是這樣的,我曾經在新聞上看到說羅東的農夫有種植的西瓜被偷,
我在想除了監視器以外,還有沒有甚麼方法可以防止農作物被偷。
後來也有在tensorflow的開發日誌上看到,
一些環保人士在雨林中放置一些舊型的手機,
在裡面運行了音訊辨識的模型,只要聽到了筏木機的聲音,
就會進行通知,防止雨林被偷筏木。
現在可以來看看tensorflow官網的攻略,
採用已經訓練好的YAMNet模型:
https://www.tensorflow.org/tutorials/audio/transfer_learning_audio?hl=zh_tw
那我們可以看一下,已經訓練好的模型可以辨識那些聲音:
https://github.com/tensorflow/models/blob/master/research/audioset/yamnet/yamnet_class_map.csv
安裝音訊資訊處理套件:
pip install tensorflow_io
載入套件:
import os
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from IPython import display
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_io as tfio
利用tf_hub載入YAMNet模型:
yamnet_model_handle = 'https://tfhub.dev/google/yamnet/1'
yamnet_model = hub.load(yamnet_model_handle)
下載測試音訊:
testing_wav_file_name = tf.keras.utils.get_file('miaow_16k.wav','https://storage.googleapis.com/audioset/miaow_16k.wav',
cache_dir='./',
cache_subdir='test_data')
print('***********')
print(testing_wav_file_name)
print('***********')
將測試的wav檔案轉換成tensor格式,讓模型可以辨別。
@tf.function
def load_wav_16k_mono(filename):
""" Load a WAV file, convert it to a float tensor, resample to 16 kHz single-channel audio. """
file_contents = tf.io.read_file(filename)
wav, sample_rate = tf.audio.decode_wav(
file_contents,
desired_channels=1)
wav = tf.squeeze(wav, axis=-1)
sample_rate = tf.cast(sample_rate, dtype=tf.int64)
wav = tfio.audio.resample(wav, rate_in=sample_rate, rate_out=16000)
return wav
testing_wav_data = load_wav_16k_mono(testing_wav_file_name)
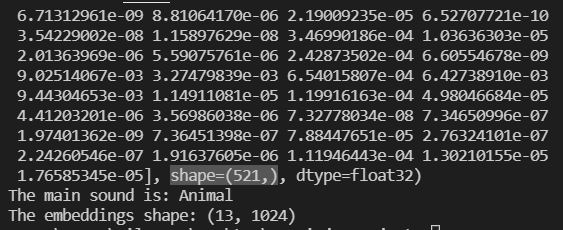
我們先將模型跑出的結果(521種特徵,一維的陣列,shape=(521,)),以list對應label的名稱。
class_map_path = yamnet_model.class_map_path().numpy().decode('utf-8')
class_names =list(pd.read_csv(class_map_path)['display_name'])
for name in class_names[:20]:
print(name)
print('...')
我們可以查看,最有可能的聲音類別:
scores, embeddings, spectrogram = yamnet_model(testing_wav_data)
class_scores = tf.reduce_mean(scores, axis=0)
print(class_scores)
top_class = tf.argmax(class_scores)
inferred_class = class_names[top_class]
print(f'The main sound is: {inferred_class}')
print(f'The embeddings shape: {embeddings.shape}')
那我們也可以用numpy的argpartition來看class_scores最有可能的聲音類別
參考:
https://stackoverflow.com/questions/6910641/how-do-i-get-indices-of-n-maximum-values-in-a-numpy-array
我們可以使用in來查看,小偷應該是開卡車或是車子來偷農作物的吧:
alert_detect_sound = ['Car' , 'Car alarm' ,'Car passing by' ,'Truck']
if inferred_class in alert_detect_sound:
print('進行通知 有小偷')
假設你遇到下面的錯誤:
可以把tf_hub底下的資料夾砍了,再重新執行一次程式。
是由於tf_hub載入模型時發生錯誤。

