延續昨天的介紹
我們已經處理、介紹過的欄位有:PassengerId、Survived、Name、Pclass、Sex、Age
SibSp欄位:
此欄位表示兄弟姐妹或配偶的數量
先觀察各值的數量
SibSp等於0的資料佔據大多數,SibSp等於1的資料有200左右,其餘都很少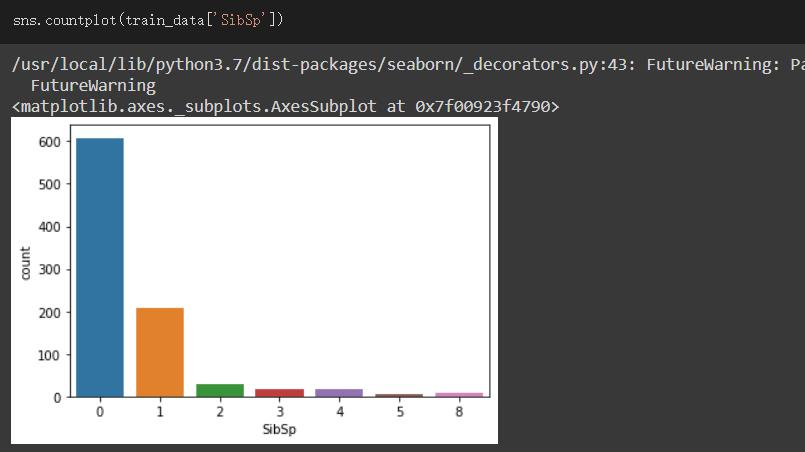
觀察SibSp與Survived的關係
我們發現SibSp在等於1、2時生存率比較高,SibSp等於0時生存率還好
SibSp大於2時生存率都變低
根據以上兩個視覺化觀察結果
我決定將SibSp等於1、2為一個特徵,將其值設為1
SibSp大於2為一個特徵,將其值設為2
SibSp等於0為一個特徵,將其值設為0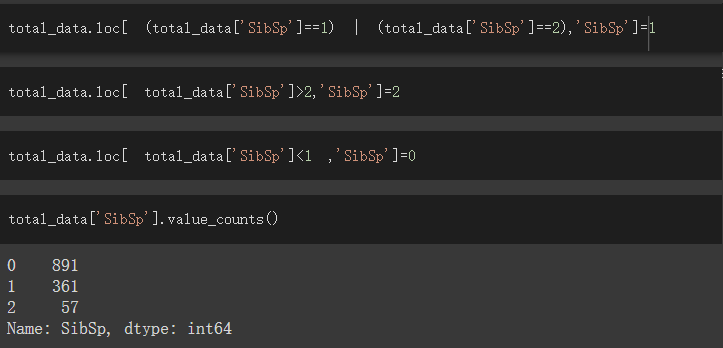
Parch欄位:
此欄位表示父母或孩子的數量
查看各值的數量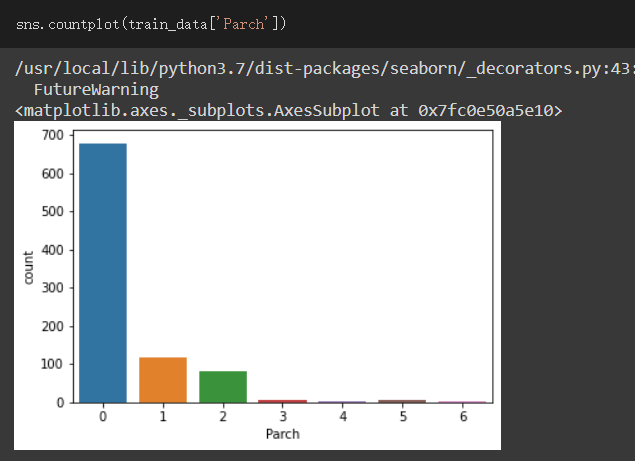
觀察Parch與Survived的關係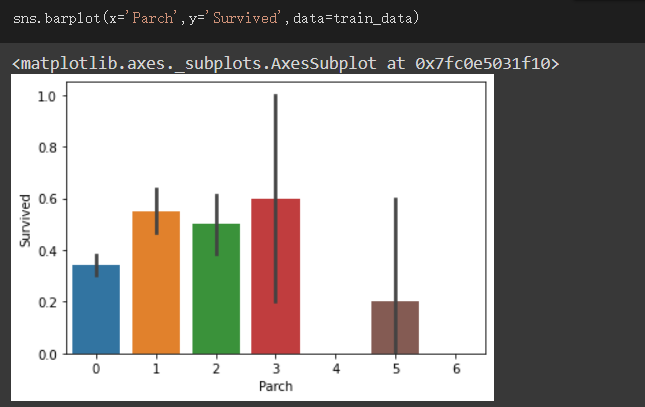
我們可以發現Parch等於0的值佔了非常多數,其次是1、2
其餘的少得可憐
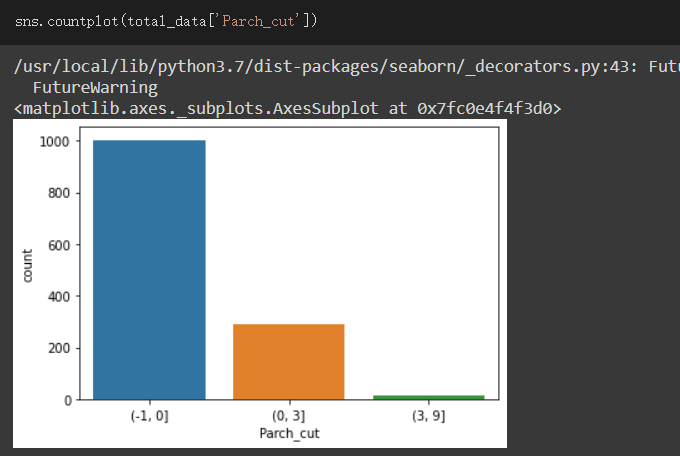
所以我們藉由cut方法重新分組來視覺化
與qcut不一樣的是,是藉由自己輸入的區間來分組,而qcut是依照資料比例來分組
cut使用方法前面傳入欄位,後面傳入想分成的區間,以我傳入的區間來說明
分成了(-1,0 ] , (0,3 ] , (3,9 ]
之後觀察與Survived的關係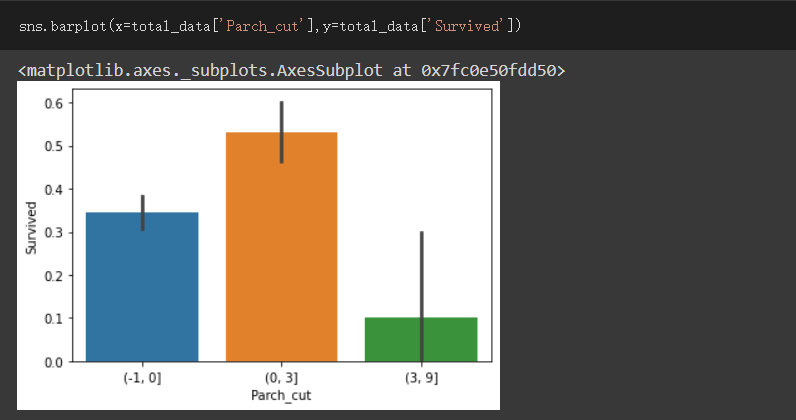
根據此區間的觀察結果
我將(-1,0 ]區間設為1,(0,3 ]區間設為2,(3,9 ]區間設為4
(-1,0 ]區間與(0,3 ]區間的資料數還算多,且對照Survived有不同的結果,所以把此兩個設為特徵
(3,9 ]的資料數太少,所以另外設成一個特徵
Ticket:欄位
此欄位為船票編號,這個欄位我不考慮使用
Fare欄位:
此欄位表示個乘客的票價,因為連續性資料,使用長條圖視覺化,並依據有無生存顯示不同顏色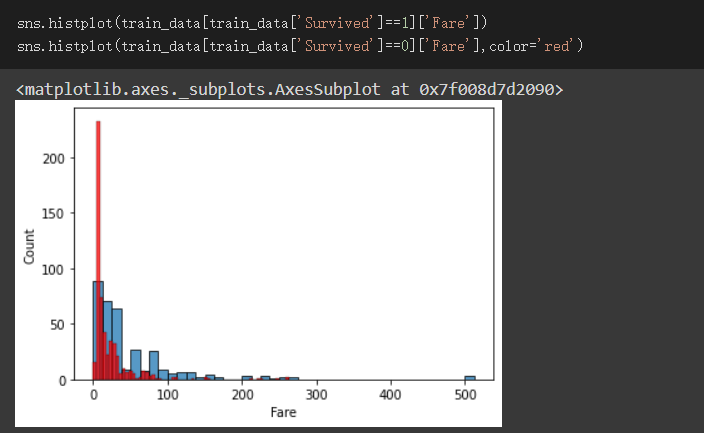
根據觀察結果,我設成了三種區間(-1,15 ],(15,50 ],(50,1000 ]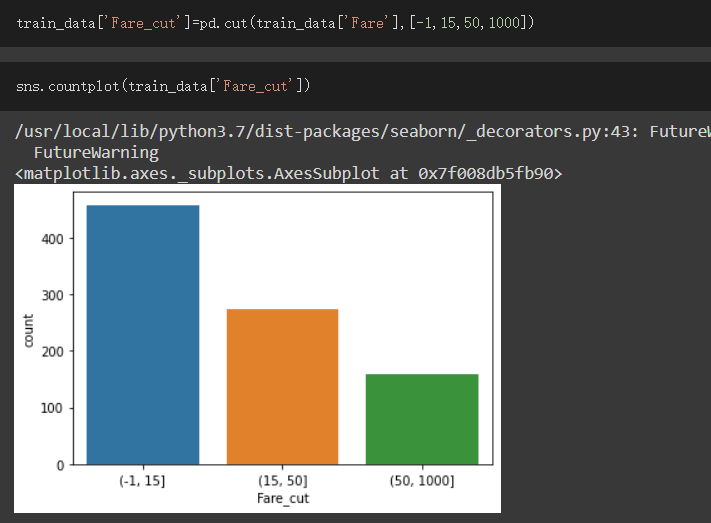
可看出此三種區間對於Survived的關係能呈現鑑別度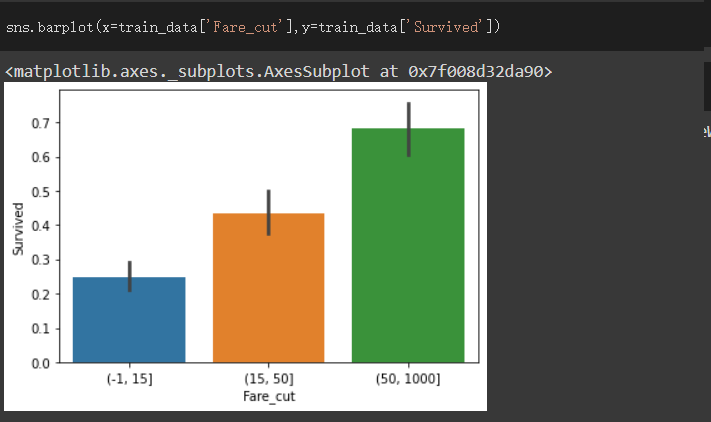
(-1,15 ]區間設為1,(15,50 ]區間設為2,其餘設為3
從total_data.info()可看出Fare資料有一個缺失值,我使用fillna補充缺失值
我以1來補充缺失值,因為1為眾數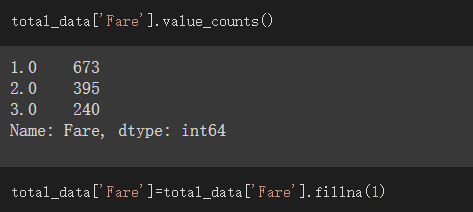
Cabin欄位:
此欄位為船艙號碼,超級多缺失直,這個欄位我不考慮使用
Embarked欄位:
此欄位表示登船的位置,從total_data.info()可看出有2個缺失值,其值有S、C、Q三種
觀察資料個數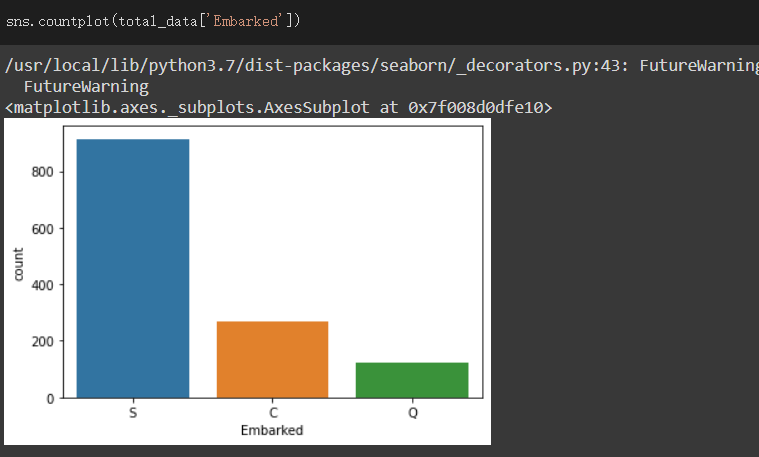
觀察Embarked與Survived的關係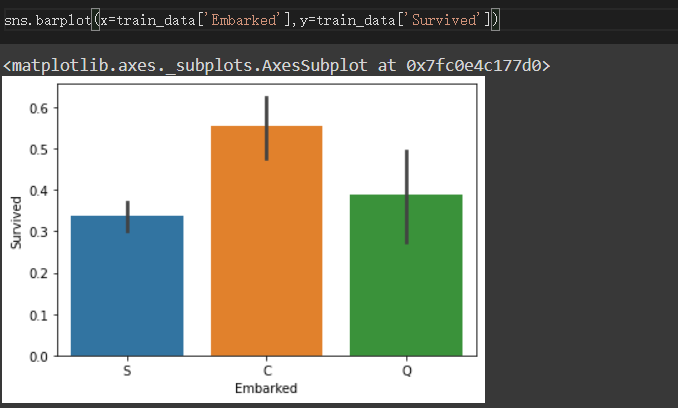
缺失值以S來補充,因為S為眾數
把此欄位做labelencoder轉成數字,才能拿去train
終於把全部欄位處理好了,所以說阿~資料前處理真是麻煩的工作,網路上許多文章都顯示,大部分資料科學家在訓練模型時8成的時間都在資料前處理,只花2成的時間在訓練model、調整參數
這裡先放上整個資料處理及訓練過程
https://colab.research.google.com/drive/1l--rkdk0sCxrEAGyETSxFCMrJmS147tX?usp=sharing


 iThome鐵人賽
iThome鐵人賽