dirname(ntpath.dirname(ntpath.abspath(__file__))))
# 匯入必要套件
import argparse
import os
import pickle
import time
import cv2
import imutils
import numpy as np
from imutils import build_montages
from matplotlib import pyplot as plt
from skimage.exposure import rescale_intensity
from sklearn.decomposition import PCA
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.svm import SVC
from dataset.load_dataset import images_to_faces
def main():
# 初始化arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--input", type=str, required=True, help="the input dataset path")
ap.add_argument("-n", "--components", type=int, default=25, help="number of components")
args = vars(ap.parse_args())
data_file = ntpath.sep.join([ntpath.dirname(ntpath.dirname(ntpath.abspath(__file__))), args["input"], "data.pickle"])
print("[INFO] loading dataset....")
if not os.path.exists(data_file):
(faces, labels) = images_to_faces(args["input"])
with open(data_file, "wb") as f:
pickle.dump((faces, labels), f)
else:
with open(data_file, "rb") as f:
(faces, labels) = pickle.load(f)
print(f"[INFO] {len(faces)} images in dataset")
# 進行主成分分析時需要將資料轉成一維陣列
pca_faces = np.array([face.flatten() for face in faces])
# 將名稱從字串轉成整數 (在做訓練時時常會用到這個方法:label encoding)
le = LabelEncoder()
labels = le.fit_transform(labels)
# 將資料拆分訓練用與測試用;測試資料佔總資料1/4 (方便後續我們判斷這個方法的準確率)
split = train_test_split(faces, pca_faces, labels, test_size=0.25, stratify=labels, random_state=9527)
(oriTrain, oriTest, trainX, testX, trainY, testY) = split
print("[INFO] creating eigenfaces...")
pca = PCA(svd_solver="randomized", n_components=args["components"], whiten=True)
start = time.time()
pca_trainX = pca.fit_transform(trainX)
end = time.time()
print(f"[INFO] computing eigenfaces for {round(end - start, 2)} seconds")
# 確認使用的主成分可以解釋多少資料的變異
cum_ratio = np.cumsum(pca.explained_variance_ratio_)
plt.plot(cum_ratio)
plt.xlabel("number of components")
plt.ylabel("cumulative explained variance")
plt.draw()
plt.waitforbuttonpress(0)
# 來用"圖像"看一下PCA的結果
vis_images = []
for (i, component) in enumerate(pca.components_):
component = component.reshape((50, 50))
component = rescale_intensity(component, out_range=(0, 255))
component = np.dstack([component.astype("uint8")] * 3)
vis_images.append(component)
montage = build_montages(vis_images, (50, 50), (5, 5))[0]
montage = imutils.resize(montage, width=250)
mean = pca.mean_.reshape((50, 50))
mean = rescale_intensity(mean, out_range=(0, 255)).astype("uint8")
mean = imutils.resize(mean, width=250)
cv2.imshow("Mean", mean)
cv2.imshow("Components", montage)
cv2.waitKey(0)
# 建立SVM模型來訓練
model = SVC(kernel="rbf", C=10.0, gamma=0.001, random_state=9527)
model.fit(pca_trainX, trainY)
# 驗證模型的準確度 (記得將測試資料轉成PCA的格式)
pca_testX = pca.transform(testX)
predictions = model.predict(pca_testX)
print(classification_report(testY, predictions, target_names=le.classes_))
# Optional: 你也可以直接用OpenCV內建的模型來訓練;下面的程式碼可以取代前面的SVM模型訓練
# recognizer = cv2.face_EigenFaceRecognizer().create(num_components=args["components"])
# recognizer.train(trainX, trainY)
# predictions = []
# for i in range(0, len(testX)):
# (prediction, _) = recognizer.predict(testX[i])
# predictions.append(prediction)
# print(classification_report(testY, predictions, target_names=le.classes_))
# 隨機挑選測試資料來看結果
idxs = np.random.choice(range(0, len(testY)), size=10, replace=False)
for i in idxs:
predName = le.inverse_transform([predictions[i]])[0]
actualName = le.classes_[testY[i]]
face = np.dstack([oriTest[i]] * 3)
face = imutils.resize(face, width=250)
cv2.putText(face, f"pred:{predName}", (5, 25), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 255, 0), 2)
cv2.putText(face, f"actual:{actualName}", (5, 60), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 0, 255), 2)
print(f"[INFO] prediction: {predName}, actual: {actualName}")
cv2.imshow("Face", face)
cv2.waitKey(0)
plt.close()
if __name__ == '__main__':
main()
都完成後,請在terminal內輸入python face_recognition/eigenfaces.py -i dataset/caltech_faces就可以測試程式看看結果了!
前25個主成分累積變異值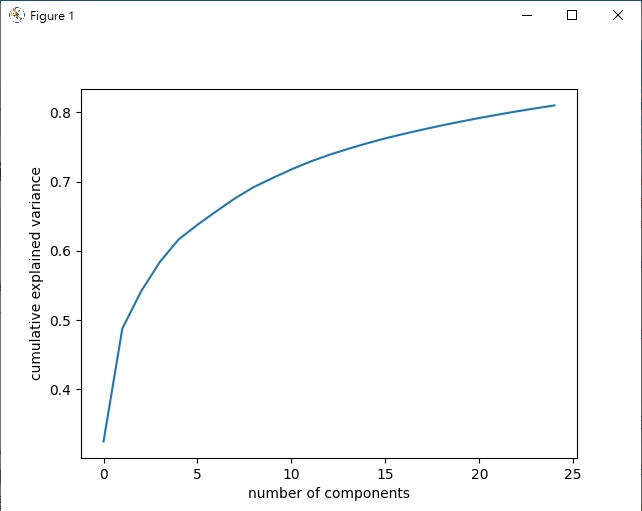
PCA結果圖像化的樣子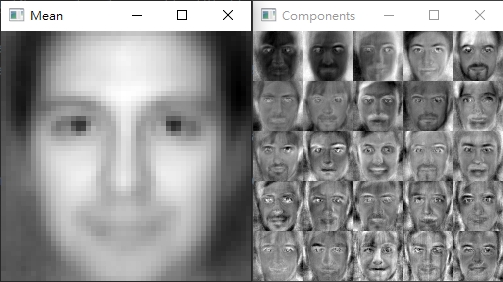
辨識結果錯誤的例子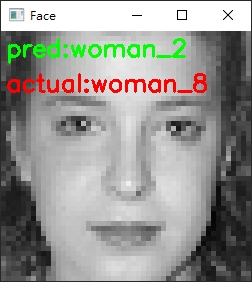
辨識結果正確的例子
這一篇文章的內容比較多,程式碼的部分也比較複雜,因此在實作的過程可以參考下面一節的結論一起觀看。
特徵臉方法時,需要將圖片都轉為灰階 -> 確認值的範圍都相同 -> 轉成一維陣列
eigenfaces.py程式碼的第53-58行,我們實際用累積圖來看到PCA方法的主成分前25個已經可以表達原始資料的80%左右 (我們圖像實際上是50 * 50 = 2500個數值的陣列)
-n來看看不一樣數量的主成分辨識結果有什麼不同eigenfaces.py程式碼的第60 - 76行,我們用圖像實際來看PCA前25個主成分用畫面看是什麼感覺;這裡你可以看到平均值Mean的圖像看起來就像一個"模板型的人臉",而各主成分Components中,顏色越白的代表在真實圖片中,變異性越大;可以看出大部分在眼睛、眉毛、鼻子、嘴唇部分比較沒有太大的變化特徵臉方法來辨識臉部,會需要圖片盡可能都是正面照;因為我們在處理圖片時,都需要將其轉成一維陣列,其實這正代表者即使臉部有些微轉動或是非正面臉,都會使得後面在透過SVM模型訓練時準確度大幅下降使用特徵臉方法大概是最直覺也很簡單的人臉識別方法了,主要使用的方法主成分分析(PCA)在應用上也不局限於圖像而已 (還沒看過這篇介紹的建議看一下)
就這樣,接著我們明天會介紹在特徵臉方法後,稍微強一點的人臉識別 - 局部二值方法
程式碼傳送門
請問您在load_dataset.py 這個檔案裡打的reload是有額外插件嗎,因為我會跳出錯誤
沒有喔,純粹撰寫時打錯字,忘了更新XD
文章內容已更新,感謝糾錯 
P.S. 如果需要最新版本可以至文末Github連結查看喔
CALTECH_faces 資料集不能下載了,請問還有其他好用的照片資料集嗎?(因為要每個人至少15張的資料集比較少)謝謝
原來已經失效了…謝謝回報
人臉資料庫在網路上搜尋還蠻容易找到的(人臉 數據集)
(Yale Face Database,BioID Face Database,IMDB wiki…)
感謝作者 超級詳細清楚的教學!!
分享檔案連結:
https://data.caltech.edu/records/6rjah-hdv18
另外,我是直接請 ChatGPT 用 python 幫我加工
直接上傳結果分類截圖,稍微說明一下即可
不然我編輯資料夾大概要5分鐘...

