先import各種會用到的套件
載入iris資料集
此載入iris方式我是使用別人提供的方法
此資料集包含六個欄位
Id ,不會用到,只是標明這是第幾個資料
SepalLengthCm,萼片長度,資料型態為浮點數,無缺失值
SepalWidthCm,萼片寬度,資料型態為浮點數,無缺失值
PetalLengthCm,花瓣長度,資料型態為浮點數,無缺失值
PetalWidthCm ,花瓣寬度,資料型態為浮點數,無缺失值
Species,花的種類,資料型態為物件,無缺失值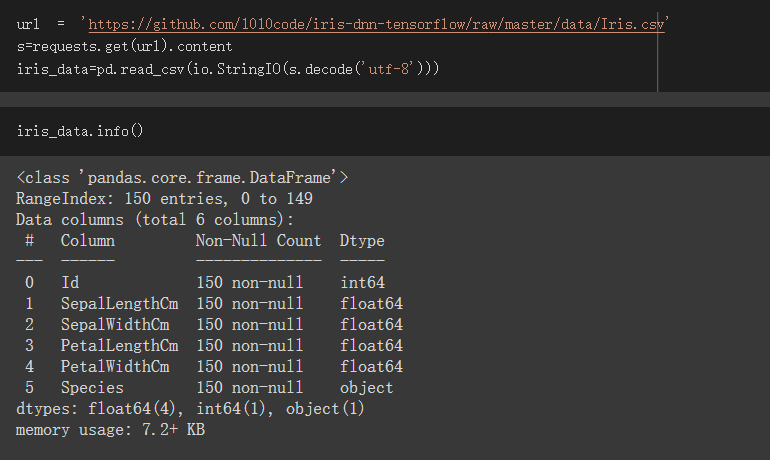
資料前處理
我們的訓練目標為Species欄位,可是它的資料型態是物件不是數值,所以無法拿下去train
使用sklearn.preprocessing中的LabelEncoder將其都轉為數字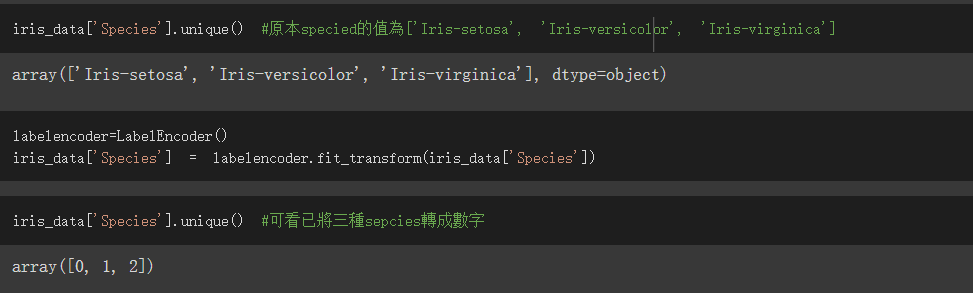
將pandas轉為numpy
使用dataframe索引將會用到的欄位轉為numpy
iris_x為我們的特徵值,iris_y為我們的訓練目標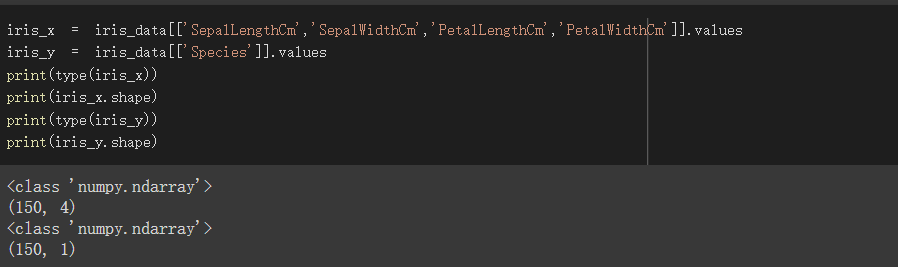
正規化
正規化特徵值,以利訓練模型
分成train_set與validate_set
使用sklearn.model_selection中的train_test_split
將資料分成訓練集、驗證集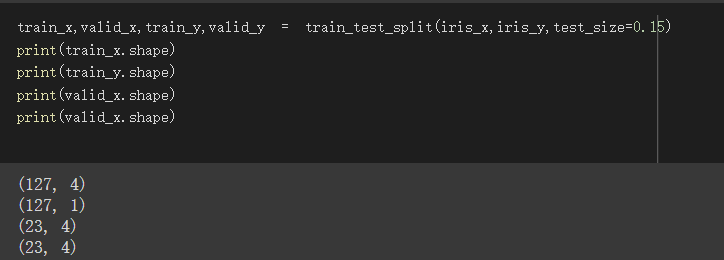
轉換成tensor
使用pytorch訓練前,記得將資料轉成tensor才可運算
x資料dtype設為float32,y資料dtype設為long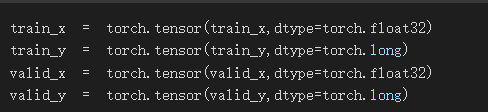
Dataset
DataLoader
model
模型的樣子隨便你怎麼設
要注意兩點:
第一個輸入必須與資料特徵值相同
輸出數需與資料要分成的類別數相同,我們要分成三種,所以設為3
criterion、epoch、optimizer、n_batch
大部分都與昨天的介紹相同
只有criterion不一樣,因為是分類模型,這裡使用了CrossEntropyLoss
pytorch的CrossEntropyLoss裡已經有內建softmax,所以我們的model不用自己加入softmax
訓練模型
這裡我只介紹與昨天不同的地方
criterion是CrossEntropyLoss,後面要放入的target資料dimension必須是1
label=label.view(-1),將y資料改成了dimension為1的樣子
with torch.no_grad(): 表示停止運算微分
其下面的程式碼在計算在train資料集的正確率
torch.max(pre,1)會送回每一行最大值及最大值的索引值
我們只需用到索引值所以pre前面為底線
n_sample總共有幾筆資料
n_correct預測正確的有幾筆資料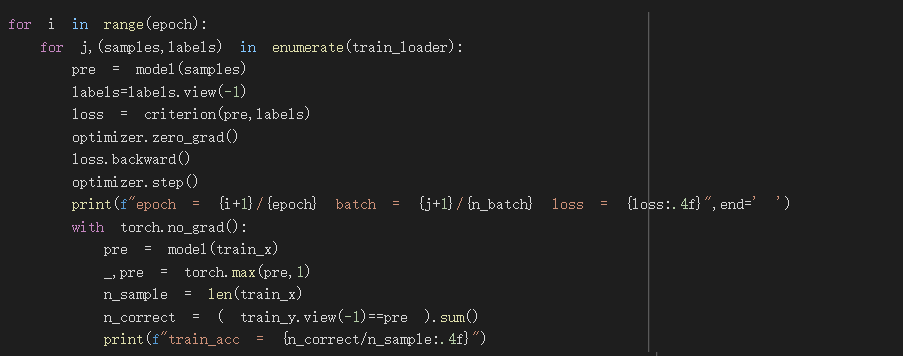
驗證集正確率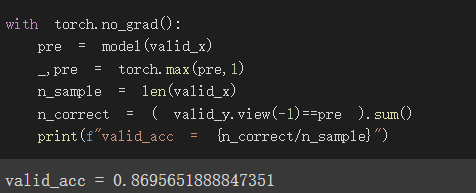
送上colab連結,可自行在上面多做點練習更加熟悉pytorch
https://colab.research.google.com/drive/1xDiomDrQSUEx79qYHTixelzSmMK7ho8C?usp=sharing


 iThome鐵人賽
iThome鐵人賽