昨天我們介紹了 Shuffle 這支 API 的使用方式,其中特別提到了如果今天資料集本身沒有先打散的話,你後面再做 shuffle 時,如果 batch size 不等於整個資料數量的話,就不是打的非常散,基於此問題,今天我們用 mnist 來實驗若資料沒有事前打亂,單純只靠 shuffle API 是否能有成效?
樣本一,我們使用 tfds 提供的 mnist,要初始化非常簡單。
ds_data, ds_info = tfds.load(
'mnist',
shuffle_files=False,
as_supervised=True,
with_info=True,
)
train_split, test_split = ds_data['train'], ds_data['test']
fig = tfds.show_examples(train_split, ds_info)
fig.show()

由於 tfds 所提供的資料集都已將資料打散了,為了要重現整齊的 mnist,我選擇重新下載 mnist 來處理。
!wget http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz .
!wget http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz .
!wget http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz .
!wget http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz .
我們用 numpy 的 argsort 來排序資料。
idx = np.argsort(train_labels)
train_labels_sorted = train_labels[idx]
train_images_sorted = train_images[idx]
idx = np.argsort(test_labels)
test_labels_sorted = test_labels[idx]
test_images_sorted = test_images[idx]
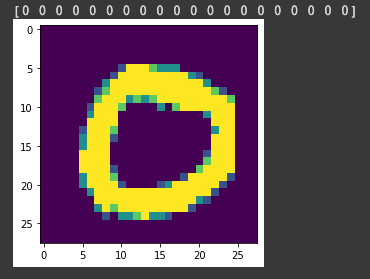
我們印出 label 前20個元素,可以看到都是0,而圖片也畫出0。
print(test_labels_sorted[:20])
image = np.asarray(test_images_sorted[0]).squeeze()
plt.imshow(image)
plt.show()
接著就可以開始我們的實驗,實驗一,正常有打散的 mnist
model = tf.keras.Sequential()
model.add(tf.keras.layers.Conv2D(32, [3, 3], activation='relu', input_shape=(28,28,1)))
model.add(tf.keras.layers.Conv2D(64, [3, 3], activation='relu'))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2)))
model.add(tf.keras.layers.Dropout(0.25))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(10))
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
ds_train_tf, # 打散的ds
epochs=EPOCHS,
validation_data=ds_test_tf, # 打散的ds
)
產出:
loss: 0.0473 - sparse_categorical_accuracy: 0.9850 - val_loss: 0.0314 - val_sparse_categorical_accuracy: 0.9901
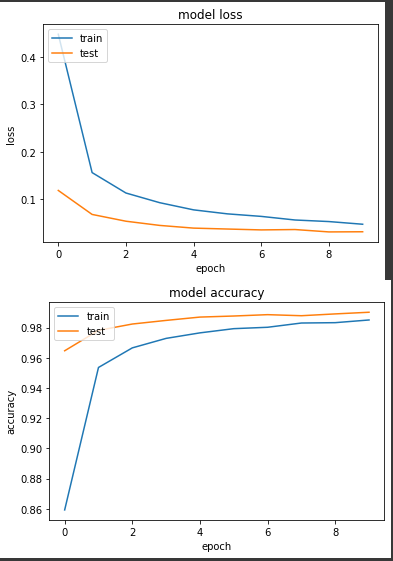
看來我們建立的模型對於學習 mnist 錯錯有餘,驗證集的 loss 比訓練值還低,驗證集準確度也上升的比訓練集快,代表模型不用一個 epoch 的時間就能學得很好。
實驗二,label 照順序的 mnist。
model = tf.keras.Sequential()
model.add(tf.keras.layers.Conv2D(32, [3, 3], activation='relu', input_shape=(28,28,1)))
model.add(tf.keras.layers.Conv2D(64, [3, 3], activation='relu'))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2)))
model.add(tf.keras.layers.Dropout(0.25))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(10))
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
ds_train_m, # 照順序的ds
epochs=EPOCHS,
validation_data=ds_test_m, # 照順序的s
)
產出:
loss: 0.0631 - sparse_categorical_accuracy: 0.9845 - val_loss: 5.9616 - val_sparse_categorical_accuracy: 0.2695
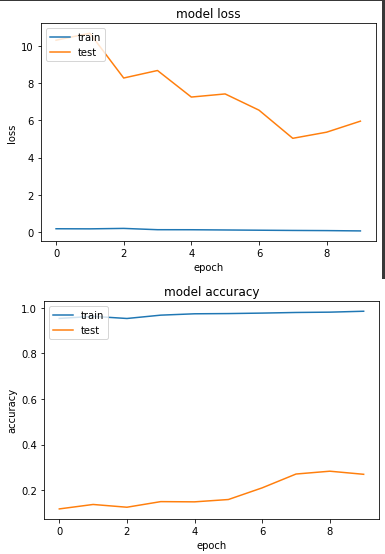
非常詭異的圖,在第一個 epoch 前,訓練集 accuracy 接近100%,但是驗證集準確度卻非常低,為什麼會這樣子呢?我自己的想像是我訓練模型時,一個 epoch 假設有100個題目,但是前10題答案都是0,後面10題答案都是1,依序下去...
那模型會在前面就被訓練成只要回答0就會對的懶惰模型,中間雖然答案變成1有誘發模型去學習1的特徵,但是回打沒幾題後發現反正答案都是1,又變回懶惰模型,所以整體模型要學會數字1~9的效率會非常差,這也就導致了這次實驗模型學不太起來的窘境,而且即使套用了 shuffle 也沒起色!


 iThome鐵人賽
iThome鐵人賽