
之前介紹產生Flux 的方法都是固定的遵循特定邏輯的,若今天有需要客製化特殊的邏輯來產生資料,Reactor提供了generate、create來動態的產生Flux。
只能一個接著一個產生資料,而且是同步的(synchronous),需要傳入兩個參數,第一個參數是初始值的supplier,第二個則是資料如何產生邏輯的generator,透過SynchronousSink來呼叫next()、error(Throwable) 或是 complete()。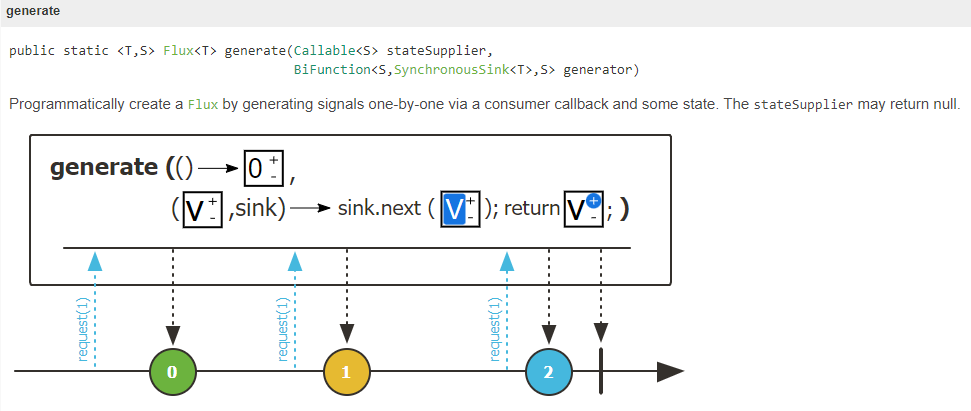
官方提供的範例,首先第一個參數初始化state為0,在generator裡面,根據state定義了如果產生資料(sink.next(...)),根據state定義何時結束(sink.complete()),並定義state改變的邏輯( state + 1),從output可以看到sink.next中產生的結果就是generator產生的資料,state ==5則結束
Flux<String> flux =
Flux.generate(
() -> 0,
(state, sink) -> {
sink.next("3 x " + state + " = " + 3 * state);
if (state == 5) sink.complete();
return state + 1;
});
flux.subscribe(System.out::println);
/*
3 x 0 = 0
3 x 1 = 3
3 x 2 = 6
3 x 3 = 9
3 x 4 = 12
3 x 5 = 15
*/
state也可以是可更改(mutable)的物件,每次產生資料的同時都會去修改state本身,而這邊還有傳入第三個參數是在最後會執行的Consumer,如果你的state跟DB連線有關或是其他的資源,適合用來清理與state有關的資料,從範例可以看出Consumer可以取得最後一次的state。
Flux<String> flux =
Flux.generate(
AtomicLong::new,
(state, sink) -> {
long i = state.getAndIncrement();
sink.next("3 x " + i + " = " + 3 * i);
if (i == 5) sink.complete();
return state;
},
(state) -> System.out.println("state: " + state));
flux.subscribe(System.out::println);
/*
3 x 0 = 0
3 x 1 = 3
3 x 2 = 6
3 x 3 = 9
3 x 4 = 12
3 x 5 = 15
state: 6
*/
一開始有說明只能一個接著一個,所以如果同時執行兩次 sink.next("3 x " + i + " = " + 3 * i);,就會拋出錯誤。
reactor.core.Exceptions$ErrorCallbackNotImplemented: java.lang.IllegalStateException: More than one call to onNext
Caused by: java.lang.IllegalStateException: More than one call to onNext
create是更進階動態產生Flux的方法,有別於generate一次只能產生一筆資料,create則適用於多筆,透過FluxSink來呼叫next()、error(Throwable) 或是 complete(),不需要透過state來控制邏輯。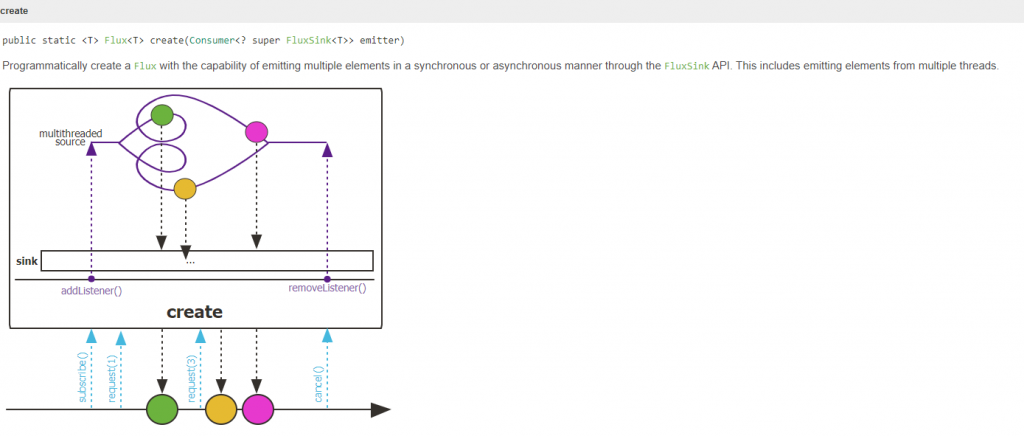
官方提供的範例,說明create適用於將現有已存在的api轉換為Flux,假設有一個監聽器有兩個method,一個是資料處理的邏輯(參數就是資料),另一個則是完成,這樣就可以透過create轉換為Flux,註冊監聽器後,每當資料累積後觸發onDataChunk就會將資料透過sink.next(s) 推送出去。
interface MyEventListener<T> {
void onDataChunk(List<T> chunk);
void processComplete();
}
Flux<String> bridge = Flux.create(sink -> {
myEventProcessor.register(
new MyEventListener<String>() {
public void onDataChunk(List<String> chunk) {
for(String s : chunk) {
sink.next(s);
}
}
public void processComplete() {
sink.complete();
}
});
});
由於create一次產生多筆,有別於generate的單筆,create產生資料的速度是無法預期的,也就是說有可能subscriber是來不及消化其所產生的資料,所以create可以多傳一個參數代表FluxSink.OverflowStrategy,有以下幾種策略:
IGNORE:完全無視下游的request,案照自己的節奏產生資料,有可能會導致IllegalStateException,ERROR:當消費不了publisher所產生資料的第一時間就會IllegalStateException,與IGNORE相似但更為極端,IGNORE本身可能會根據operators會有一些少少的buffer,還有一點點可能性不會發生錯誤。DROP:無法消化的資料都拋棄。LATEST:只保留最新的資料。BUFFER:預設使用,會將無法消化的資料保存,如果資料量差距太大有可能會導致OutOfMemoryError。Create GenerateFluxSink vs SynchronousSink
Consumer 只會執行一次且產生0至多筆資料 vs Consumer 執行多次每次只產生一筆資料OverflowStrategy vs 根據subscriber的要求來決定產生資料。如果能知道會有固定多少的資料量需要處理,可以考慮使用create,若來源資料是未知,使用generate可以透過狀態來控制處理邏輯會是更好的方式。
關於結論
如果能知道會有固定多少的資料量需要處理,可以考慮使用create,若來源資料是未知,使用generate可以透過狀態來控制處理邏輯會是更好的方式。
create跟generate這邊是不是寫相反了?
