走過了資料分析、演算法選擇後,
我們得知了有些可以改善模型的方向:
這邊我做實驗都是為了比較不同方法帶給模型的提升,
而並非追求最佳模型,
所以在未來我的最終訓練輪數絕對會遠遠超過30,
很有可能落在100到300之間,
這樣我要跑一個模型就要3小時以上,
抱歉我只能說我不OK,你先train。
如果大家真的想不開要去找最佳epoch,
建議大家使用Google Colab完成。
(如果資料量很大,建議不要忍一下,直接買Pro方案)
在傳統的機器學習領域,我們獲得訓練資料和標籤,
訓練一下就可以獲得還不錯的模型。
但在現今深度學習領域,我們擁有巨量的訓練資料,
可惜的是標籤並沒有辦法也這麼大量。
那怎麼辦呢?
那就是Transfer Learning!
有學過一點統計的人,
應該聽過分布相同假設,
或更常聽到的是「我們假設這兩個隨機變數都來自常態分布,所以我們可以推導出...」,
很多傳統機器學習方法本質上就是統計方法。
那些方法會需要在訓練資料和測試資料相同分布的前提下才能使用。
如果分布不同,則應用在測試資料時會悽慘無比。
遷移學習就是把用現有資料學習好的模型直接拿來使用,
因為卷積神經網路的前幾層具有通用性廣泛的特徵(低階特徵),
這些特徵在不同分布的圖片中都可以使用。
比如說貓狗辨識網路的前兩層可以遷移到虎狼辨識網路上。
因為老虎和狼的照片與貓和狗的照片有點相似,卻又不完全一樣。
如果直接拿貓狗辨識網路來分辨老虎和狼的話,應該會很落漆~
諸如Google、Facebook等大公司有著巨量的資料、大量的運算資源和源源不絕的工作應聘者。
很多深度學習網路只有他們才能訓練出來。
他們已經用我們無法企及的大數據訓練出一個很棒的網路,
我們拿來微調最後的分類層就好了
隨著測試資料和預訓練資料的差異越大,我們有1~3的方法。
越後面介紹的方法會調整越多預訓練的參數。
這是最簡單的版本,單純把預訓練CNN的最後一層卷積層輸出(feature map)拿出來,
然後就沒有預訓練CNN的事情了。
之後用feature map當作一張圖片的特徵,去訓練一個簡單的機器學習模型,
像是SVM、RF、NN等等。
這是真正意義上的遷移學習,
我們把預訓練模型拿出來,
只對最後的輸出層進行訓練,
其他層的參數都固定不動。
這是實際上最常用的方法,
相比於第2個方法只訓練輸出層,
Fine-tune會多訓練幾層。(通常是靠近輸出層的網路層)
這個「多訓練幾層」也可以是「訓練全部網路層」,
我們把它叫做「微調」。
在實務上,
我們會從後面的網路層開始逐漸解凍,
每解凍一個區域就訓練個幾輪。
例如:
def build_model(preModel=EfficientNetB0,
pretrained=True,
num_classes=7,
input_shape=(48, 48, 3),
l2_coef=0.0001):
pre_model = preModel(include_top=False, weights='imagenet' if pretrained == True else None,
input_shape=input_shape,
pooling='max', classifier_activation='softmax')
for layer in pre_model.layers:
layer.trainable = False
x = Dropout(0.2)(pre_model.output)
output = Dense(
num_classes, activation="softmax", name="main_output",
kernel_regularizer=regularizers.l2(l2_coef))(x)
freezed_model = tf.keras.Model(pre_model.input, output)
freezed_model.compile(optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.CategoricalCrossentropy(),
metrics=['accuracy'])
return freezed_model
如果你想要把神經網路的最後n層變成可訓練的:
def unfreeze_model(model, n=1, is_unfreeze_BN=False):
# We unfreeze the top n layers while leaving BatchNorm layers frozen
# n = 6 (~ block-top)
# n = 19 (~ block-7)
# n = 78 (~ block-6)
if is_unfreeze_BN == False:
for layer in model.layers[-n:]:
if not isinstance(layer, BatchNormalization):
layer.trainable = True
else:
for layer in model.layers[-n:]:
layer.trainable = True
記得最後要再執行一次model.compile(),
這些改動才會生效。
這裡我第一階段先解凍6層,訓練15輪。
第二階段解凍19層(包含那6層),再訓練15輪。
總共30輪。
unfreeze_n = [6, 19]
phase_epochs = [15, 30]
phase_batch_size = [32, 32]
phases = len(phase_epochs)
model = build_model()
for i in range(phases):
unfreeze_model(model, n=unfreeze_n[i])
model.fit(X_train, y_train_oh,
validation_data=(X_val, y_val_oh),
initial_epoch=0 if i == 0 else phase_epochs[i-1],
epochs=phase_epochs[i],
batch_size=phase_batch_size[i])
我把模型分成三個區塊:
| 區塊名稱 | 從後面數來的層數 |
|---|---|
| Block-top | 6 |
| Block-7 | 19 |
| Block-6 | 78 |
| Block-all | 全部 |
把訓練好的模型用以下稱呼:
初始模型: EFN_base_init(不使用預訓練參數,直接訓練Block-all)
模型零: EFN_base(單一階段微調Block-all)
模型一: EFN_2StepsToBlock7(先微調Block-top、再微調Block-7)
模型二: EFN_2StepsToAll(先微調Block-top、再微調Block-all)
模型三: EFN_3StepsToAll(先微調Block-top、再微調Block-7、再微調Block-all)
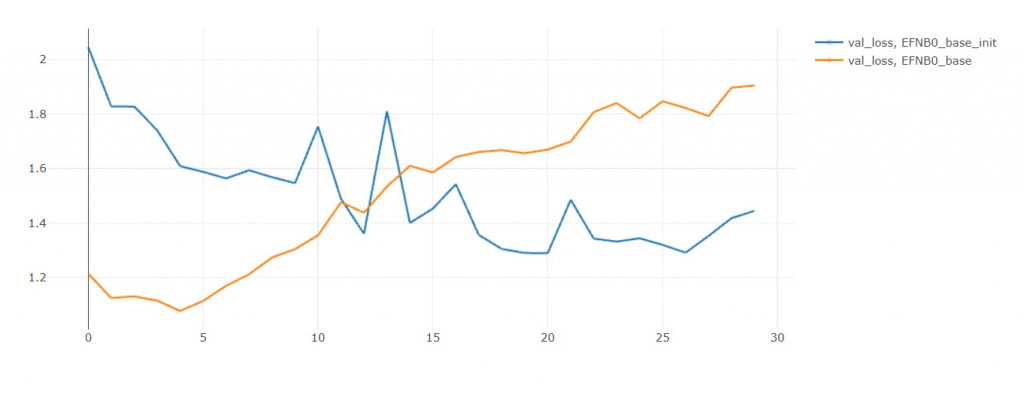
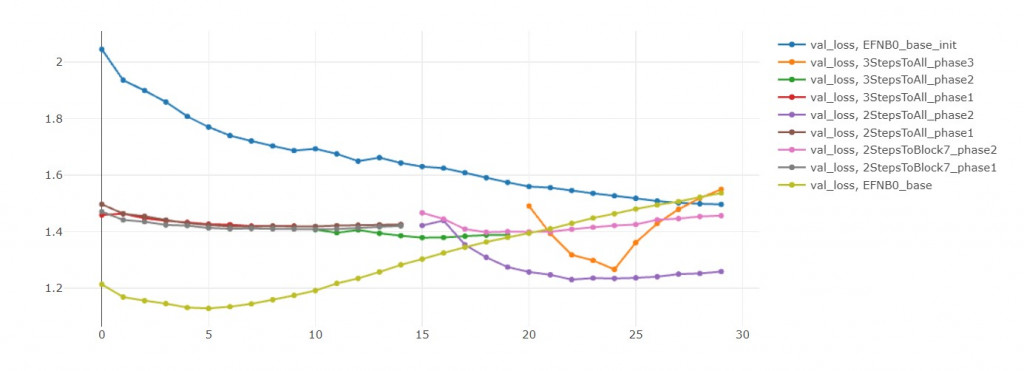
從val loss來看,初始模型比較沒有過擬合的問題。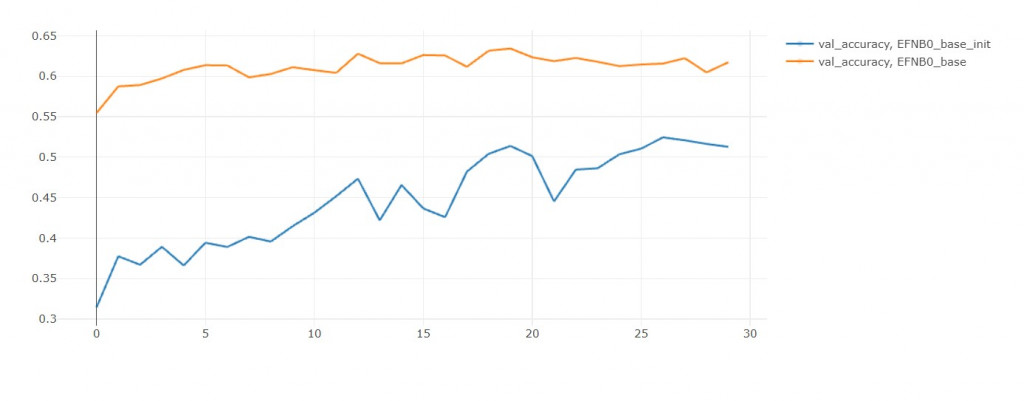
但是從 val accuracy來看,模型零有預訓練的優勢,準確率高不只一點。
我推斷只要給初始模型更多訓練輪數,
他能夠無限趨近於模型零,
但最後還是會過擬合,
所以不如一開始就用模型零!
這就是遷移學習的好處。
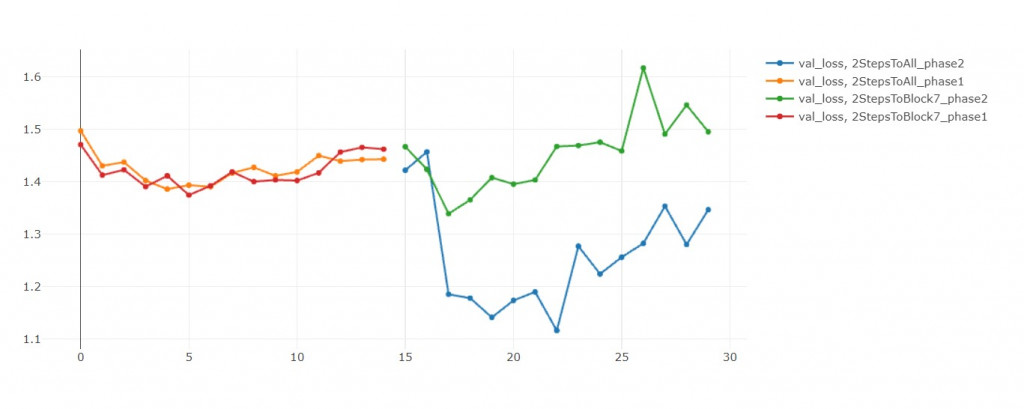
在前15輪中,兩者不相上下。
但後15輪中,模型二收斂的比較好,
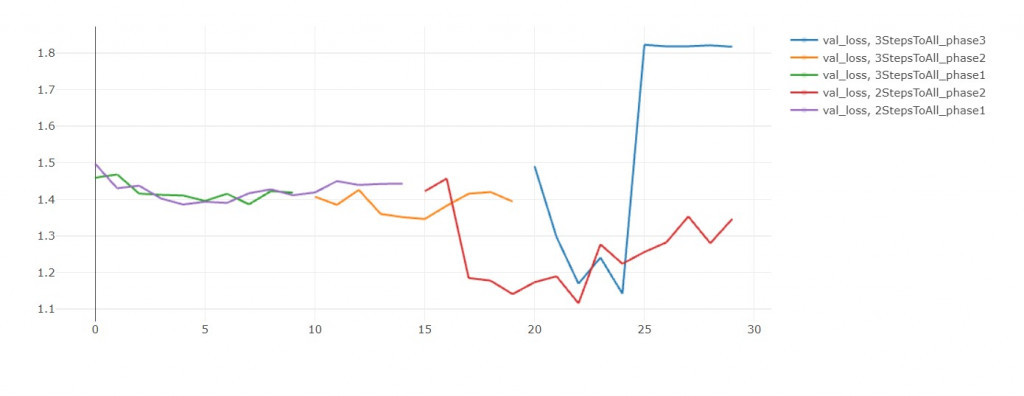
在第25輪,模型三的validation loss大幅上升。
我重複同樣實驗三次都得到這個結果。
我判斷是學習率太大,導致我跳出local minimum,
然後跳不回去了
如果沒有發生這種意外的話,模型三應當比較好才對

如果單純比較val acc,
那還是微調 Block-all 30輪勝出。
但這是不公平的,
因為每開放一個block,都應該要微調30輪才對。
但我為了節省時間,把總輪數設固定是30輪。
才讓兩段式學習看起來不如全直接部微調。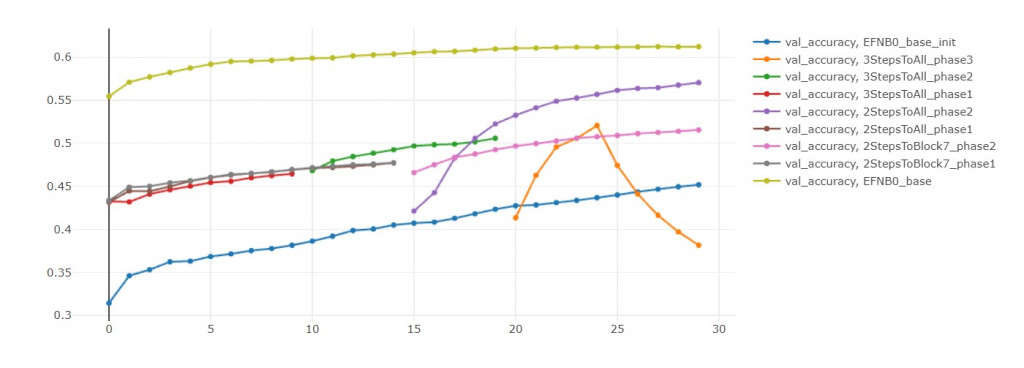
如果你觀察 val loss,會發現多階段訓練還是比較有潛力的(訓練更多輪)。
反之,看看EFN_base,
如果把模型都再訓練10輪,
EFN_base的損失值簡直快要飛上天和太陽肩並肩 = =