一. 介紹
transformer就是像前述介紹的,他就是一個seq2seq model,將一個序列轉成另一個序列,中間都是由前一天所說self-attention所構成的~~在2017年,google 提出了全部由attention所構成的nn模型的paper: “ATTENTION IS ALL YOU NEED”。這篇主要是處理機器翻譯的工作,並且做到比RNN與CNN的架構更好,各位可以去拜讀一下此paper[1]。
整體架構如下: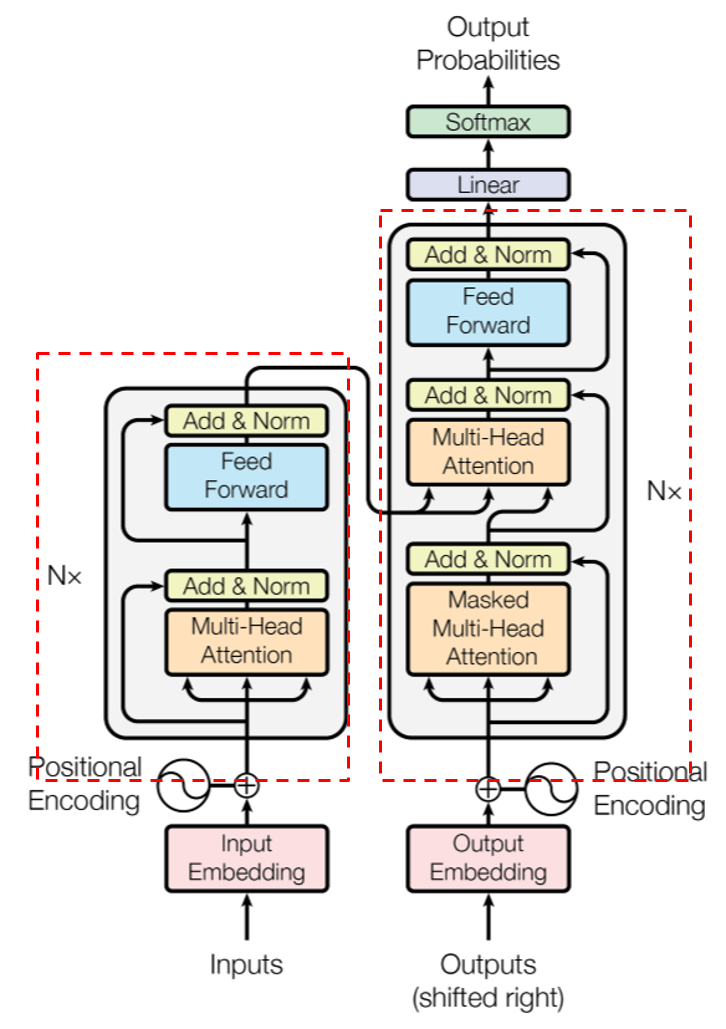
由2個部分組成,第一部分是multi-head-attention組成,第二部分是feed-forword network組成,這樣是一層encoder,在該論文中使用6層
第二部分只比第一部分多了一塊mask multi-head attention,為何會多一個mask呢,其實就是讓模型在訓練decoder的時候,不樣讓模型之後的輸出是甚麼,例如: ouput今天有一句話經斷詞後為[‘我’, ‘今天’, ‘很’, ‘帥’],他會依序進入decoder,所以第一個詞是'我',其用意就是看'我'這個詞與input的句子哪個詞最相關(也就是attention的用意),確保後續的詞並不會影響前面在訓練的詞。
那明明就有self-attention了,為何還要有Multi-head self-attention,這其實就是重複做attention的意思,下圖就是一個attention,就是昨天各位看到的最下面的計算流程: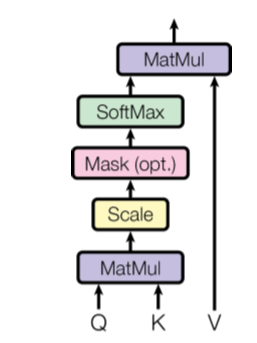
Multi-head就是多頭的意思,就是重複做attention,堆疊其來如下圖,主要就是想透過不同角度來擷取不同的特徵,這篇論文主要是有8個頭,也就是8個注意力機制: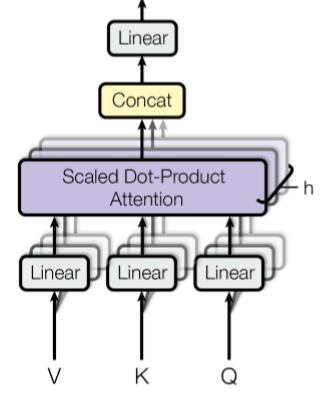
最後再把這8個的attention連起來,再經過一次線性轉換,得到最後文字/句子編碼
明天會開始慢慢介紹encoder與decoder的部分~
參考資訊
[1] https://ddoo8059.medium.com/transformer-%E7%90%86%E8%A7%A3-7a30ed23e6ed
[2] Vaswani, A., et al. “Attention Is All You Need. arXiv 2017.” arXiv preprint arXiv:1706.03762.

