如同前面所說,資料模型需要運用到實際環境中才會發揮價值
延續之前模型的初始條件,如果想使用資料來輔助決策,最重要的就是要釐清想解決的問題是什麼。
常見的問題像是:
「明天會不會下雨?」
「使用者會不會點擊?」
「使用者是不是本人?」
面對這些問題,其實在技術上都有不只一種方式來回答。這時候就是要根據目前持有的前三層的資料品來決定可行的解決方案。
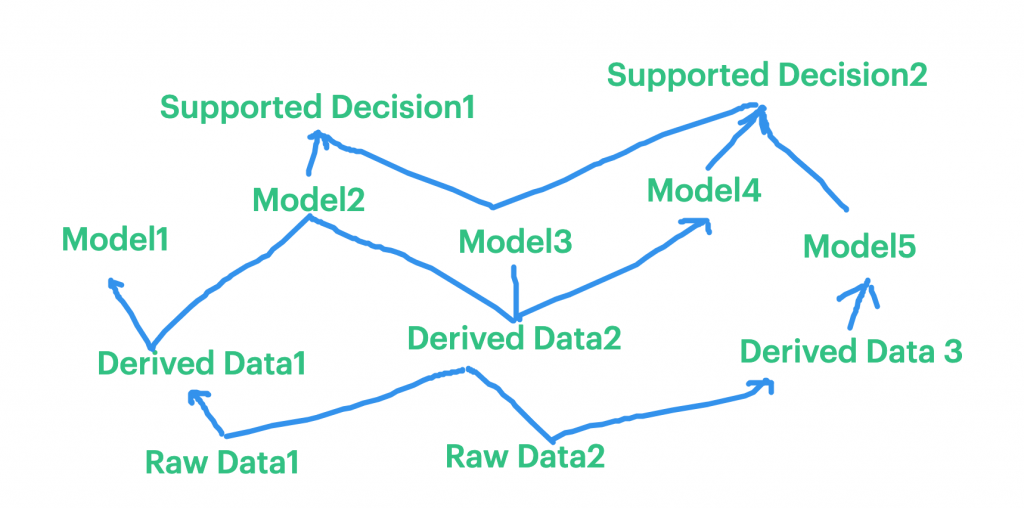
設計上來說需要依序盤點是不是有足夠的資料來支撐解決方案。在這個過程會把前幾個資料產品的設計流程從頭順過一次,確保資料在每個階段都有可能搭得起來。
將以上事情搞定之後,需要思考如何用合適的方式將結果呈現給需求端來「輔助決策」。
以下雨的例子來說的話:
實作時基本上就是把設計階段時盤點的資料產品依序實作。各自資料產品實作要點可以參考前面幾篇。
針對輔助決策在實作上不外乎就是:
讓使用者可以用簡單的方式取用最後結果。
部署階段一樣除了考量前幾層的資料產品外呢,需要特別注意整個輔助決策產品的 SLA(Service Level Aggrement)。單一產品要做到 99.9% 的 uptime 都不是簡單的事,何況資料產品層層疊疊,從原始資料一路疊到 Model 和 API,每個單一產品都需要有極高的穩定程度,才有辦法讓最終的輔助決策系統達到 99.9% 的穩定度。
評估階段基本上就在處理兩個層面問題:
信度(Validaty):結果的準確率是否足夠?
不同的問題可以被接受的準確率(或錯誤率)是不同的。像是 Iphone 人臉辨識解鎖你絕對不希望有任何錯誤可能;但是像颱風路徑預測,就可以接受相對較大的誤差。
效度(reliability):結果是否穩定、能夠重複實現?就像之前談到的,模型不能只有上線那天好,而是希望能夠穩定發揮效果;系統面的穩定也是一樣,我們會希望每天資料都可以順利處理、不會因為突然的過量使用者造成系統停機或當掉。
越上層的資料產品迭代起來也就越麻煩,下層產品的任何迭代都會影響到上層產品。可以很簡單的想像這個情境:當原始資料更新格式,卻沒有被妥當處理時,就會連帶影響後續的加工資料、模型、以及輔助決策。更麻煩的事情,每個下層資料產品都可能會被多個上層資料產品使用,當有需求會改動到下層資料產品時,都需要特別小心意想不到的 side effect。
https://www.atlassian.com/incident-management/kpis/sla-vs-slo-vs-sli
http://www2.nkust.edu.tw/~tsungo/Publish/15%20Validity%20and%20reliability.pdf

