一. decoder
架構如下: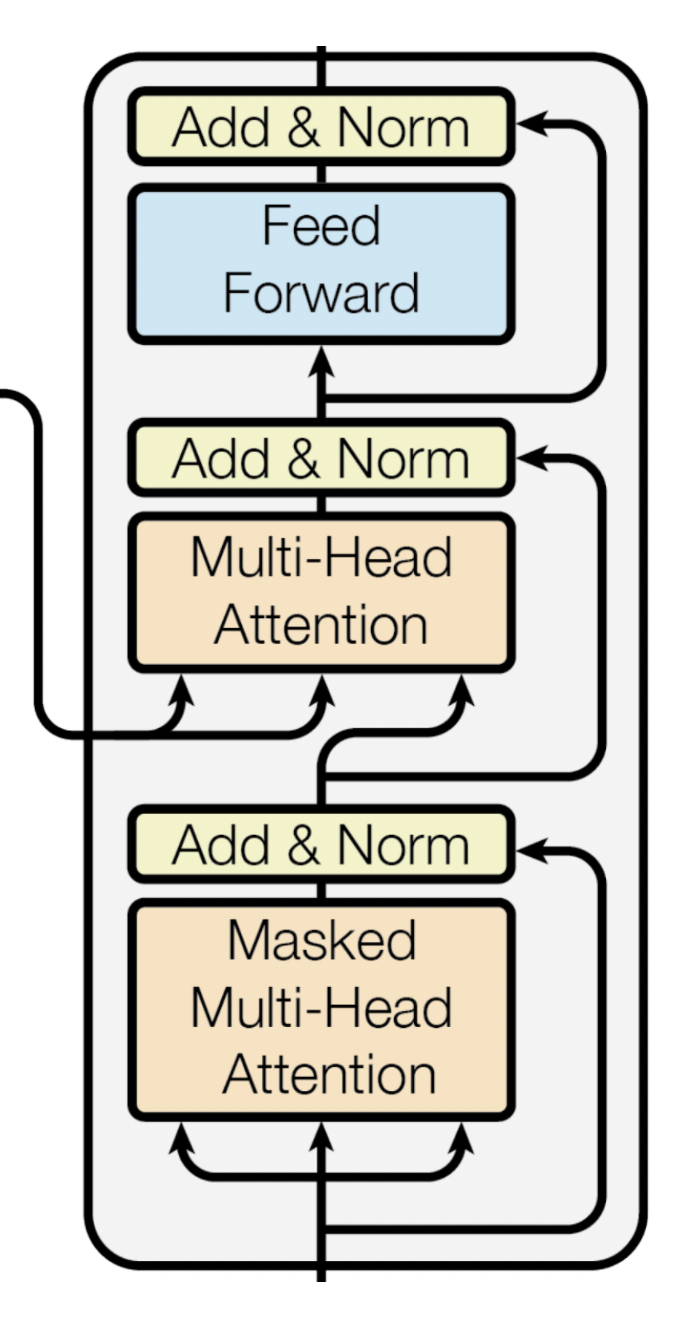
decoder主要是解析encoder的資訊,轉換成output的形式
decoder分成下面三個子層:
二. Masked Multi-head self-Attention Sublayer
各位應該很好奇為何第一個部分要有masked,因為transformer是一個生成式的模型,不能讓他知道後面的答案,以中英文翻譯為例子的話,假如encoder是處理中文的地方,decoder是處理翻譯英文的部分,假設英文是'Mary had a little lamb',那在一開始時,會先只給他encoder的資訊,看能不能產生Mary,在生成第二個字也就是'had'時會給decoder看'Mary',看能不能生成'had',那怎麼做mask,如下圖,會將不能給decoder看的字給他'0',只有1代表是目前decoder能使用的input,下圖是'NLP100天馬拉松的圖':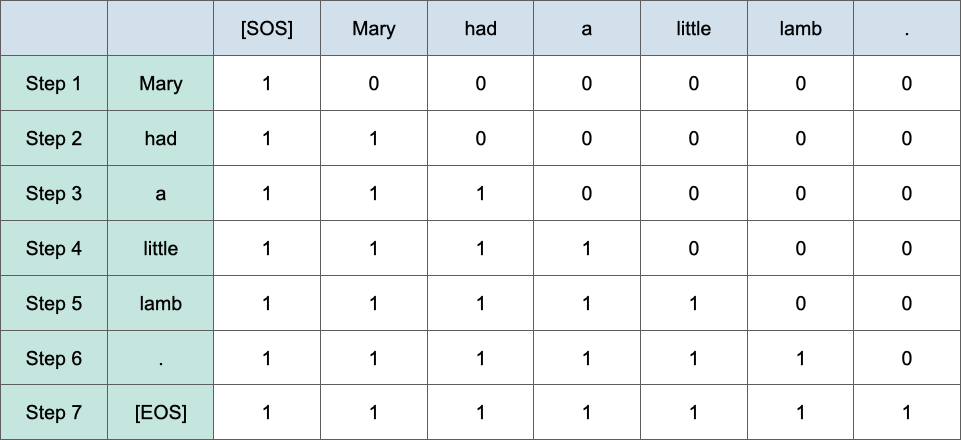
三. Multi-head encoder-decoder-Attention Sublayer
還記得前一天說的,encoder將k與v送至decoder,就是這一段,decoder經過Masked Multi-head self-Attention,產生的Q與encdoer做attention,就是要讓decoder學目前的輸入與encoder哪些資訊關聯性高,算法與self-attention是相同的,如下圖: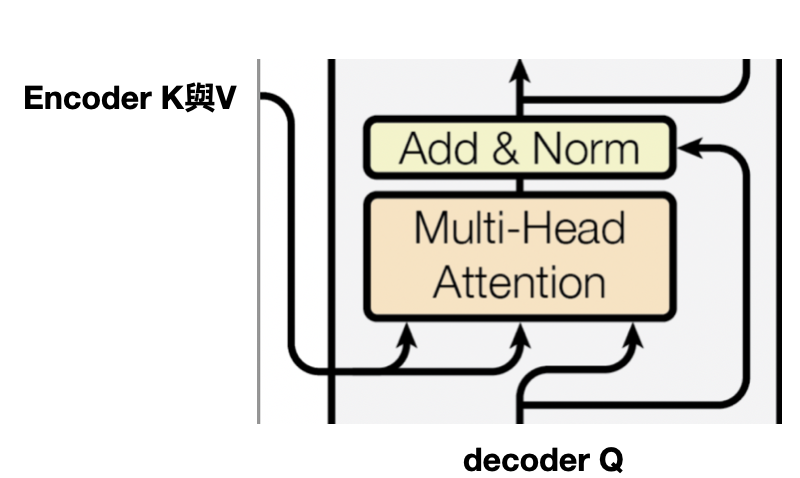
最後就是一層全連接層了,最後經過softmax預測最適合的翻譯詞~~
整體decoder的運作就是這樣~明天會以transformer實作中英文翻譯任務~

