此CNN非彼CNN
卷積神經網路 (Convolutional Neural Network),通稱CNN,
是一個在電腦視覺領域中,接觸到神經網路模型,
一定會聽到或用到的一個網路架構。
在理解孿生網路與實際應用之前,先來快速了解蹶積神經網路吧!
顧名思義,是由卷積 (Convolution)這個功能組成的神經網路。
那什麼是卷積?
對兩個同樣大小的矩陣的每個對應位置求乘積,最後再求總和
因此如果是兩個3 x 3的矩陣做卷積,就會得到1個結果;
如果是一個5 x 5的矩陣與3 x 3的矩陣做卷積呢?
答案是一個3 x 3的矩陣
用圖來看就長這樣:
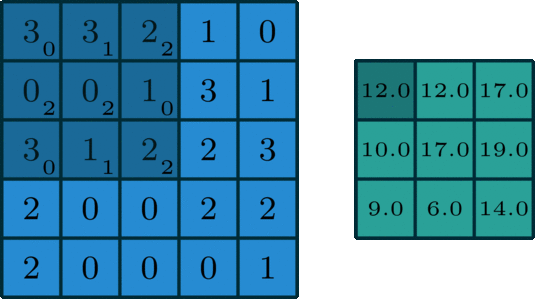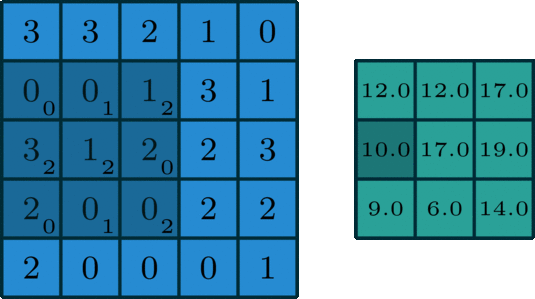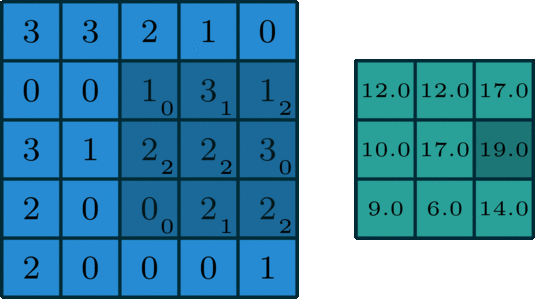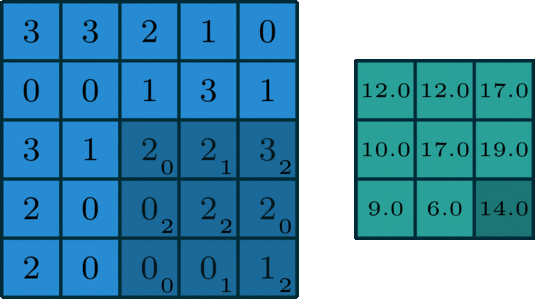
reference: towards: Intuitively Understanding Convolutions for Deep Learning
那這個能做什麼呢?
也因為卷積可以做出這些影像處理,反過來說,我們可以讓神經網路"學習"如何去做這些圖片操作與辨別。
CNN已經有專業邦友的介紹了,這裡就不多加闡述。
由於CNN只是一個神經網路架構概念,在這個概念下的神經網路有 (依照年代前後):
...等等不勝枚舉。
當然,我們也會選一個CNN來作為實作我們的孿生網路。
回到孿生網路,昨天提到孿生網路 (siamese networks)是一種神經網路架構,
它的架構大概可以用下面的圖來說明: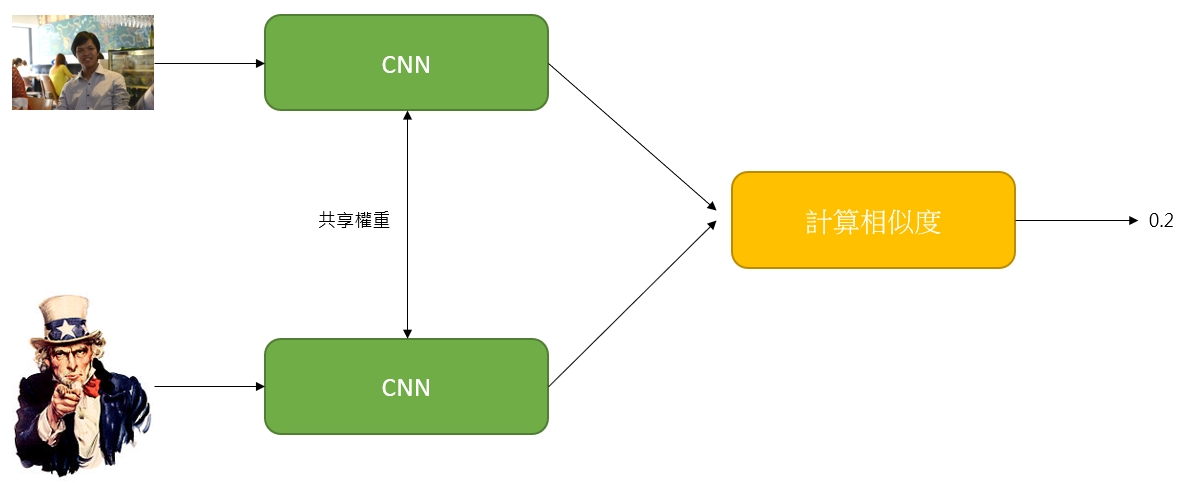
透過結合兩個一模一樣的CNN網路,彼此在訓練過程會共享權重(weights),可以得到一個模型用來
這也就是明天我們要用的孿生網路做人臉辨識的做法囉!

