昨天探討了 Batch size 的問題和前天的 Warm-up 問題後,其實在我心中還是有個好奇的問題,也就是 Batch size 和 Learning rate 之間的關係,這是我之前在瀏覽某個 Repo 時發現的,該作者的 Learning rate decay 是根據 Batch size 大小來調整,而且和 Warm-up 提到的 Linear Scaling Rule 相反,他的策略是當 Batch size 越大時,整體訓練的學習率設置的越低。
其實會有這樣的想法感覺也挺正常的,因為當 Batch size 變大時,每次 gradient 的步伐也變大了,某種程度也像是調高了 Learning Rate,所以直覺會把 Learning Rate 也調小與之抗衡?
所以基於好奇,我也在 Colab 上設置幾個參數來觀察:
實驗一:Batch size=128, Learning rate=0.1
SHUFFLE_SIZE=1000
EPOCHS = 50
BATCH_SIZE=128
LR = 0.1
ds_train = train_split.map(
normalize_img, num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_train = ds_train.cache()
ds_train = ds_train.shuffle(SHUFFLE_SIZE)
ds_train = ds_train.batch(BATCH_SIZE)
ds_train = ds_train.prefetch(tf.data.experimental.AUTOTUNE)
ds_test = test_split.map(
normalize_img, num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_test = ds_test.batch(BATCH_SIZE)
ds_test = ds_test.cache()
ds_test = ds_test.prefetch(tf.data.experimental.AUTOTUNE)
base = tf.keras.applications.MobileNetV2(input_shape=(224, 224, 3), include_top=False, weights='imagenet')
net = tf.keras.layers.GlobalAveragePooling2D()(base.output)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[base.input], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
loss: 0.0032 - sparse_categorical_accuracy: 1.0000 - val_loss: 2.3630 - val_sparse_categorical_accuracy: 0.4500
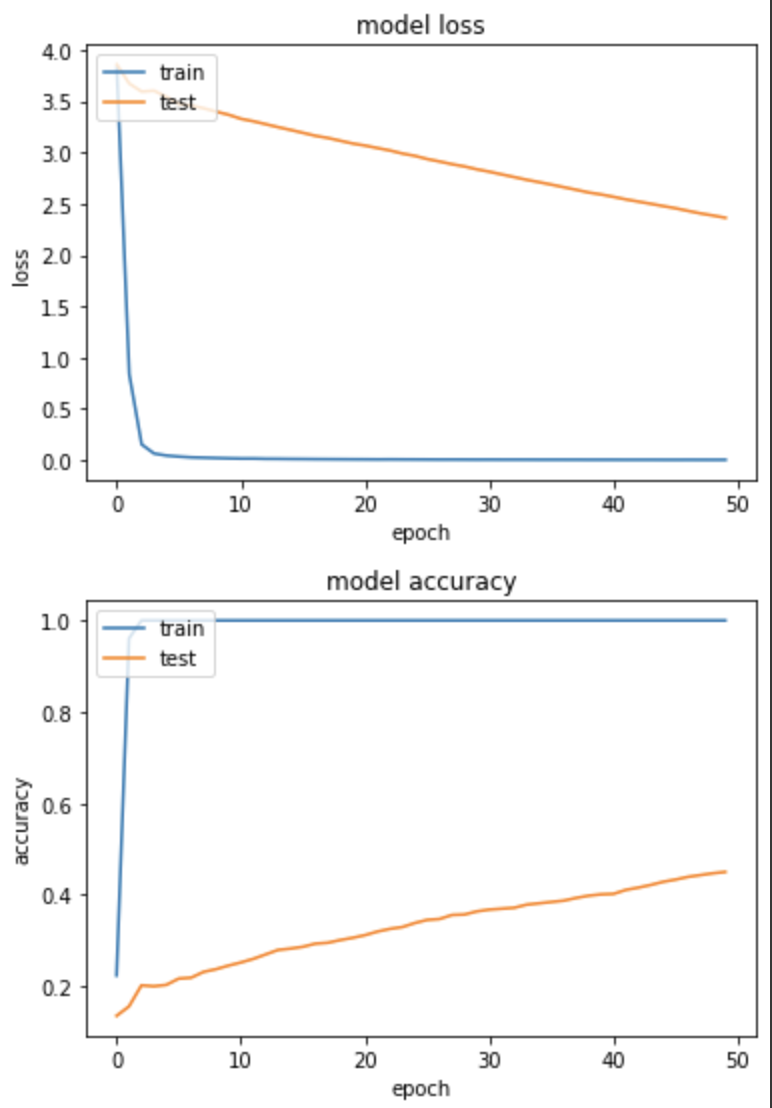
訓練集和驗證集的 loss 下降很不一致,且得出的 Accuracy 並不大理想,僅有45%。
實驗二:Batch size=128, Learning rate=0.001 (以下程式碼略過,並竟只有參數有差)
loss: 1.9535 - sparse_categorical_accuracy: 0.8559 - val_loss: 3.7203 - val_sparse_categorical_accuracy: 0.2196
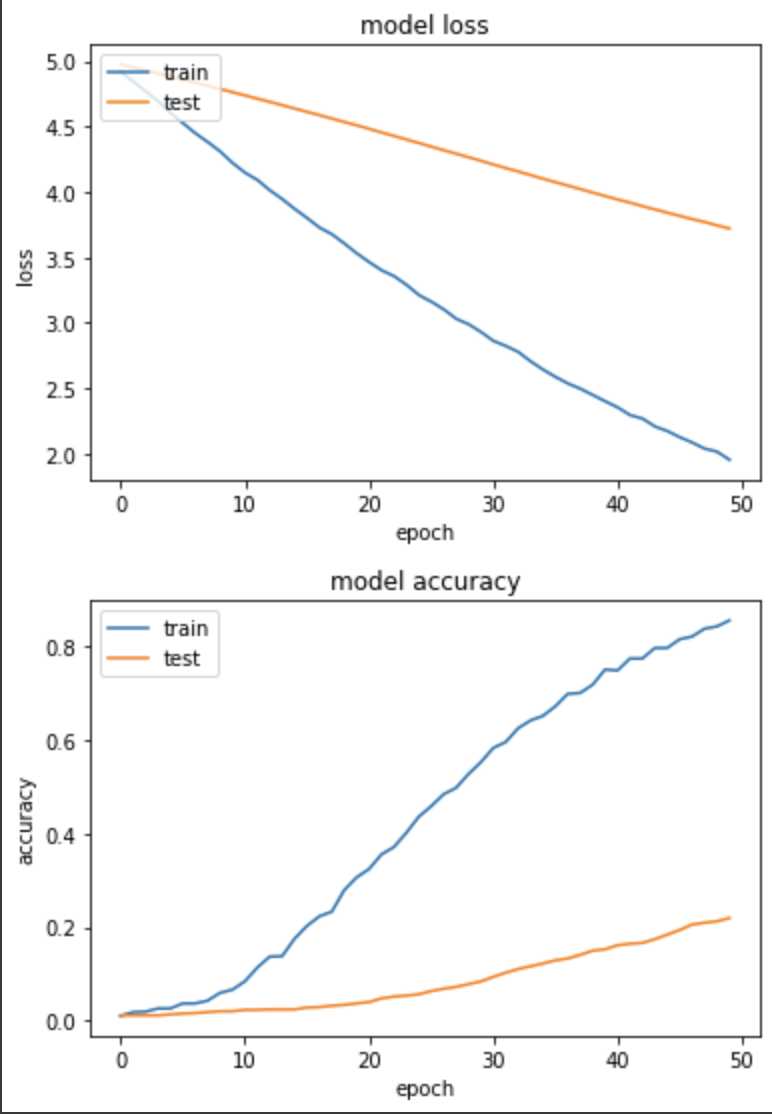
雖訓練集和驗證集 loss 下降較為一致,但進步速度非常緩慢,Accuracy不及上個實驗,可能真的是 Learning rate 太低了!
實驗三:Batch size=32, Learning rate=0.1
loss: 8.4681e-04 - sparse_categorical_accuracy: 1.0000 - val_loss: 0.5873 - val_sparse_categorical_accuracy: 0.8382
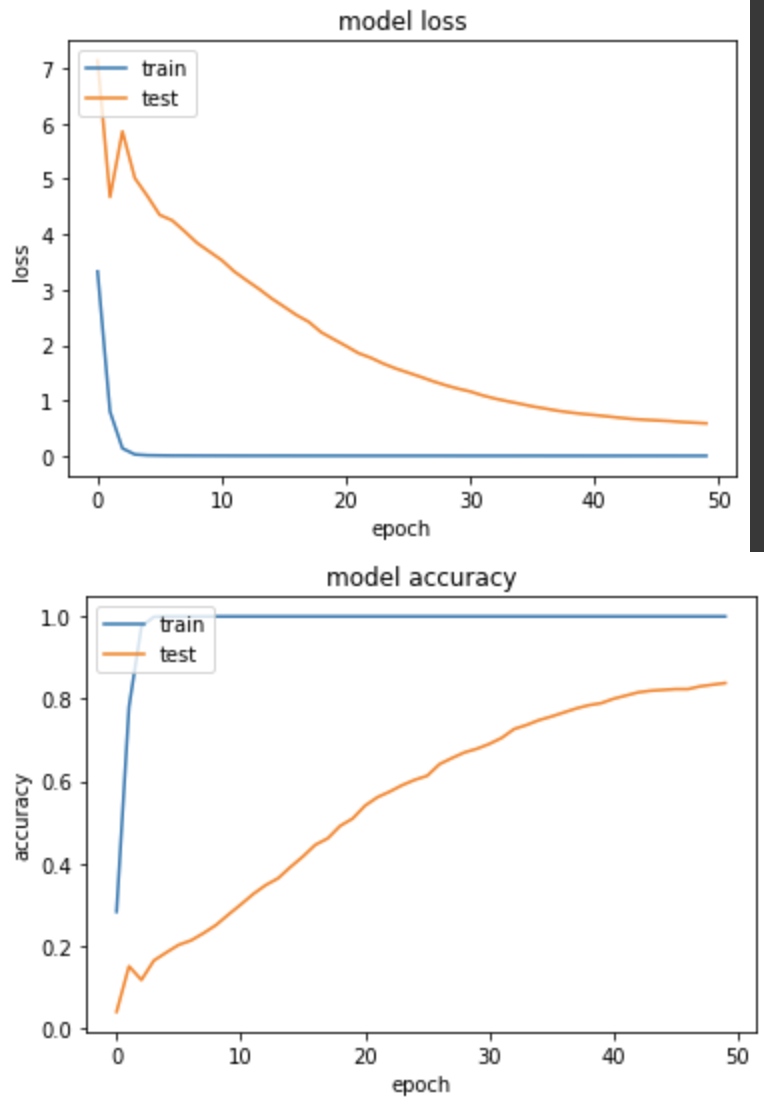
訓練集和驗證集的 loss 都下降很快,模型表現不錯,Accuracy到83.8%
實驗四:Batch size=32, Learning rate=0.001
loss: 0.3136 - sparse_categorical_accuracy: 0.9990 - val_loss: 1.7577 - val_sparse_categorical_accuracy: 0.6902
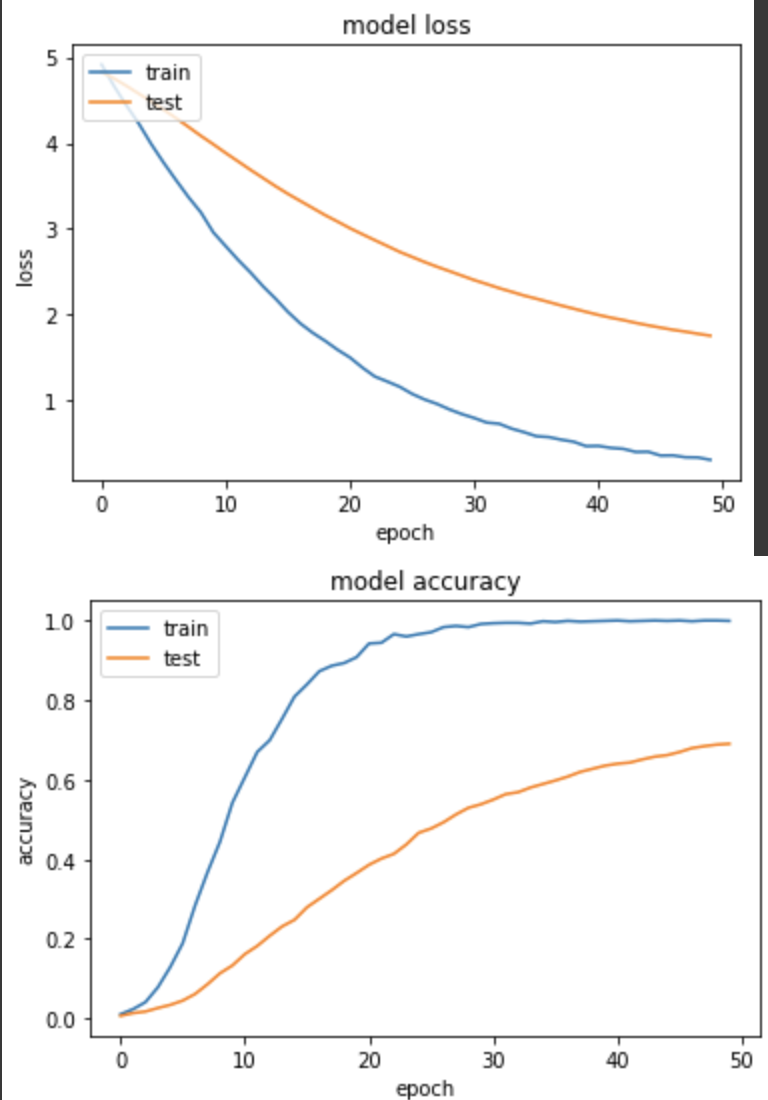
訓練集和驗證集的 loss 下降的很健康,和實驗三相比,準確度上升慢很多,但因為 learning rate 很小,可能需要更多epoch來訓練。
實驗五:Batch size=64, Learning rate=0.01
loss: 0.0218 - sparse_categorical_accuracy: 1.0000 - val_loss: 1.7184 - val_sparse_categorical_accuracy: 0.6441
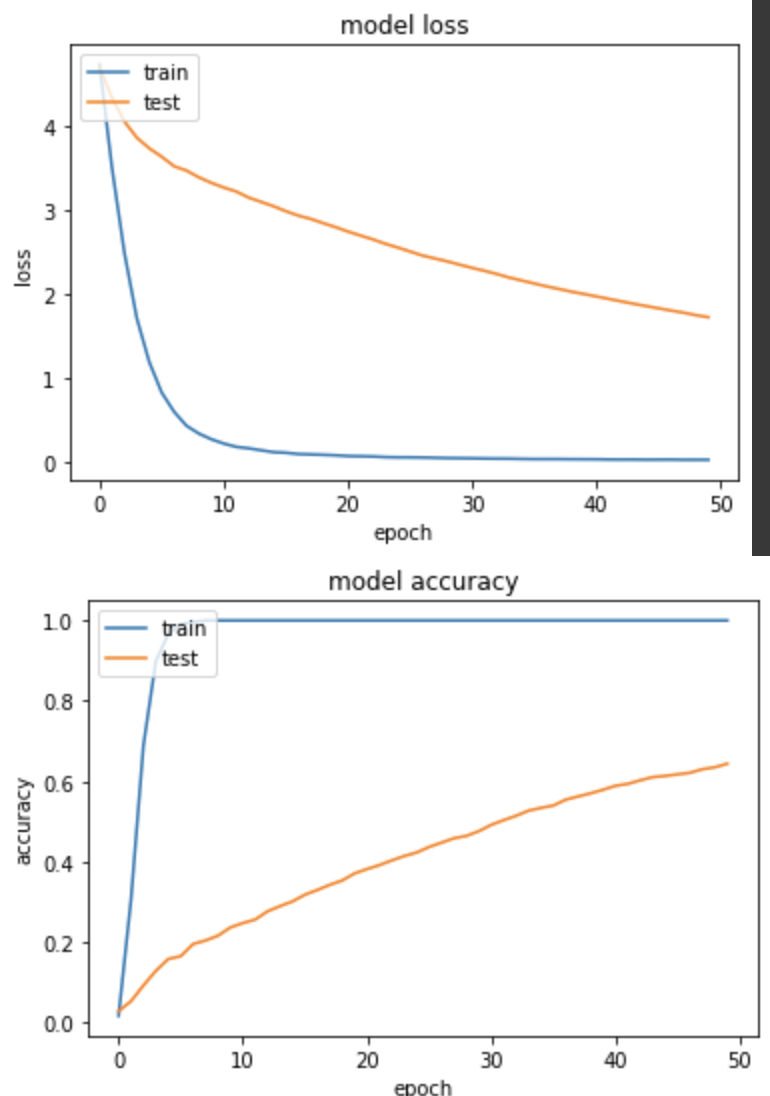
loss 下降的並不是很好,訓練集相對驗證集還是跑太快,最後 accuracy 得到64.4%
從本次實驗來看,挑選一的對的 learning rate 還是對模型學習比較健康,較大的 batch size 用較小的 learning rate 並沒有太大進步的效果。

