前一篇文章帶大家看了 Python 中的條件判斷以及迴圈等語法,大家要先把這些基本語法用熟,之後的幾天會比較順利歐。
Day 2 有帶給大家基本的一些資料型態,其中的字串(str)這個型態在爬蟲中會常常被處理到,因此今天我們會帶讀者們深入研究一下字串的用法。
大家可能會發現字串(str)有些操作跟串列(list)很相似,大家可以試試看對字串做 len(str) (回傳字串長度)這個操作,看會發生什麼事。
語法 :str[開始位置:結束位置:間隔位置]
開始位置 : 若為正數代表從字串最左邊開始,負數則從最右邊往回數。空值代表從 0 開始。
結束位置 : 擷取的字串的結束位置。空值代表擷取到字串尾部。
間隔位置 : 每擷一個字後,離下個字要相差幾格。空值代表每次差 1 格。
以下為範例,大家能先把 Output 遮起來看自己有沒有答對歐。
text = 'abcdefghijk'
#擷取 index 為 4 到結尾
print(text[4:]) #Output: efghijk
#擷取 index 倒數 5 到結尾
print(text[-5:]) #Output: ghijk
#擷取 index 為 1 到 index 為 2
print(text[1:3]) #Output: bc
#擷取 index 為 0 到 index 為 2
print(text[:3]) #Output: abc
#擷取 index 為 1 到結尾,每次差 2 格
print(text[1::2]) #Output: bdfhj
#擷取 index 為 0 到結尾,每次差 -1 格
print(text[::-1]) #此為常用將字串反轉的操作 Output: kjihgfedcba
語法 :str.replace(取代前字串, 取代後字串)
任何符合取代前字串的字串將被取代為取代後的字串
text = 'user:OwOb|passwd:1234lol'
#將 | 取代為 空白
print(text.replace('|', ' '))
'''
user:OwOb passwd:1234lol
'''
#將 | 取代為 \n(\n 為 換行字元,沒聽過的讀者能去 google 「跳脫字元 \n」)
print(text.replace('|', '\n'))
'''
user:OwOb
passwd:1234lol
'''
#將 : 取代為 空白,並將結果字串的 | 取代為 \n
print(text.replace('|', '\n').replace(':', ' '))
'''
user OwOb
passwd 1234lol
'''
語法 :str.replace(想尋找的字串[, 開始位置, 結束位置])
回傳在原字串中第一個符合想尋找的字串的位置(想尋找的字串最開始出現的 index)
若開始位置與結束位置為空則搜尋全部字串
text = '<a href="https://vimsky.com/zh-tw/examples/detail/python-module-email.MIMEMultipart.html">OwO</a>'
#尋找 href 第一次出現的位置
print(text.find('href')) #Output: 3
#尋找 > 第一次出現的位置
print(text.find('>')) #Output: 89
語法 :str.split(分隔字串[, 分隔次數])
將字串以分隔字串分隔開來,將會回傳一個串列(list)。
分隔次數若為空值,代表將所有分隔字串分隔。
text1 = 'A|B|C|D|E|F|G'
text2 = 'user:lol'
# 將 text1 以 | 分隔,之後將其回傳的串列用 for 迴圈遍歷逐一將字串印出
processedText1s = text1.split('|')
for processedText1 in processedText1s:
print(processedText1)
'''
A
B
C
D
E
F
G
'''
# 將 text2 以 : 分開,之後將倒數第一個字串印出
print(text2.split(':')[-1])
'''
lol
'''
正規表達式是一個拿來匹配字串極好用的工具,他有獨立的語法,並且能透過自己的特定語句規則(Pattern),達到搜尋、萃取、替代滿足該條件的字串。
下面做一個找出電話號碼的範例
import re
text = 'My phone number is 0987-878887 not 0912-345678. wait a second, is 0987-654321, wait wait wait is 0901-000000 I wrong wrong wrong Orz.'
#寫好我們的 Pattern 應該不難理解 \d 代表的是數字
Pattern = r'\d\d\d\d-\d\d\d\d\d\d'
#編譯我們的 Pattern 使其變為一個 Regex 物件
phoneRegex = re.compile(Pattern)
#透過我們編譯的物件在欲尋找的字串中比對並回傳符合 Pattern 的所有字串的串列(list)
phones = phoneRegex.findall(text)
print(type(phones))# Output: <class 'list'>
for phone in phones:
print(phone)
'''
0987-878887
0912-345678
0987-654321
0901-000000
'''
在 Python 中內建了 regex expression 的套件 re ,在 python 中 import re 即可引入該套件。
正規表達式包含了兩個部分,撰寫正規語法跟正規處理函式,分別對應上面例子的 Pattern 跟 findall。下面將這兩個分開介紹。
這邊介紹幾個萬用字元,有興趣了解更多或已經很熟的讀者能去補充資料那邊拿到更多正規語法,讀者能根據自己的需求來組出不同的 Pattern。
這邊推薦一個網站 https://regex101.com/ 這個網站能夠及時將你輸入的字串比對你的正規語法,十分方便。
| 萬用字元 | 規則 | 例子 |
|---|---|---|
| . | 比對任意字元 | 'OwO' >>> 'O.O' → '**OwO**' |
| ^ | 比對開頭位置 | 'Name123Name' >>> '^Name' → '**Name**123Name' |
| * | 比對前一個字元 0 到多次 | 'OTTTTTO' >>> 'OT*O' -> '**OTTTTTO**' |
| ? | 比對前一個字元 0 到 1 次 | 'OTTTTTO' >>> 'OT?O' -> 'OTTTTT**OTO**' |
| + | 比對前一個字元 1 到多次 | 'OTTOOTTTOTO' >>> 'OT?O' -> 'OTT**OO**TTT**OTO**' |
| {m} | 比對前一個字元嚴格 m 次 | 'OOTTTOOTTOOTTTTO' >>> 'OT{3}O' -> 'O**OTTTO**OTTOOTTTTO*' |
| {m,n} | 比對前一個字元嚴格 m 到 n 次 | 'TATTAAATTAAT' >>> 'TA{3,4}T' -> 'TAT**TAAAAT**TAAT*' |
| {m,n}? | 比對前一個字元嚴格 m 到 n 次,盡量取少 | 'OTTTT' >>> 'OT{2,3}?' -> '**OTT**TT*' |
| () | 小括號括住的地方設定為一個分組 | 'OOOwOOO' >>> 'O(OwO)O' -> 'OO*OwO*OO'(代表第一分組的匹配) |
| \\ | 正則表達式用的跳脫字元,用於跳脫萬用字元 | 'O.OOwO' >>> 'O\\.O' -> '**O.O**OwO' |
| [] | 字元集,能用 [a-b] 表示 a~b 的所有字元集合 | 'OAOOuOOTOOeOOwO' >>> 'O[ATw]O' -> '**OAO**OuO**OTO**OeO**OwO**' |
| | | 邏輯中的 或, a|b 代表比對 a 或 b | 'OAOOuOOTO' >>> 'OAO|OTO' -> '**OAO**OuO**OTO**' |
| \w | 比對字母數字及底線,等同於 [A-z0-9_] | 'user:Vin_30;' >>> '\w\w\w\w\w\w' -> 'user:**Vin_30**;' |
| \W | 比對除了字母數字及底線外的字元,等同於 [^A-z0-9_] | 'OwOO%OOTO' >>> 'O\WO' -> 'OwO**O%O**OTO' |
| \d | 比對數字,等同於 [0-9] | 'phone:0912-345678' >>> '\d\d\d\d-\d\d\d\d\d\d' -> 'phone:**0912-345678**' |
| \D | 比對除了數字外的字元,等同於 [^0-9] | 'phone:0912-345678' >>> '\D\D\D\D\D' -> '**phone**:0912-345678' |
語法 :re.search(pattern, string, flags=0)
匹配全部字串,匹配後即回傳(代表只會匹配一組)。若有匹配,回傳一個匹配實例,否則回傳 None。
對於回傳的匹配實例有 group(num=0) groups()
group(num=0) : 回傳匹配實例的 num 分組,預設回傳第 0 組
groups : 回傳所有分組
import re
text = 'nowtime: Fri Sep 17 10:08:54 2021 nowtime: Fri Sep 19 10:09:54 2021'
a = re.search(r': ([A-z]{3} [A-z]{3} \d{2}) (\d+:\d+:\d+ \d+)', text)
#這邊要注意 除了匹配 : [A-z]{3} [A-z]{3} \d{2} \d+:\d+:\d+ \d+ 外
#還有在 ([A-z]{3} [A-z]{3} \d{2}) (\d+:\d+:\d+ \d+) 設定為分組
#讓我們在 group 能夠選取到我們想要的地方
print('group0:', a.group(0))
print('group1:', a.group(1))
print('group2:', a.group(2))
print('groups:', a.groups())
#另外一個注意的點是他只回傳了第一個匹配的
'''
group0: : Fri Sep 17 10:08:54 2021
group1: Fri Sep 17
group2: 10:08:54 2021
groups: ('Fri Sep 17', '10:08:54 2021')
'''
語法 : re.match(pattern, string, flags=0)
只匹配字串的开始位置,而不匹配每行开始。若有匹配,回傳一個匹配實例,否則回傳 None。
text = 'nowtime1: Fri Sep 17 10:08:54 2021 nowtime2: Fri Sep 19 10:09:54 2021'
a = re.match(r'nowtime[0-9]', text)
print('group0:', a.group())
'''
group0: nowtime1
'''
語法 :re.findall(pattern, string, flags=0)
回傳所有符合的字串,不用使用group() groups() 來選取想要使用的字串。
import re
text = 'nowtime: Fri Sep 17 10:08:54 2021 nowtime: Fri Sep 19 10:09:54 2021'
founds = re.findall(r': ([A-z]{3} [A-z]{3} \d{2} \d+:\d+:\d+ \d+)', text)
for found in founds:
print(found)
'''
Fri Sep 17 10:08:54 2021
Fri Sep 19 10:09:54 2021
'''
語法 :re.sub(pattern, replace, string, count=0, flags=0)
將符合的字串替換為 replace 。
import re
text = '0912345678'
newText = re.sub(r'^\d{2}', '+886', text)
print(newText)
'''
+88612345678
'''
對想挑戰的讀者,這邊是海豹在 R2S CTF 出的一題 How Regular is This, 要透過想出那些字串會被行/列的 pattern 匹配,完成這個填字遊戲。
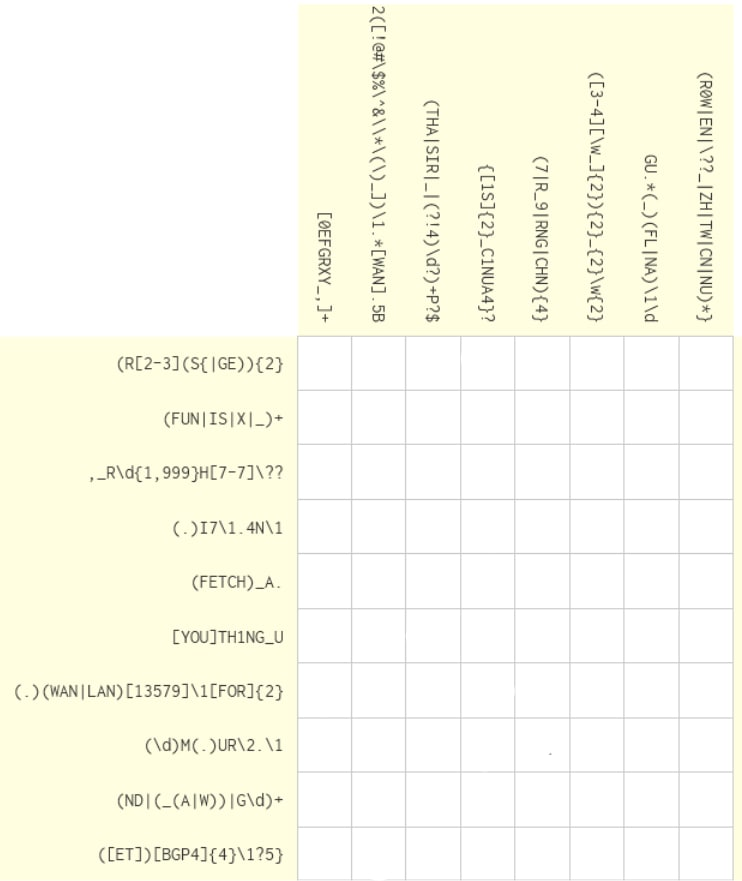
▲題目(下面附答案)

▲答案
ref: seadog007 on R2S CTF
今天跟讀者們介紹了 Python 中字串的基本用法及正規表達式的基本應用,熟練正規表達式後,了解一下就會發現它在很多語言皆有出現,能夠很方便的將想要提取出來的文字提取出來。
明天將會帶給網頁開發工具的介紹。有不小心按過 F12 或有聽別人說用 F12 就能當駭客的讀者能持續追蹤後續內容歐。
正規表達式線上測試 : https://regex101.com/
正規表達法 python regular expression 教學及用法 : http://python-learnnotebook.blogspot.com/2018/10/python-regular-expression.html
Python 速查手冊 12.1 正規運算式 re : http://kaiching.org/pydoing/py/python-library-re.html

