神經網路是由多個神經元節點組成,每個神經元(Neuron)都擁有自己的權重w,表示在某項任務中該神經元的重要程度。假設輸入數據為x,
那麼預測值即為: prediction = wx + b (b是偏置量/偏差值)
訓練過程其實就是計算合適的w和b的過程。
那麼什麼才是合適的w和b呢? 答案就是與真實值相差不大的預測值。
例如定義損失函數如: loss = sum(|(y_ - prediction)|)
即真實值減去預測值,取絕對值後求和。訓練過程可以被粗略理解成調節w和b,使得loss盡可能變小。這就是優化器需要去做的事情,也就是優化器的作用。
優化器的主要目的都是為了訓練神經網路,而每個優化器的訓練速度上都有些差異,因此需要根據實際資料的狀況來決定使用什麼優化器。
我們主要介紹常常用到的三種優化器:
GradientDescentOptimizer為最基礎的梯度下降法優化器。此方法會利用所有樣本,因此他訓練時的速度會比較慢,但是只要能運作到一定的次數,他就能夠找到問題的最優解。
Momentum 在英文上的意思就是「運動量」的意思,此優化器就像是模擬物理動量的概念,有點像物理學中的球體運動時會受到先前的動量影響,在同方向的維度上學習速度會慢慢變快,但要調頭改變學習方向的話只能慢慢降速,直到停止後才能開始反向學習。
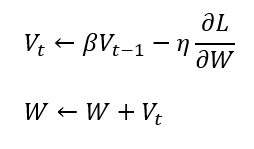
結合了Momentum和AdaGrad,保留了 Momentum 對過去梯度的方向做梯度速度調整與Adam對過去梯度的平方值做學習率的調整,動態調整每個參數的學習率,它對學習率有個約束,使得每次學習率都有個確定的範圍,會讓參數的更新較為平穩。他是目前最為館範使用的優化器。
資料參考:
https://www.zhihu.com/question/265516791

