一. LSTM的問題
LSTM雖然非常強大,但LSTM也是有一個問題,就是計算時間較久導致執行速度較慢,畢竟它需要三個門都計算過~時間就是金錢,所以就產生了GRU(Gated Recurrent Unit),加速計算時間以及減少計算空間。
二. GRU
GRU全名為Gated Recurrent Unit,中文不太會翻譯XD,整體架構上它比LSTM少了一個門,讓他的運算時間少了許多,架構如下,圖片一樣來自於Coupy的'NLP 深度學習馬拉松':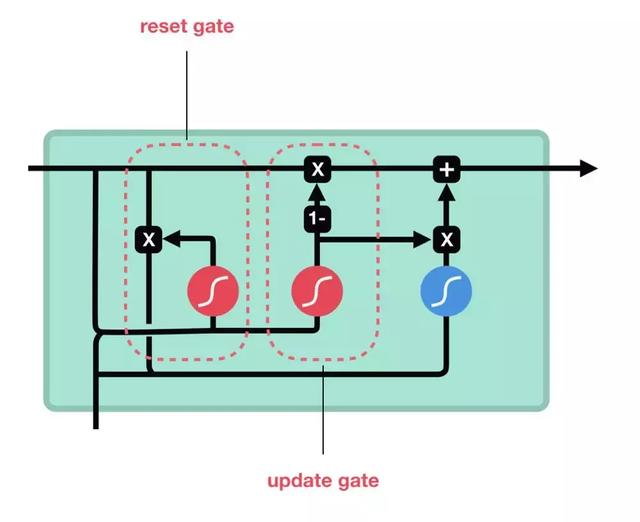
這邊可以想成GRU將LSTM的三個門變成了一個'重設門'與一個'更新門',下面稍微說明一下這兩個門的目的:
然後最重要的是GRU的輸出沒有C(cell state)只有h(hidden state)~
但其實GRU與LSTM效果沒差很多~就是差在計算時間與空間,所以之前也看到有人在網路上說過類似: 通常可以利用LSTM作為最初的選擇,但當你有非常龐大的訓練資料時,可以考慮使用GRU。
GRU大概說明到這~
明天預計帶過一些這些model的應用情境,然後會利用LSTM實作POS任務

