https://github.com/PacktPublishing/Machine-Learning-Algorithms
一樣先導入套件,上面的是用來算數學的;下面的是用來畫畫的,並且幫它們取綽號(np & plt)。
import numpy as np
import matplotlib.pyplot as plt
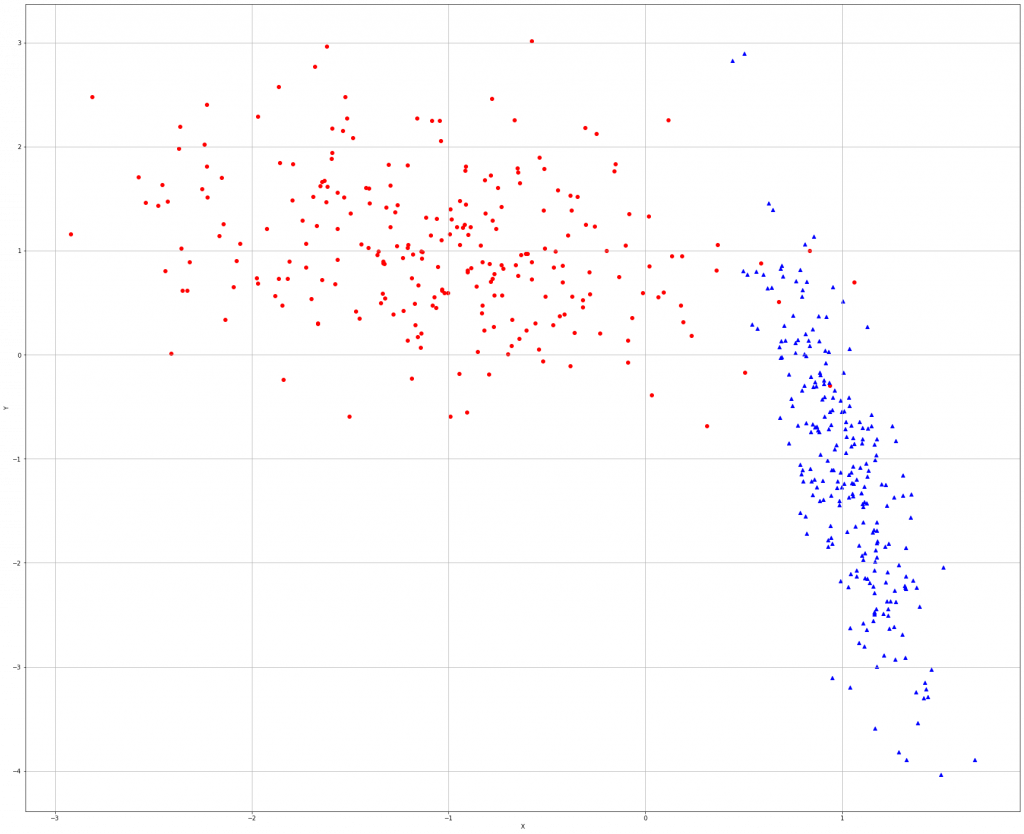
再來,用seed()隨機產生整數的亂數後,設定樣本數,細分為兩個類別各500個的向量的樣本集。
from sklearn.datasets import make_classification np.random.seed(1000) nb_samples = 500 X, Y = make_classification(n_samples=nb_samples, n_features=2, n_informative=2, n_redundant=0,n_clusters_per_class=1)
可以看到圖中有些點介於重疊處,因此,需要使用正數的C讓模型捕捉較複雜的動態。
scikit-learn有SVC類別,可以增加我們效率。並且會使用他與交叉驗證來驗證效能。
from sklearn.svm import SVC from sklearn.model_selection import cross_val_score svc = SVC(kernel='linear') svc_scores = cross_val_score(svc, X, Y, scoring='accuracy', cv=10) print('Linear SVM CV average score: %.3f' % svc_scores.mean())#Linear SVM CV average score: 0.984
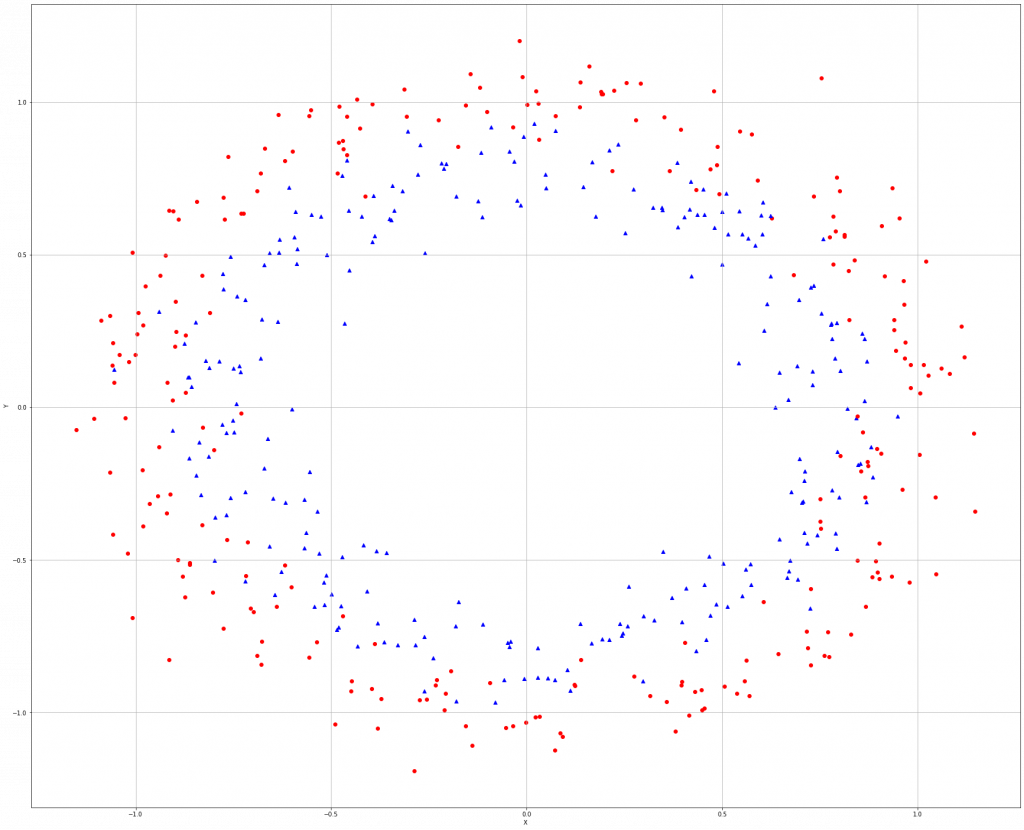
使用make_circles()函式建立非線性資料集。
from sklearn.datasets import make_circles nb_samples = 500 X, Y = make_circles(n_samples=nb_samples, noise=0.1)
若使用邏輯斯回歸預測的話,錯誤率大概45%,所以要用其他更準確的方式。
Logistic regression CV average score: 0.450
那我們使用不同的核函數來測試。最終結果資料集的幾何預期,最佳的核是'rbf',準確率有88%
import multiprocessing
from sklearn.model_selection import GridSearchCV
param_grid = [
{
'kernel': ['linear', 'rbf', 'poly', 'sigmoid'],
'C': [0.1, 0.2, 0.4, 0.5, 1.0, 1.5, 1.8, 2.0, 2.5, 3.0]
}
]
gs = GridSearchCV(estimator=SVC(), param_grid=param_grid,
scoring='accuracy', cv=10, n_jobs=multiprocessing.cpu_count())
gs.fit(X, Y)
print(gs.best_estimator_) # SVC(C=1.5)
print('Kernel SVM score: %.3f' % gs.best_score_) # Kernel SVM score: 0.880


 iThome鐵人賽
iThome鐵人賽