
卷積神經網路(CNN)又被稱為 CNNs 或 ConvNets,它是目前深度神經網路(deep neural network)領域的發展主力,在圖片辨別上甚至可以做到比人類還精準的程度。如果要說有任何方法能不負大家對深度學習的期望,CNN 絕對是首選。
CNN 最棒的地方是在一步一步說明原理的情況下,它是個很好理解的演算法。所以以下我將為各位說明 CNN,也歡迎參考上方比圖片更詳細的影片。如果中間有什麼不懂的地方,只要點擊圖片,就能跳到影片中對應的說明。(資料參考)
CNN是一種特別的人工神經網路。CNN與傳統人工神經網路(ANN)最大的不同在於CNN自動執行特徵(feature)工程。傳統的ANN或者MLP由一層輸入層、一或多層隱藏層及一層輸出層所組成。CNN擁有一組附加層,被稱為卷積層(convolution layers)。輸入的圖片會先被輸入至第一層卷積層。卷積層的輸出會被給予至完全連結MLP的輸入層。卷積層對輸入圖像實行特徵(feature)工程(如提取與選擇特徵)的演算法。MLP實施傳統深度學習的演算法去分類圖片。
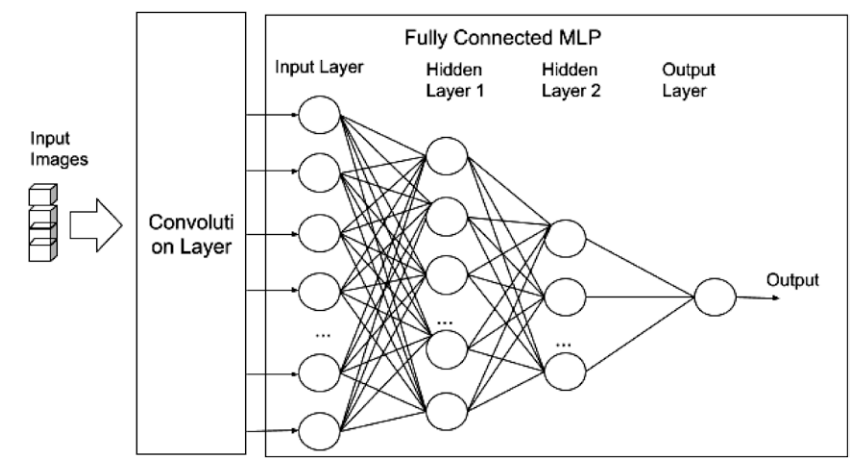
卷積層擁有兩個部分:
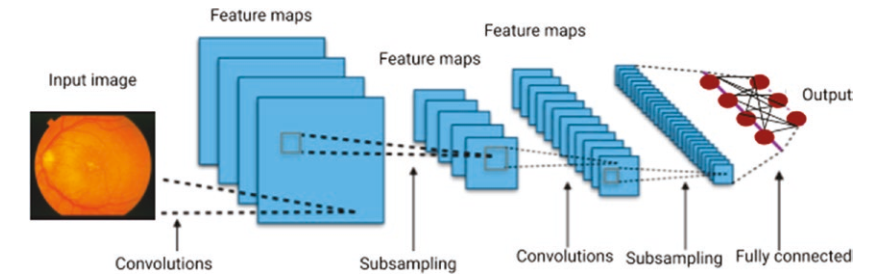
輸入圖像 (卷積) → Feature maps (二次抽樣) → Feature maps (卷積) → Feature maps (二次抽樣) → Output (完全連接)
電腦將單通道的黑白圖像視為像素值的2D矩陣,RGB通道的彩色圖像顯示為這些2D矩陣的堆疊。這些矩陣的堆疊組成了3D張量(tensor)
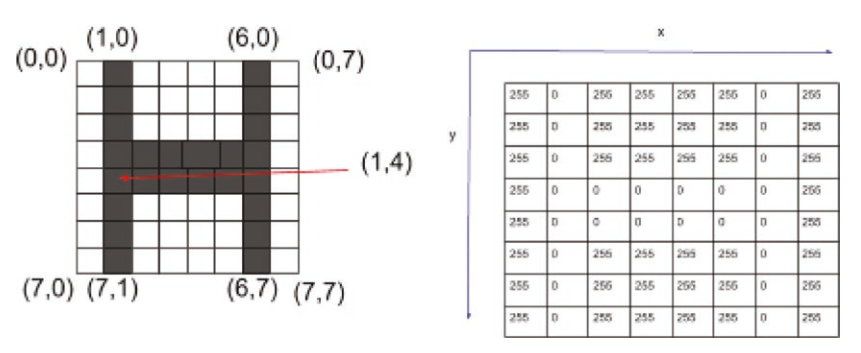
▲ 黑白圖像在電腦中被視為2D矩陣
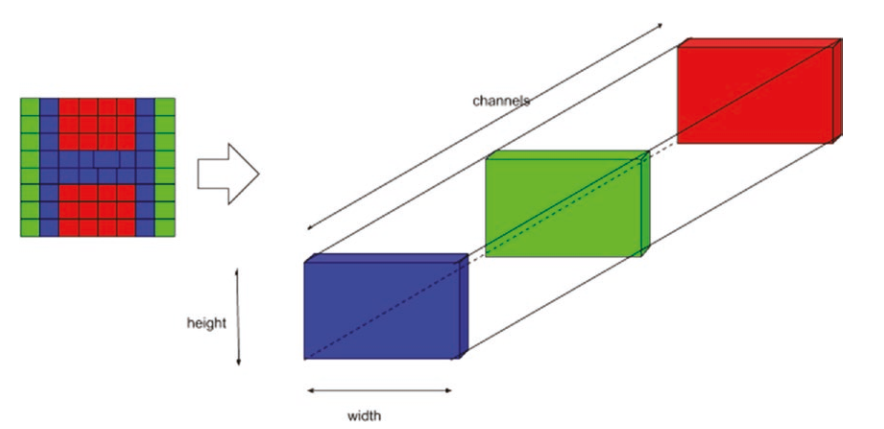
▲ 一個3D圖像張量的視覺呈現
下篇接續~
