前面23天講了這麼多,我們學會了numpy、pandas、seaborn、sklearn、pytorch
我想我們應該有足夠的能力可以開始做Titanic資料集了
直接進入正題
載入會使用到的套件
這些套件前面都有介紹過,如果有忘記的部分請回頭看一下前面的文章
載入資料集
在kaggle Titanic的網站即可下載到資料集,分為train.csv、test.csv、gender_submission.csv
train.csv為訓練用資料,包含要訓練的label
test.csv為測驗資料,不包含label
gender_submission.csv為繳交範例資料,不會用到所以沒有載入
查看資料集狀況
test資料有11個欄位,train資料則有12欄位,多了個Survived的欄位,此欄位就是我們要預測的值
可看出test_data、train_data都有些缺失值且各資料型態也都不太一樣
所以我們要做一些前處理的工作來解決此問題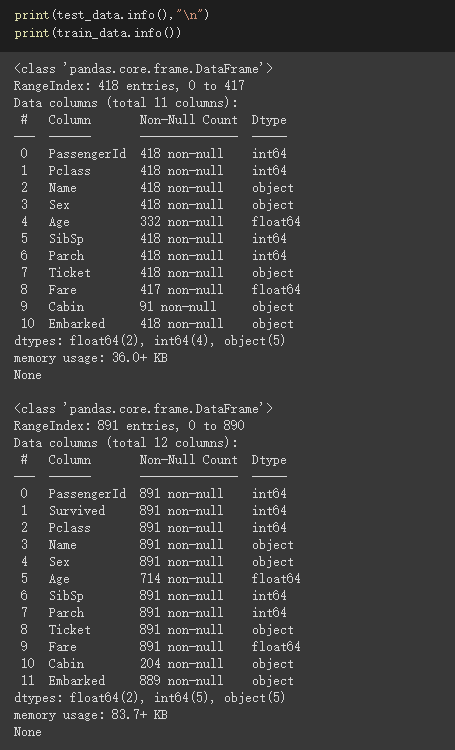
資料探勘與前處理
資料合併處理:
建立一個DataFrame並命名為total_data
利用append方法將train_data、test_tada都放入total_data
將train_data、test_data合併後一起做前處理比較方便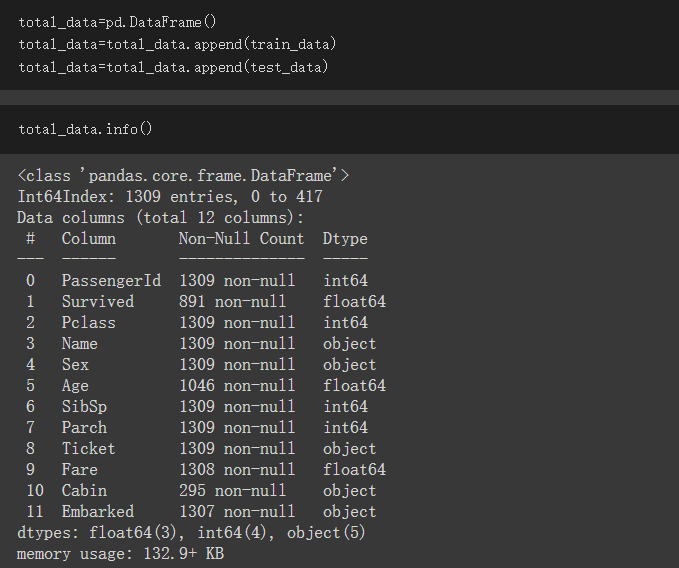
注意:之後資料做視覺化時,我都會用train_data來做,不會用test_data,因為train_data資料包含Survived欄位,且我們在訓練資料時,應配合train_data的狀況來使用
PassengerId欄位:
此欄位的資料為乘客的資料ID,依據順序排列,對於訓練資料沒有用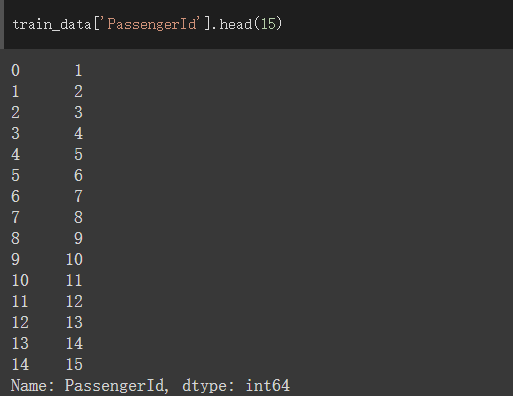
Survived欄位:
此欄位來記錄乘客有無生存,0代表無,1代表存活,為我們要預測的欄位
total_data['Survived'].unique()可看出裡面包含三種資料0、1、空值
此空值是因為test_data沒有此欄位
使用seaborn的countplot來看有無生存的資料個數
可看出生存的人數略少於沒有生存的人數,差距不會到太大,不會使訓練資料不平衡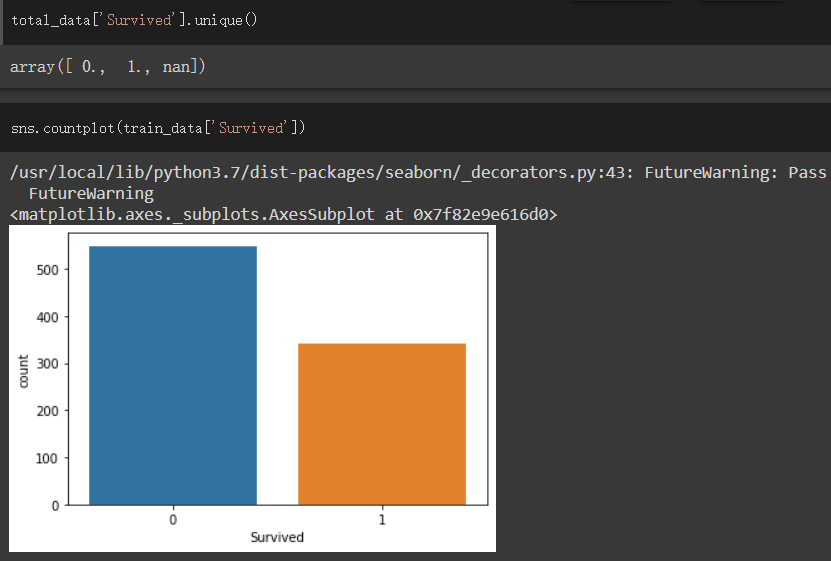
Pclass欄位:
此欄位表示艙等,分為1、2、3三種,1為最好,3為最差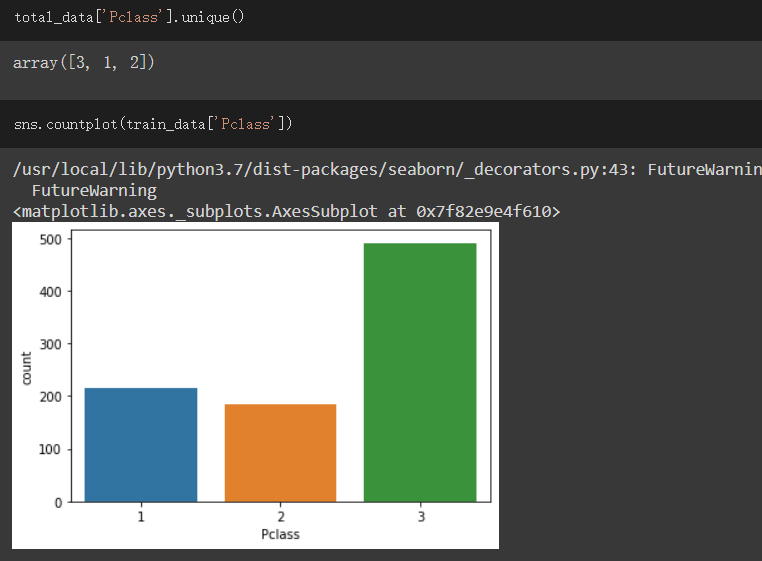
依據Pclass與Survived做資料視覺化
可看出艙等愈好生存率愈高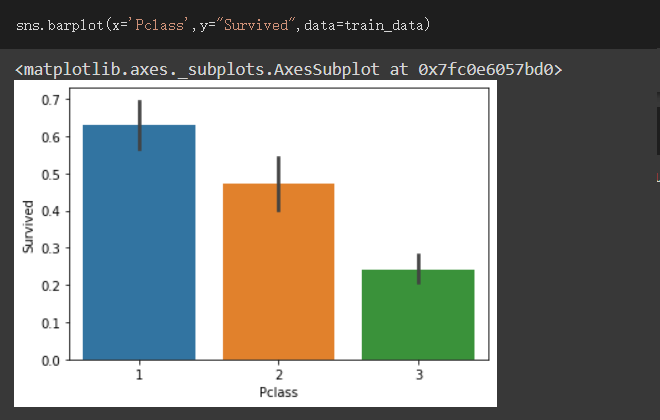
Name欄位:
此欄位為各乘客的名字,這裡我們不會使用到
Sex欄位:
表示性別,male、female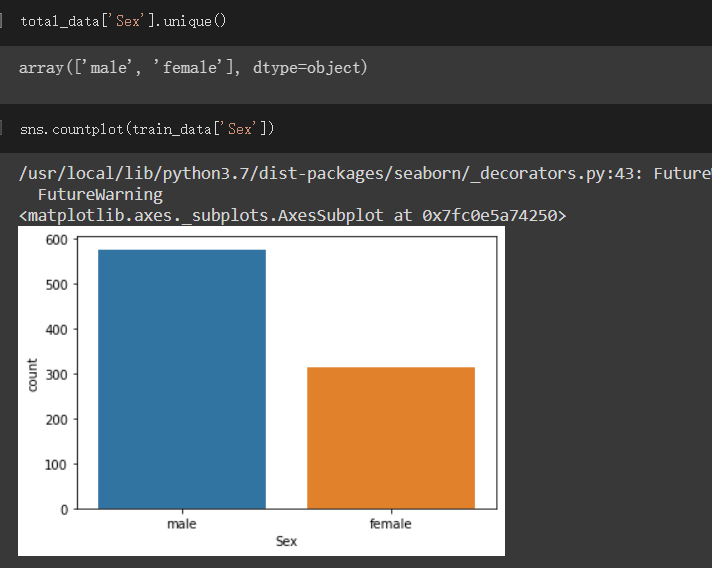
因為male、female都不是數值,我們必須將它們轉為數值才能拿下去train
這邊使用LabelEncoded解決此問題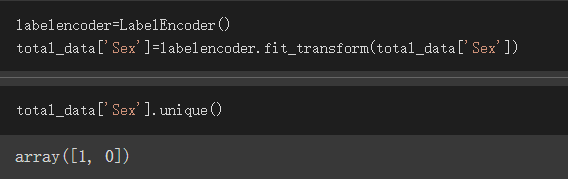
Age欄位:
表示乘客的年齡
透過total_data.info()可看出此欄位有不少缺失值,等等觀察完資料要思考要用什麼值去填補缺失值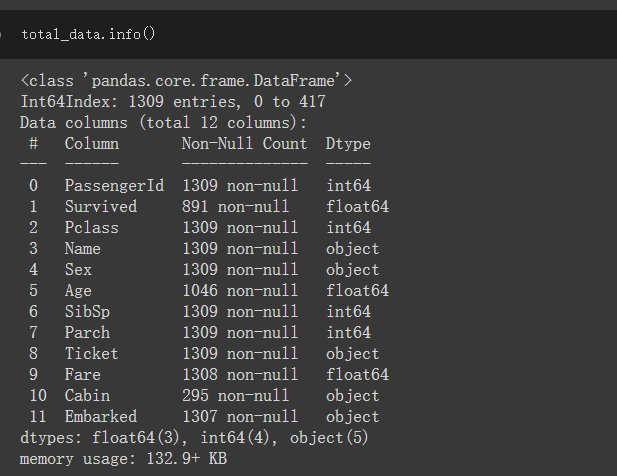
因為年齡為連續性的資料,我透過DataFrame的qcut方法來對資料進行分組
qcut第一個參數傳入要進行動作的欄位,後面填入要分成幾組,之後會根據資料的比例平均分組
例如:如果我填入4,資料就會分為0%~25%、25%~50%、50%~75%、75%~100%,而這邊我分為8組
並將結果傳入新的欄位,此欄位命名為Age_qcut
之後進行資料視覺化
可看出0~16的區間生存機率有比較高,而其他都還算平均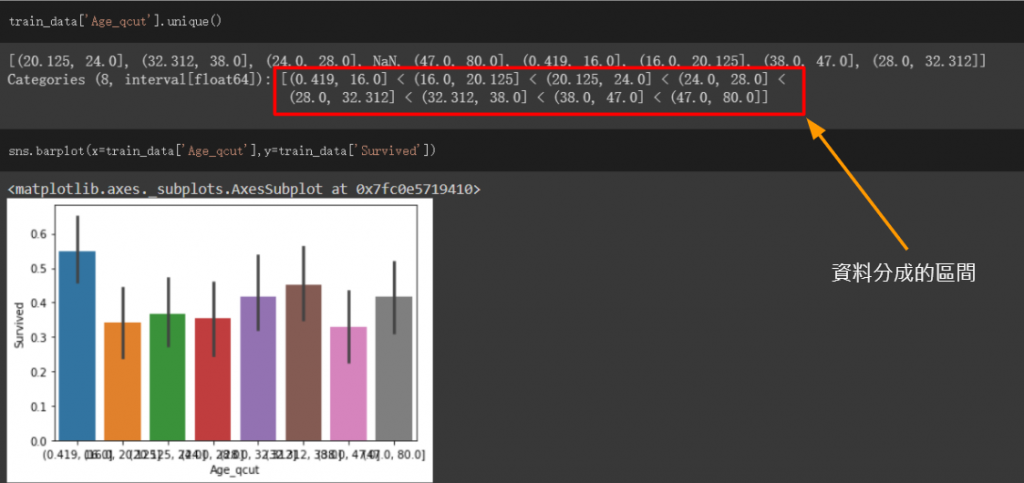
觀察原資料分布情形
發現大部分資料大概都位於15到40之間,其他部分都還好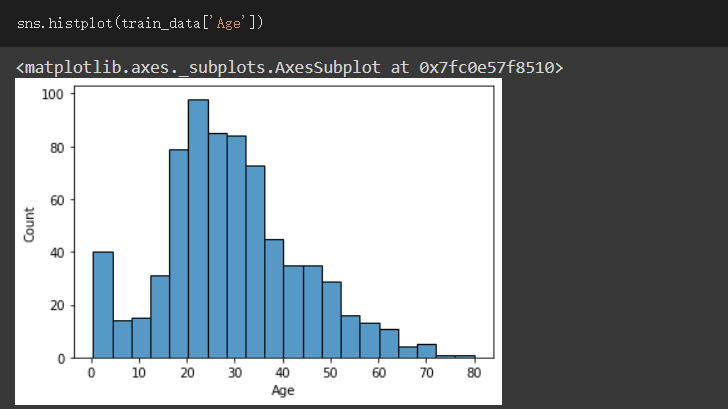
根據以上的觀察
我將Age<=16的資料設為1
其他都設為2,表示空值也跟著被設為2,把空值也設為2是因為如果設成1會提高生存機率,但我們有不少的缺失值,怕把樣補充會影響到資料的預測結果
為什麼我會這麼做呢?因為根據觀察,小於等於16歲的生存率有比較高,且資料分部在那部分的數量也不會太少
所以把這當作一個特徵
今天先講到這裡,明天會把剩下的欄位講完
這裡先放上整個資料處理及訓練過程
https://colab.research.google.com/drive/1l--rkdk0sCxrEAGyETSxFCMrJmS147tX?usp=sharing


 iThome鐵人賽
iThome鐵人賽