有沒有人發現幾乎每個在開源的專案上,Batch size 都是2的N次方,像32, 128, 256等,經過我在 stackoverflow 查詢後,找到了 Intel 官方文件中提到:
In general, the performance of processors is better if the batch size is a power of 2.
原來是因為實體處理器通常也都是2的N次方,為了能讓處理器妥善運用,所以這麼設定,但基於好奇,我想來測試一下是否在遇到 batch size 位2的N次方時,訓練時間真能夠縮短?
SHUFFLE_SIZE=1000
LR = 0.1
EPOCHS = 50
def train(batch_size):
ds_train = train_split.map(
normalize_img, num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_train = ds_train.cache()
ds_train = ds_train.shuffle(SHUFFLE_SIZE)
ds_train = ds_train.batch(batch_size)
ds_train = ds_train.prefetch(tf.data.experimental.AUTOTUNE)
base = tf.keras.applications.MobileNetV2(input_shape=(224, 224, 3), include_top=False, weights='imagenet')
net = tf.keras.layers.GlobalAveragePooling2D()(base.output)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[base.input], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
start = timeit.default_timer()
history = model.fit(
ds_train,
epochs=EPOCHS,
verbose=False)
cost_time = timeit.default_timer()-start
print(f'training done. bs: {batch_size} cost: {cost_time} sec')
return timeit.default_timer()-start
我們做寫一個 train function,需要帶入測試的 batch size,我們會計算 model.fit() 花多久時間,由於 colab 有使用時間限制,epoch 不宜設過大,batch size 的部分我取[14, 15, 16, 17, 18, 30, 31, 32, 33, 34] 這十種來測試,理想上,我們應該會發現在 batch_size=16和32時,訓練所花時間應該會少一些。
測試結果:
training done. bs: 14 cost: 827.863105417 sec
training done. bs: 15 cost: 847.0526322110004 sec
training done. bs: 16 cost: 853.054406965 sec
training done. bs: 17 cost: 790.5390958839994 sec
training done. bs: 18 cost: 859.2583510040004 sec
training done. bs: 30 cost: 910.454973295 sec
training done. bs: 31 cost: 778.0074432720003 sec
training done. bs: 32 cost: 874.4872942829998 sec
training done. bs: 33 cost: 823.8228452820003 sec
training done. bs: 34 cost: 821.9243825859994 sec
結果16和32並沒有其他相對來得低,於是我又在執行第二次
training done. bs: 14 cost: 876.093458483 sec
training done. bs: 15 cost: 828.8942355509998 sec
training done. bs: 16 cost: 895.477967417 sec
training done. bs: 17 cost: 807.7159141530001 sec
training done. bs: 18 cost: 784.7428535139998 sec
training done. bs: 30 cost: 708.2653999240001 sec
training done. bs: 31 cost: 686.826350065 sec
training done. bs: 32 cost: 817.7144867099996 sec
training done. bs: 33 cost: 733.212714794 sec
training done. bs: 34 cost: 707.462420588 sec
我們將兩次的成果畫成圖
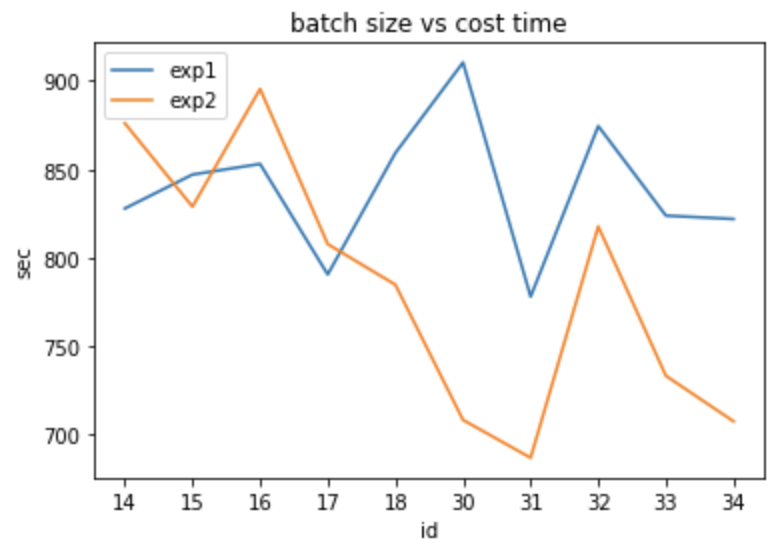
結果兩次的測試當batch_size=16和32竟然都是相對花時間...當然,這有可能是 Colab 提供的 GPU 可能是共享的,所以在本次實驗中失去參考性,也許在自己組裝的 GPU 會有不一樣的結果?

