一. encoder
架構如下: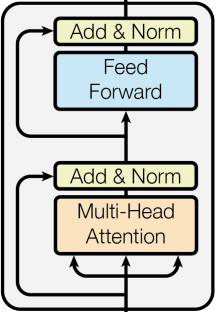
encoder的動作在於對input進行編碼,在一開始input會產生Q、K、V這三個矩陣,由上圖可知道,他會先進行多頭的self-attention得到新的一組編碼,這個地方他有多做一個處理就是殘差連接(Residual connection),這邊作者是用到 ResNet 的概念,能夠讓深度學習訓練更深的網路,避免造成梯度爆炸或梯度消失,公式如下:
Residual(x) = x + Sublayer(x)
就是將經過多頭 self-attention的值與原本input的值進行相加,以圖示來說如下: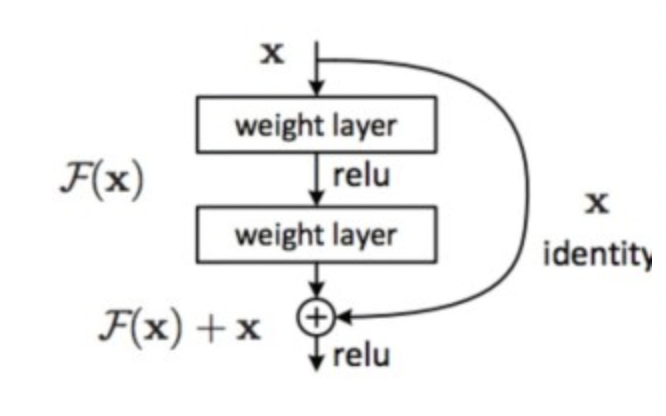
各位可以看上圖,他有一塊add&norm,add就是做上述的殘差相加,norm是Layer normalization,對每一層做正規化的意思(詳細部分未來再補QQ),最後殘差與正規化的公式如下:
Add & Norm(x) = LayerNorm(x + Sublayer(x))
在encoder的最後最後,會將K與V(兩者長一樣)傳給decoder,與decoder的Q做attention,明天會再介紹decoder的部分

