KNN 的全名 K Nearest Neighbor 是屬於機器學習中的 Supervised learning 其中一種算法,顧名思義就是 k 個最接近你的鄰居。分類的標準是由鄰居「多數表決」決定的。在 Sklearn 中 KNN 可以用作分類或迴歸的模型。
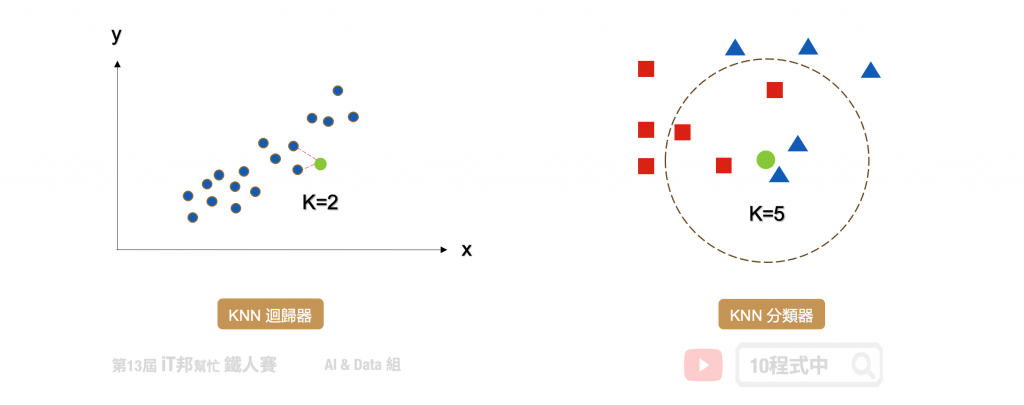
在分類問題中 KNN 演算法採多數決標準,利用 k 個最近的鄰居來判定新的資料是在哪一群。其演算法流程非常簡單,首先使用者先決定 k 的大小。接著計算目前該筆新的資料與鄰近的資料間的距離。第三步找出跟自己最近的 k 個鄰居,查看哪一組鄰居數量最多,就加入哪一組。
如果還是沒辦法決定在哪一組,回到第一步調整 k 值,再繼續
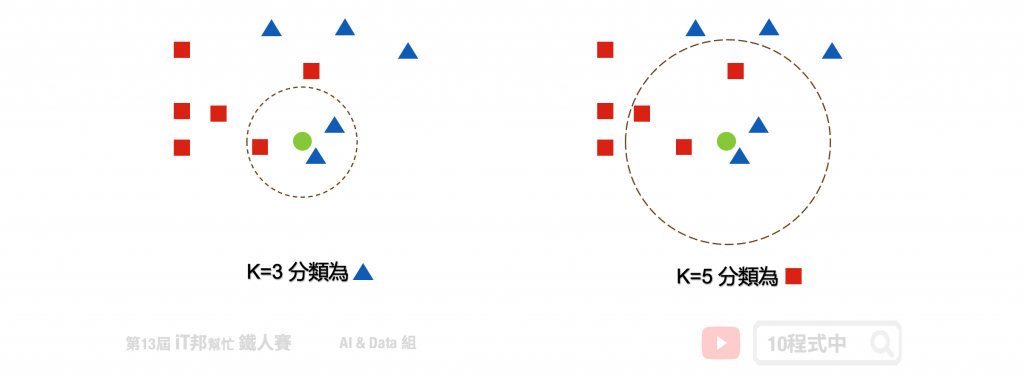
k 的大小會影響模型最終的分類結果。以下圖為例,假設綠色點是新的資料。當 k 等於 3 時會搜尋離綠色點最近的鄰居,我們可以發現藍色三角形為預測的結果。當 k 設為 5 的時候結果又不一樣了,我們發現距離最近的三個鄰居為紅色正方形。
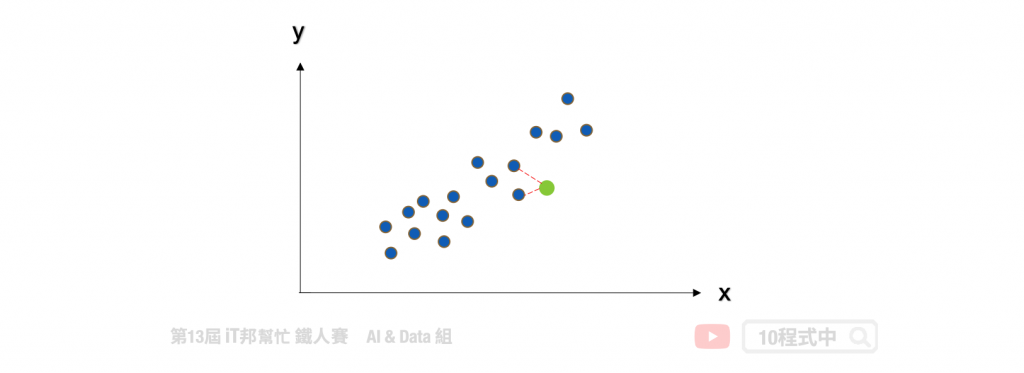
KNN 同時也能運用在迴歸問題上面。迴歸模型輸出的結果是一個連續性數值,其預測該值是 k 個最近鄰居輸出的平均值。以下圖為例當 k=2 時,假設我們有一個輸入特徵 x 要預測的輸出為 y。當有一筆新的 x 進來的時候, KNN 迴歸器會尋找鄰近 2 個 x 的輸出做平均當作是該筆資料的預測結果。
要判斷那些是鄰居的話,首先要量化相似度,而歐幾里得距離 (Euclidean distance) 是比較常用的方法來量度相似度。除此之外還有明可夫斯基距離(Sklearn 預設)、曼哈頓距離、柴比雪夫距離、夾角餘弦、漢明距離、傑卡德相似係數 都可以評估距離的遠近。

KNN 的缺點是對資料的局部結構非常敏感,因此調整適當的 k 值極為重要。另外大家很常將 KNN 與 K-means 混淆,雖然兩者都有 k 值要設定但其實兩者無任何關聯。KNN 的 k 是設定鄰居的數量採多數決作為輸出的依據。而 K-means 的 k 是設定集群的類別中心點數量。

採用鳶尾花朵資料集做為分類範例,使用 Sklearn 建立 k-nearest neighbors(KNN) 模型。以下是 KNN 常見的模型操作參數:
Parameters:
Attributes:
Methods:
from sklearn.neighbors import KNeighborsClassifier
# 建立 KNN 模型
knnModel = KNeighborsClassifier(n_neighbors=3)
# 使用訓練資料訓練模型
knnModel.fit(X_train,y_train)
# 使用訓練資料預測分類
predicted = knnModel.predict(X_train)
我們可以直接呼叫 score() 直接計算模型預測的準確率。
# 預測成功的比例
print('訓練集: ',knnModel.score(X_train,y_train))
print('測試集: ',knnModel.score(X_test,y_test))
執行結果:
訓練集: 0.9619047619047619
測試集: 0.9555555555555556
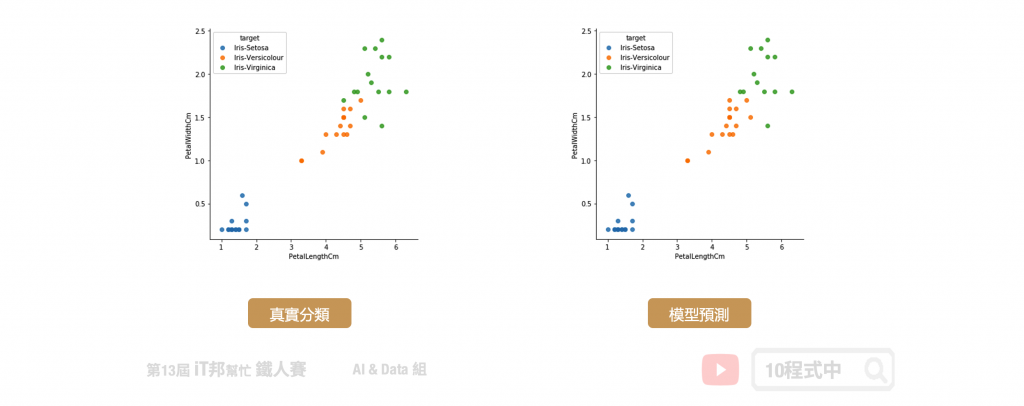
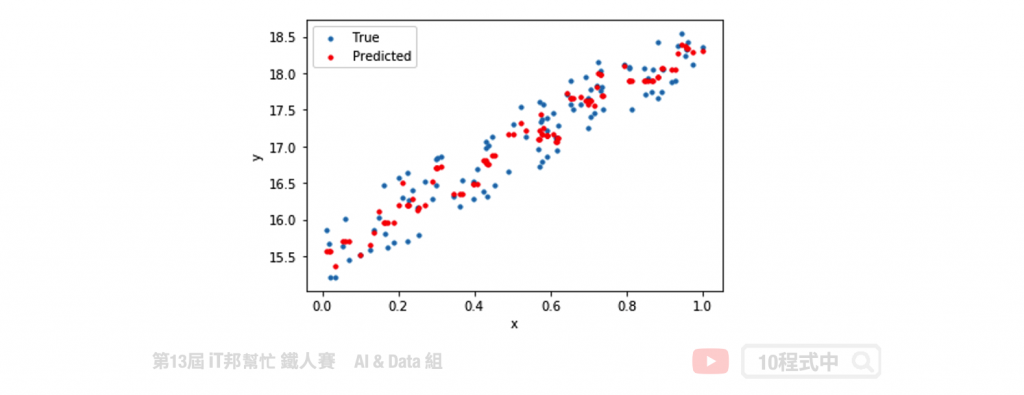
我們可以查看訓練好的模型在測試集上的預測能力,下圖中左邊的是測試集的真實分類,右邊的是模型預測的分類結果。從圖中可以發現藍色的 Setosa 完整的被分類出來,而橘色與綠色的分佈是緊密相連在交界處分類的結果比較不穩定。但最終預測結果結果在訓練集與測試集都有百分之95以上的準確率。
KNN 不僅能夠作為分類器,也可以做迴歸連續性的數值預測。其預測值為k個最近鄰居的值的平均值。
Parameters:
Attributes:
Methods:
from sklearn.neighbors import KNeighborsRegressor
# 建立 KNN 模型
knnModel = KNeighborsRegressor(n_neighbors=3)
# 使用訓練資料訓練模型
knnModel.fit(x,y)
# 使用訓練資料預測
predicted= knnModel.predict(x)
Sklearn 中 KNN 迴歸模型的 score 函式是 R2 score,可作為模型評估依據,其數值越接近於1代表模型越佳。除了 R2 score 還有其他許多迴歸模型的評估方法,例如: MSE、MAE、RMSE。
from sklearn import metrics
print('R2 score: ', knnModel.score(x, y))
mse = metrics.mean_squared_error(y, predicted)
print('MSE score: ', mse)
文章同時發表於: https://andy6804tw.github.io/crazyai-ml/10.KNN
如果你對機器學習和人工智慧(AI)技術感興趣,歡迎參考我的線上免費電子書《經典機器學習》。這本書涵蓋了許多實用的機器學習方法和技術,適合任何對這個領域有興趣的讀者。點擊下方連結即可獲取最新內容,讓我們一起深入了解AI的世界!
👉 全民瘋AI系列 [經典機器學習] 線上免費電子書
👉 其它全民瘋AI系列 這是一個入口,匯集了許多不同主題的AI免費電子書

