前面我們也已經學了不少的知識點,而這邊也進入了鐵人賽的最後一天,所以就來試著寫一個簡單的 ithelp 鐵人賽爬蟲。
一開始一樣先講一下我們要做什麼吧~
這邊我們主要會使用 Requests + BeautifulSoup 套件來實作一些東西,至於實作什麼就直接來看需求吧。
爬蟲目標網址:2021 iThome 鐵人賽首頁
首先請建立一個資料夾叫做 get-iThome,然後我們一樣要先建立虛擬環境
python3 -m venv .venv
那麼由於我們會須需要做爬蟲,因此要使用 Requests 來去請求頁面,然後再搭配 BeautifulSoup 分析 HTML(不要忘了 lxml 解析器):
pip3 install requests2 beautifulsoup4 lxml
接下來就是準備進入撰寫程式碼了,那麼這邊可以先引入相關套件:
import requests
import bs4 from BeautifulSoup
那麼一開始我們要先請求 iThome 的鐵人賽列表頁面,鐵人賽的網址是 https://ithelp.ithome.com.tw/2021ironman/signup/list,因此就會先使用 requests 套件請求該頁面回來:
r = requests.get('https://ithelp.ithome.com.tw/2021ironman/signup/list')
if r.status_code == 200:
print(r.text) # HTML 結構
這樣你已經取得了 iThome 鐵人賽的首頁囉~
那麼現在就要準備引入 BeautifulSoup 來解析剛剛撈回來的 HTML:
soup = BeautifulSoup(r.text, 'lxml')
超簡單的對吧!

接下來我們所有關於 HTML 選取都會跟 soup 有關,那我們其中一個需求會是需要繞取主題列表的連結與報名人數,所以這邊就請先打開瀏覽器到 iThome 頁面,然後使用開發者工具透過複製「CSS 路徑」取得 HTML 的位置,那這邊我們要選取到 .group-nav 就好,因為我們要它的連結與子元素:
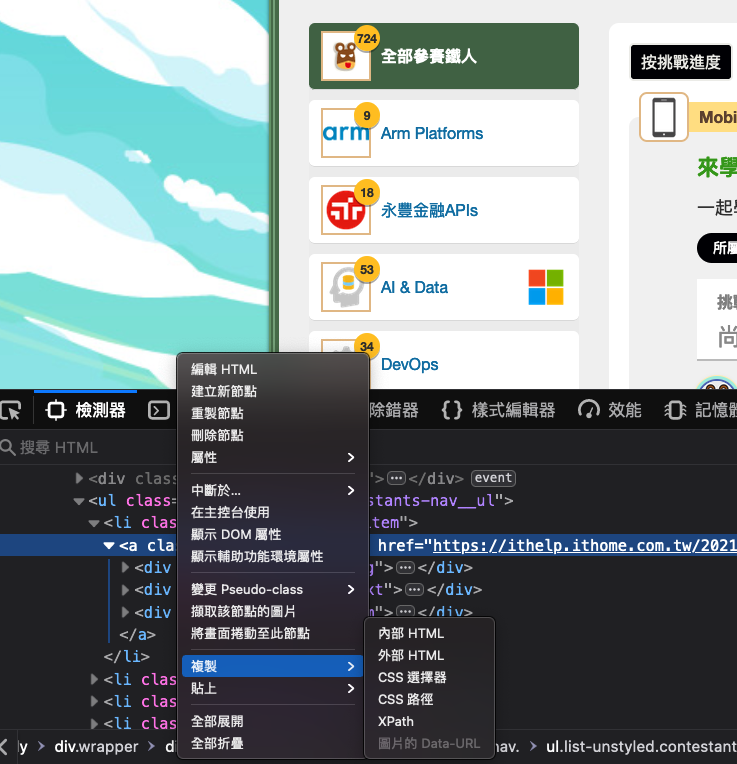
oh!你問我這是什麼瀏覽器嗎?因為我習慣開發使用 Firefox 瀏覽器,所以如果你有興趣的人可以考慮閱讀我這一篇關於 Firefox 的介紹唷~
那麼拉回到 Python 中,當你點選了複製 「CSS 路徑」之後你會取得以下這一大串 CSS 路徑:
html.fa-events-icons-ready body div.wrapper div.border-frame.clearfix div.contestants-nav ul.list-unstyled.contestants-nav__ul li.contestants-nav__item a.group-nav
那這邊會建議你刪除兩個地方,分別是開頭的這一段:
html.fa-events-icons-ready
與結尾的 .active,因此這邊只會保留以下這一段,否則你有可能會無法正確選取到元素唷~
body div.wrapper div.border-frame.clearfix div.contestants-nav ul.list-unstyled.contestants-nav__ul li.contestants-nav__item a.group-nav
那接下來就會使用到前一章節所介紹的 CSS 選取方式,也就是 select 方法來選取元素並儲存到另一個變數中:
tags = soup.select('body div.wrapper div.border-frame.clearfix div.contestants-nav ul.list-unstyled.contestants-nav__ul li.contestants-nav__item a.group-nav')
那麼我們都知道使用 select 方法選取出來的 HTML 元素會是一個串列,因此這邊必須使用 for loop 迴圈來取出主題、連結與參賽人數,所以就會需要使用一個變數暫存整理後的資料,那我們雖然已經選取出特定區塊的元素,但是為了讓選取更精準所以這邊就會使用 BeautifulSoup 的 find 方法,然後指定 class 組合成一個新的字典並推入到暫存的串列中,但這邊我有特別忽略全部鐵人這個選項:
cacheData = []
for item in tags:
if item.find('div', { "class": "group-nav__text"}).text.strip() != "全部參賽鐵人":
cacheData.append({
'name': item.find('div', { "class": "group-nav__text"}).text.strip(),
'num': item.find('div', { "class": "group-nav__num"}).text.strip(),
'url': item.get('href', None)
})
對了,這邊建議要取出主題名稱與參賽人數時結尾要補上 strip() 否則你會發現多一大推空白唷~

最後就是使用 JSON 模組將 cacheData 變數儲存到 .json 檔案中:
f = open('menu.json', 'w', encoding='utf8')
f.write(json.dumps(cacheData))
f.close()
那這邊也提供完整的範例給予參考:
import requests
from bs4 import BeautifulSoup
import json
r = requests.get('https://ithelp.ithome.com.tw/2021ironman/signup/list')
if r.status_code == 200:
soup = BeautifulSoup(r.text, 'lxml')
tags = soup.select('body div.wrapper div.border-frame.clearfix div.contestants-nav ul.list-unstyled.contestants-nav__ul li.contestants-nav__item a.group-nav')
cacheData = []
for item in tags:
if item.find('div', { "class": "group-nav__text"}).text.strip() != "全部參賽鐵人":
cacheData.append({
'name': item.find('div', { "class": "group-nav__text"}).text.strip(),
'num': item.find('div', { "class": "group-nav__num"}).text.strip(),
'url': item.get('href', None)
})
f = open('menu.json', 'w')
f.write(json.dumps(cacheData))
f.close()
前面我們已經完成了主體列表的取得,所以接下來就是獲取每一份主題列表中的參賽主題囉~
剛剛我們已經整理了一份 menu.json,所以這邊我們將會透過這一份資料來去請求參賽者的主題與連結,一開始我們先建立一個 getUserData.py 檔案,然後先引入我們會需要使用的套件:
import requests
from bs4 import BeautifulSoup
import json
接下來我們要使用 open 函式打開 menu.json,這邊要注意讀出來 JSON 檔案後要記得字典,否則會出現錯誤:
f = open('menu.json', 'r')
data = json.loads(f.read())[0]
接下來就是使用 for loop 搭配 requests 取得主題的頁面:
for item in data:
r = requests.get(item['url'])
這時候你應該會發現一件事情,就是我們只能獲取那個主題列表的首頁,但是卻沒有取得分頁的問題,你只要到主題列表往下滑可以看到分頁按鈕

那你可能會想說我們只有取得每一個主題的首頁,那這邊我們該如何取得分頁?其實非常簡單,首先你先到主題列表,然後算一下一頁大概幾筆資料,然後用我們剛剛整理的參賽人數去算出分頁有幾個,這樣子再搭配迴圈就可以多次請求了,廢話不多說上 Code:
for item in data:
pages = math.ceil(int(item['num']) / 10)
for page in range(pages):
r = requests.get(f'{item["num"]}&page={page}')
(這邊建議使用 math 模組的 ceil 方法,而不是 round,否則會出錯。)
透過以上寫法就可以拿回每一個分頁的資料與頁面,接下來就是依據主題資料來整理成一份新的資料並儲存到各自的 JSON,這邊邏輯也與前面類似,所以這邊最後就直接看完整範例:
import requests
from bs4 import BeautifulSoup
import json
import math
f = open('menu.json', 'r')
data = json.loads(f.read())
for item in data:
pages = math.ceil(int(item['num']) / 10)
cacheData = []
for page in range(pages):
r = requests.get(f'{item["url"]}&page={page + 1}')
if r.status_code == 200:
soup = BeautifulSoup(r.text, 'lxml')
tags = soup.select('body div.wrapper div.border-frame.clearfix div.contestants-wrapper div.contestants-list.clearfix')
for tag in tags:
cacheData.append({
'id': tag.find('a', { "class": "contestants-expect"}).get('data-id', None),
'name': tag.find('div', { "class": "contestants-list__name"}).text.strip(),
'title': tag.find('a', { "class": "contestants-list__title"}).text.strip(),
'url': tag.find('a', { "class": "contestants-list__title"}).get('href', None),
'like': tag.find('span', { "class": "contestants-expect__number"}).text.strip()
})
print(f'已經取得 {item["name"]} 主題,共 {len(cacheData)} 參賽資料。')
f = open(f'./data/{item["name"]}.json', 'a')
f.write(json.dumps(cacheData))
f.close()
那麼這邊就是一個完整的爬蟲範例,當然還可以做更進階的,例如撈取每一份主題的訂閱數、計算總閱覽數等這類型鐵人賽所沒有提供的功能,而這部分的實作就當作我出給你的最終作業囉。
前陣子朋友問了我一下如何入門投資與創造被動收入,後來我想了一下就將之前自己的一些小小心得寫成了一篇文章分享給他,雖然不知道對他是否有幫助,但是最主要期望他在思考這問題之前先解決自己金錢上管控的問題,畢竟他真的不太會控管自己金流 QQ
如果有興趣的人也可以參考看看(?)



 iThome鐵人賽
iThome鐵人賽