已經準備進入鐵人賽的尾巴,所以這一篇就來介紹一個很常見的套件,也就是 BeautifulSoup,而這套件也是爬蟲很常使用的套件,所以接下來就讓我們來學習使用 BeautifulSoup 吧。
Python 很常被用於網路爬蟲,其中最多人用的就是 BeautifulSoup 套件,那...BeautifulSoup 套件是什麼東西呢?
這邊就讓我們直接看維基百科對於 BeautifulSoup 的說明:
Beautiful Soup是一個Python包,功能包括解析HTML、XML文件、修復含有未閉合標籤等錯誤的文件(此種文件常被稱為tag soup)。這個擴充包為待解析的頁面建立一棵樹,以便提取其中的資料,這在網路資料採集時非常有用。
透過上面解釋我們可以粗略知道 BeautifulSoup 主要是幫我們解析下載回來的 HTML 檔案套件,使用這個套件可以大大方便我們在擷取特定片段資料的方便性。
oh!對了,如果你有去查過 BeautifulSoup 的話,你會發現它的封面圖會是一個中世紀風格的圖片,而且你會發現它的圖片很特別:

而 BeautifulSoup 這個名字是來自愛麗絲夢遊仙境的一首詩所命名的,所以有些翻譯文檔甚至會說這是一份「愛麗絲的文件」,這也就是為什麼 BeautifulSoup 套件封面圖片都會是中世紀的風格,畢竟愛麗絲夢遊仙境當時的背景設定是在中世紀歐洲(如果沒記錯的話)。
那前面這邊一開始只是簡單小聊一下 BeautifulSoup 套件有趣的地方,接下來就讓我們準備開始安裝 BeautifulSoup 吧!
BeautifulSoup 在安裝上跟 Requests 套件較不同,比較不用擔心在 Python2 或是 Python3 版本上的套件名稱不同,因為在安裝 BeautifulSoup 的過程,都是相同的名稱。
Python2:
pip install beautifulsoup4
Python3:
pip3 install beautifulsoup4
當你安裝完畢之後,你可以先引入 BeautifulSoup 套件到你的 Python 專案中,但是這邊有一個很特別地方,BeautifulSoup 在安裝的時候,模組名稱會是 bs4 ,所以通常我們在引入 BeautifulSoup 時都會重新命名一下:
from bs4 import BeautifulSoup # 這絕對不是你想像中的 Bootstrap4
還是在提醒一次,這邊的 bs4 絕對不是 Bootstrap4 而是 BeautifulSoup4!(很重要)

接下來你可以嘗試貼入官方所提供的範例程式碼,而這又稱之為愛麗絲文件:
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head><body><p class="title"><b>The Dormouse's story</b></p><p class="story">Once upon a time there were three little sisters; and their names were<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;and they lived at the bottom of a well.</p><p class="story">...</p>
"""
那麼我們可以看到上面的 HTML 是被壓縮過的,因此是非常難以閱讀的,但是 BeautifulSoup 它可以將壓縮過的 HTML 結構轉換成標準的 HTML 縮排形式,也就是身為前端工程師可以讀懂的格式,而用法也非常簡單,只需要這樣寫就可以囉
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head><body><p class="title"><b>The Dormouse's story</b></p><p class="story">Once upon a time there were three little sisters; and their names were<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;and they lived at the bottom of a well.</p><p class="story">...</p>
"""
soup = BeautifulSoup(html_doc, 'html.parser')
print(soup.prettify())
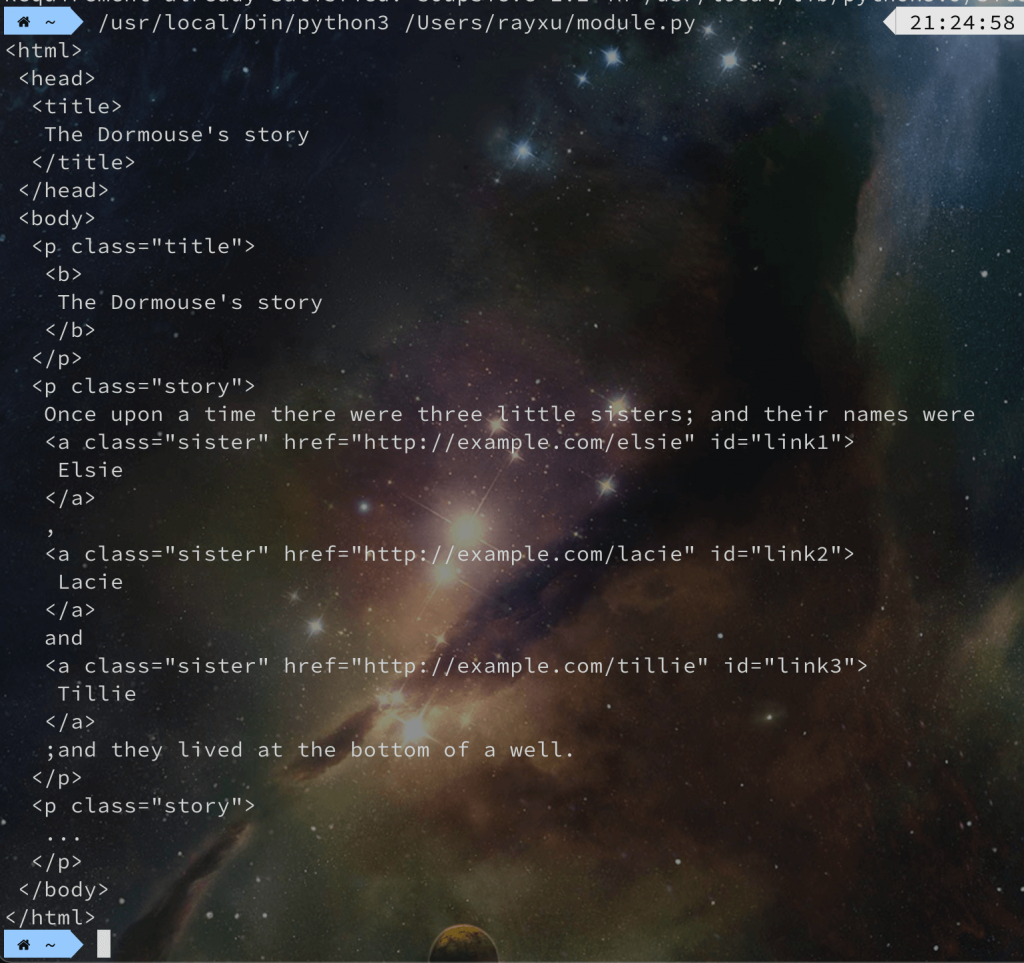
那這邊我們可以看到其中一行是 soup = BeautifulSoup(html_doc, 'html.parser') 這一行的第二個參數其實是告訴 BeautifulSoup 要使用哪一種解析器來解析 HTML,基本上在官方網站上都有說明建議你使用哪一種解析器,以官方建議來講,會建議你使用 lxml 的解析器,如果你要使用這個解析器的話就必須額外安裝:
pip3 install lxml
安裝完畢之後記得調整一下解析器:
soup = BeautifulSoup(html_doc, 'lxml')
最後你可以看到 print() 輸出一個非常標準且整理過的 HTML,或許終端機你會覺得很難閱讀,所以你也可以使用前面所學到的檔案寫入這個技巧來生成一個 HTML 檔案:
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head><body><p class="title"><b>The Dormouse's story</b></p><p class="story">Once upon a time there were three little sisters; and their names were<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;and they lived at the bottom of a well.</p><p class="story">...</p>
"""
soup = BeautifulSoup(html_doc, 'lxml')
f = open('index.html', 'w')
f.write(soup.prettify())
f.close()
屆時你再去打開 index.html 就會很好閱讀了,畢竟你是一名前端工程師對吧?

那麼基本上我們所有的操作都會跟 BeautifulSoup(html_doc, 'html.parser') 處理後的 soup 操作有關,舉例你想取得 HTML 結構中的 title:
print(soup.title) # <title>The Dormouse's story</title>
那麼 BeautifulSoup 還有哪些東西呢?這邊就讓我們繼續了解它吧!
BeautifulSoup 提供相當多的方法可以針對 HTML 標籤去搜尋,那這邊也讓我們每一個都嘗試看看。
find_all() 可以用於搜尋複數的 HTML 元素:
print(soup.find_all('a')) # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
其中 find_all 也可以針對 HTML 的屬性來搜尋:
print(soup.find_all('a', { 'id': 'link3' })) # [<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
那麼有特別針對 HTML 元素搜尋的方式,也就會有特別針對 CSS 選擇器的方式搜尋 HTML 元素,首先是針對 ID 的方式:
print(soup.select('#link1')) # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
另一種則是針對 class 搜尋:
print(soup.select('.story')) # [<p class="story">Once upon a time there were three little sisters; and their names were<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;and they lived at the bottom of a well.</p>, <p class="story">...</p>]
oh!題外話一下,select 也可以直接針對 HTMl 標籤搜尋唷
print(soup.select('b')) # [<b>The Dormouse's story</b>]
find() 雖然跟 find 感覺很像,但是它主要是回傳一個符合條件的元素:
print(soup.find_all('a')) # <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
select_one() 從名稱來講也很明顯的知道跟 find 很像,只會回傳第一個符合的元素:
print(soup.select('.story')) # print(soup.select_one('.story')) # <p class="story">Once upon a time there were three little sisters; and their names were<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;and they lived at the bottom of a well.</p>
前面我們知道如何取得我們要的元素之後,那該怎麼取出 HTML 元素中的東西呢?例如取出 HTML 元素中的文字,舉例來講 <b>The Dormouse's story</b> 中的 The Dormouse's story 這一段文字。
那這邊將會使用前面的這一段範例:
print(soup.find_all('a')) # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
這個語法非常簡單,可以直接取出 HTML 的文字:
print(soup.find_all('a')[0].text) # Elsie
接下來是如果你想要取出 HTML 的屬性的話,可以使用這個方法,但是要注意它會回傳一個字典:
print(soup.find_all('a')[0].attrs) # {'href': 'http://example.com/elsie', 'class': ['sister'], 'id': 'link1'}
當然如果你不想要回傳那麼一個物件的話,可以直接指定屬性回傳:
print(soup.find_all('a')[0]['href']) # http://example.com/elsie
題外話一下,如果你是使用 get 方法的話,若這個屬性不存在則也是可以的唷~
print(soup.find_all('a')[0].get('title', '我不存在')) # 我不存在
那這邊這邊就只列出我常用的 BeautifulSoup 方法,實際上如果想看更詳細的會建議可以看官方文件唷~
這幾天跟朋友聊天聊到自己以前做版本控制的做法...
日期+版本號這種方式,結果結案的時候變成...
20130307_v1.zip
20130307_v2.zip
20130307_v3.zip
20130307_v4.zip
20130307_v5.zip
...
真慶幸自己學會使用 Git 之後這種狀況就沒有出現了。



 iThome鐵人賽
iThome鐵人賽