我們昨天建立好 Label 專案之後,今天就來進行資料標記吧!
我們點進去專案之後,可以看到一個 Dashboard,這裡會顯示你這個標記專案的進度。我們點擊左上的 Label Data。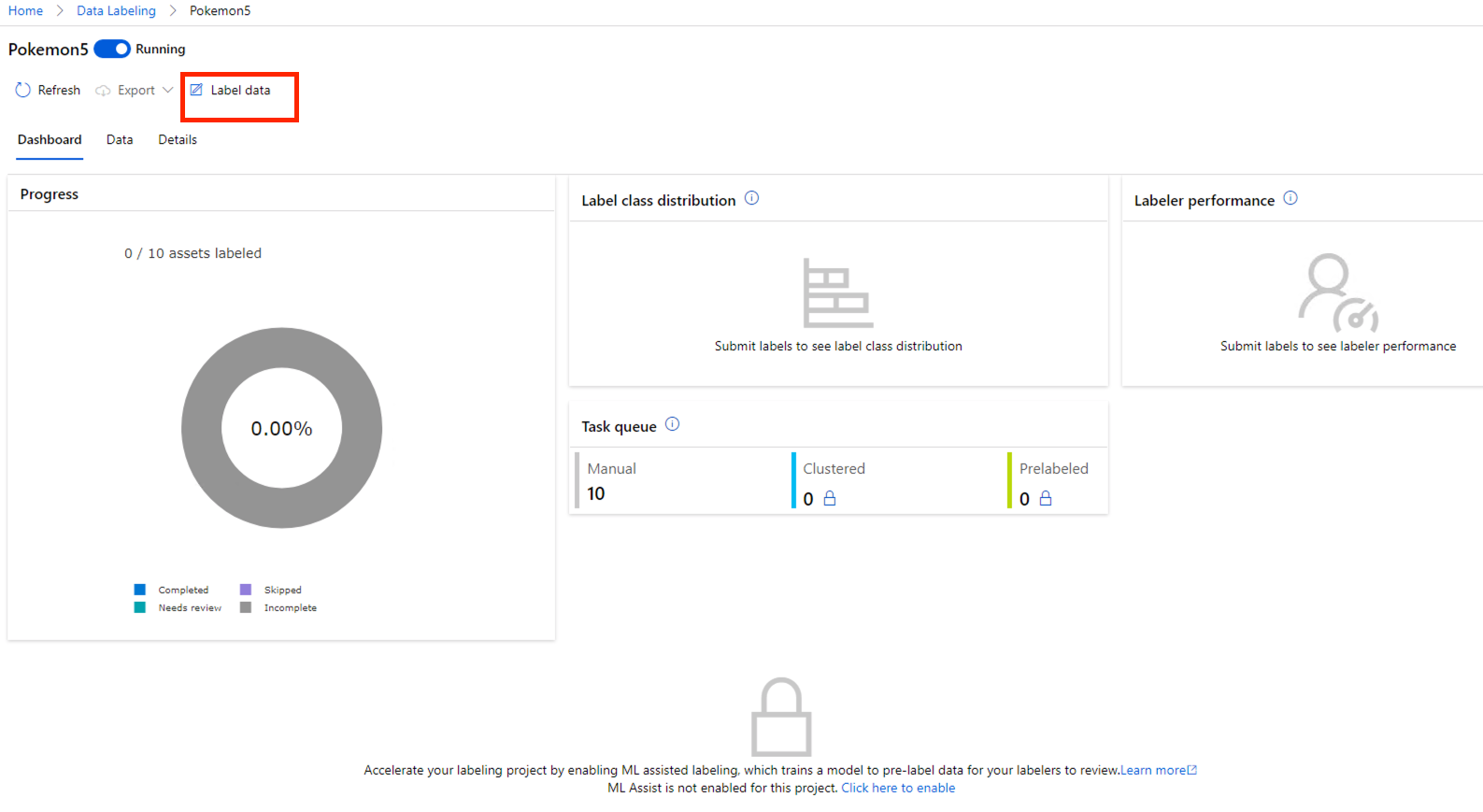
接著會先進入 Instructions 的部份,可以看到我們昨天輸入的內容。這裡我們再補充一下寫 Instructions 的原則,根據微軟的建議如下:
真實世界的專案千萬不要像下圖隨便寫寫啊 XDD
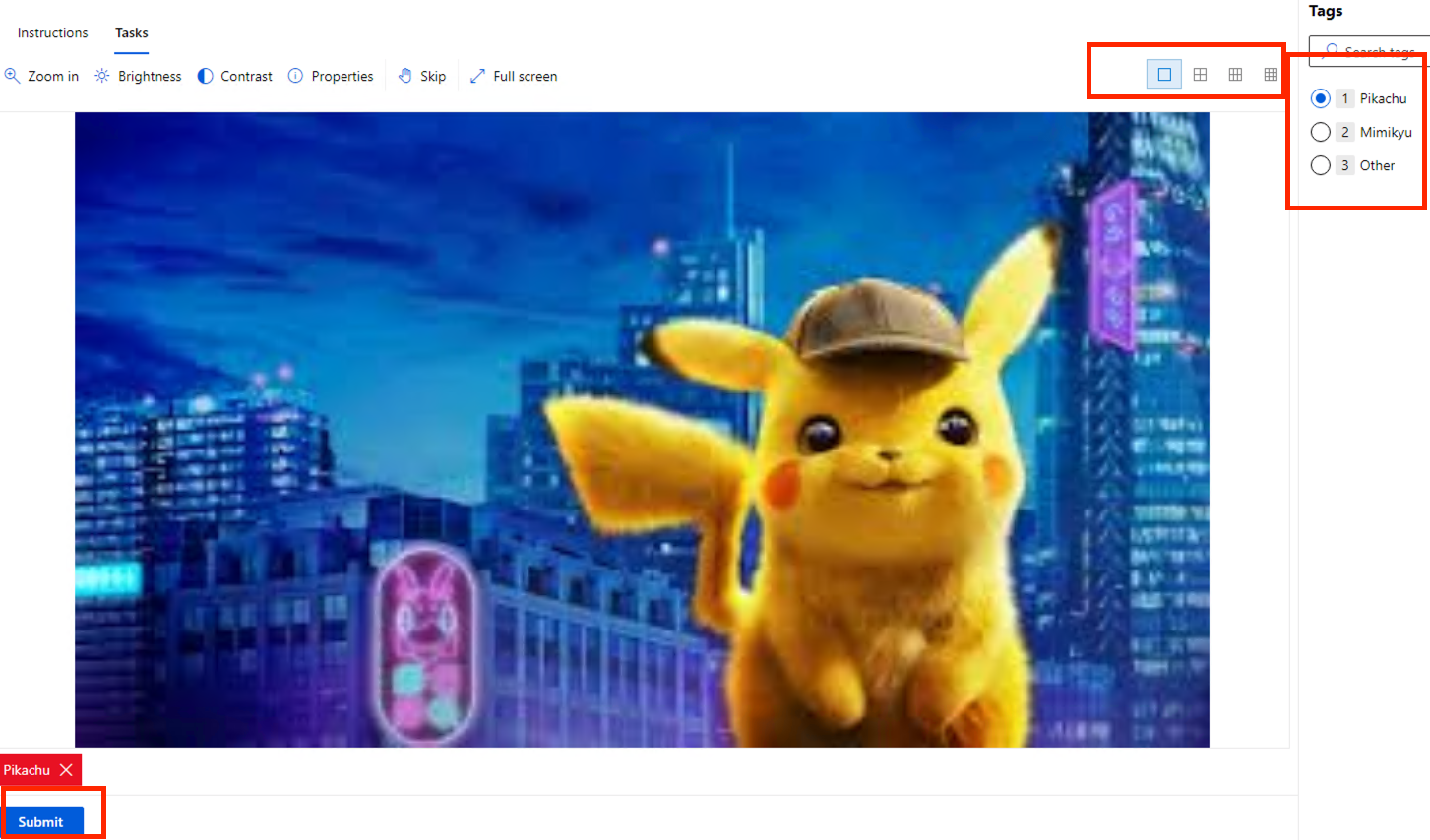
標記幾張後,我們可以回到主頁面,可以看到 Dashboard 有所變化了。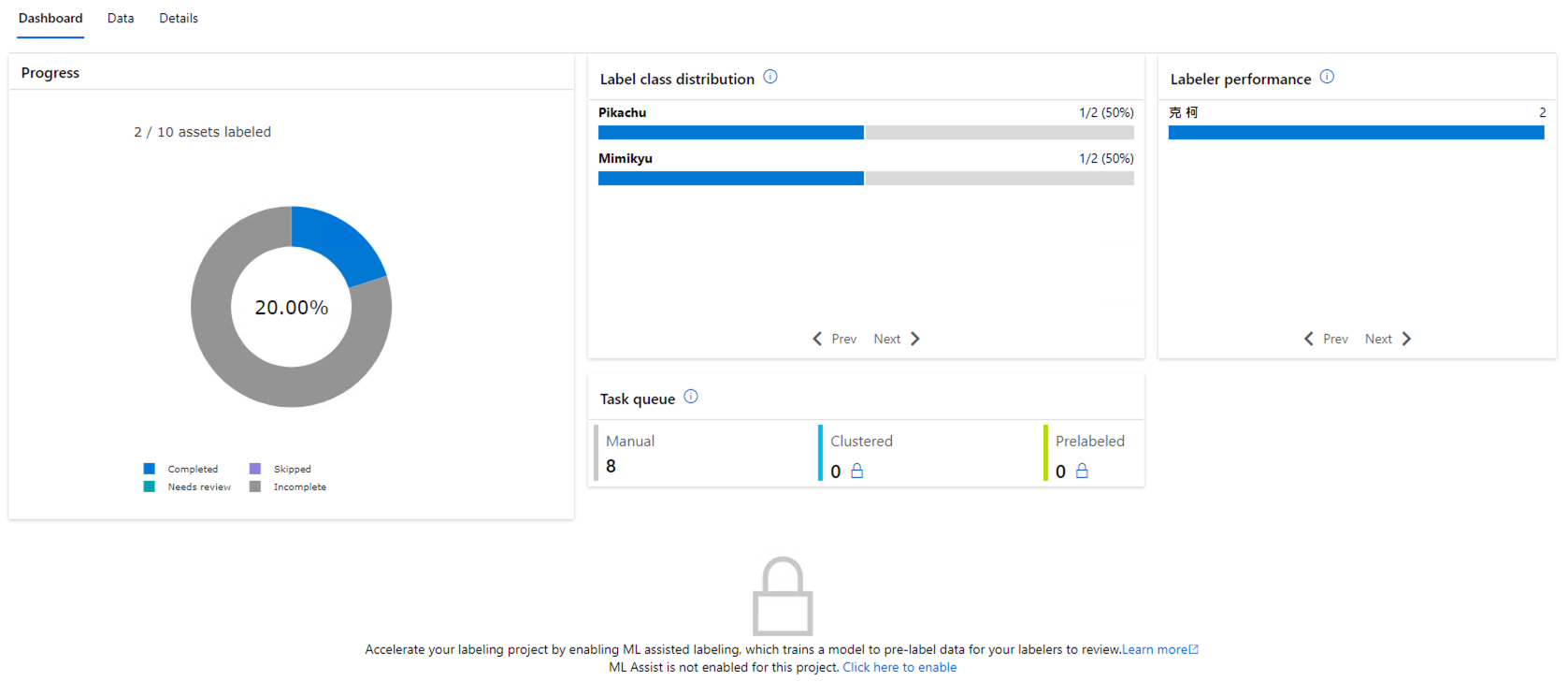
我們離開 Dashboard 的頁簽,進入 Data 的頁簽,點左邊選單的 Labeled Data,可以來檢查這些 Label 是否正確或合格。如果不行的話,可以按 Reject。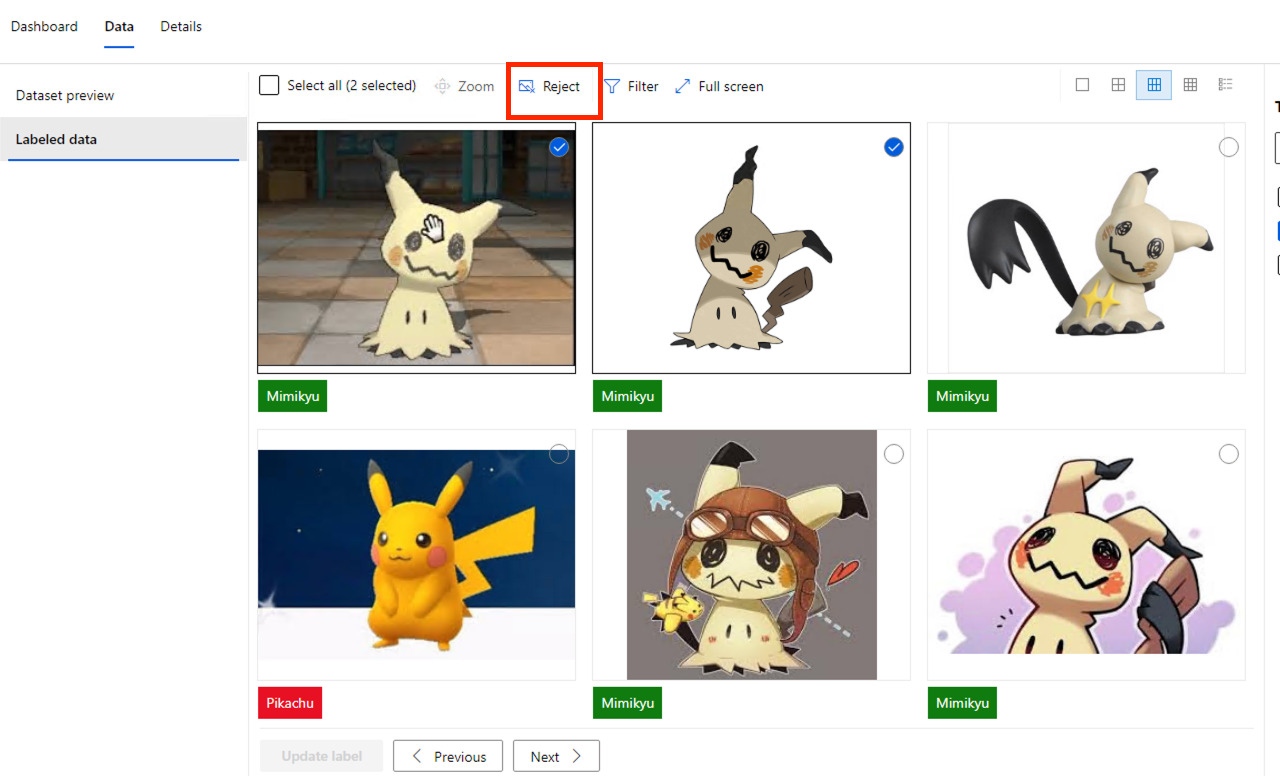
我們把所有的資料標註好之後,回到 Dashboard,點擊上方 Export。這裡有三種 Export 的格式,CSV 就是 CSV,COCO 是另一種資料集標註的格式,可以參考 COCO Dataset 的網站。我們這裡選 Azure ML Dataset。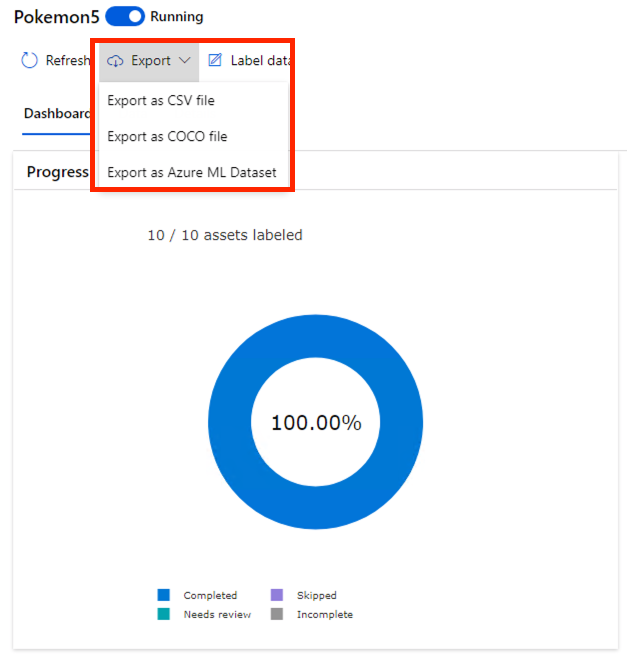
資料量不多的話,很快就會輸出好了。我們進到 Datasets 裡,就會看到剛剛標記過的資料集啦!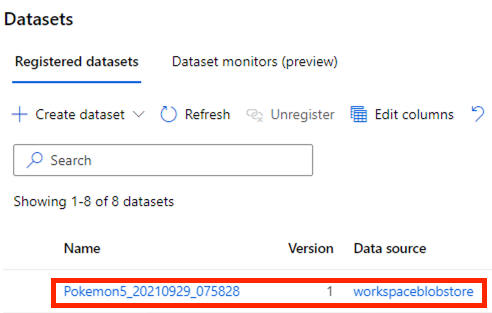
我們點進資料集,到 Consume 的頁簽,把程式碼複製下來。這裡的程式碼只是把 Dataframe 叫出來而已,還不太符合我們的需求。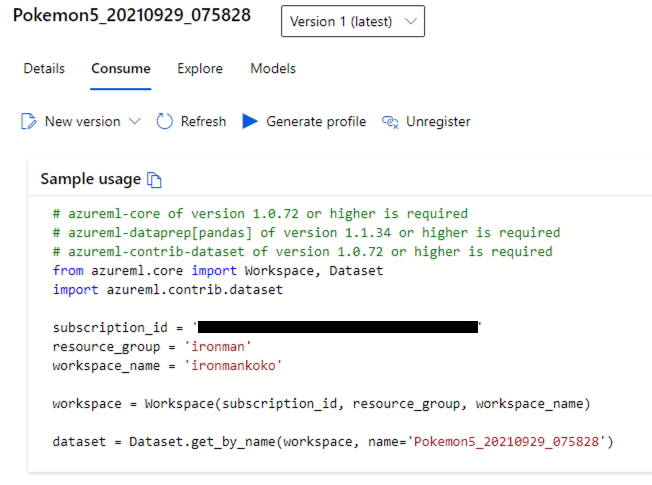
打開 Notebook 開新檔案,我們要用 azureml-contrib-dataset 來下載我們的圖檔。我們輸入以下程式碼:
(如果沒有 azureml-contrib-dataset,可以用此指令安裝 pip install azureml-contrib-dataset )
import azureml.core
import azureml.contrib.dataset
from azureml.core import Dataset, Workspace
from azureml.contrib.dataset import FileHandlingOption
from azureml.core import Workspace, Dataset
import azureml.contrib.dataset
subscription_id = '<Your subscription ID>'
resource_group = '<Your resource group>'
workspace_name = '<Your workspace name>'
workspace = Workspace(subscription_id, resource_group, workspace_name)
pokemon_dataset = Dataset.get_by_name(workspace, name='<Your dataset name>')
pokemon_pd = pokemon_dataset.to_pandas_dataframe(file_handling_option=FileHandlingOption.DOWNLOAD, target_path='./download/', overwrite_download=True)
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
#從 dataframe 裡把圖檔讀出來
img = mpimg.imread(pokemon_pd.loc[0,'image_url'])
imgplot = plt.imshow(img)
然後可以看到如下圖的結果。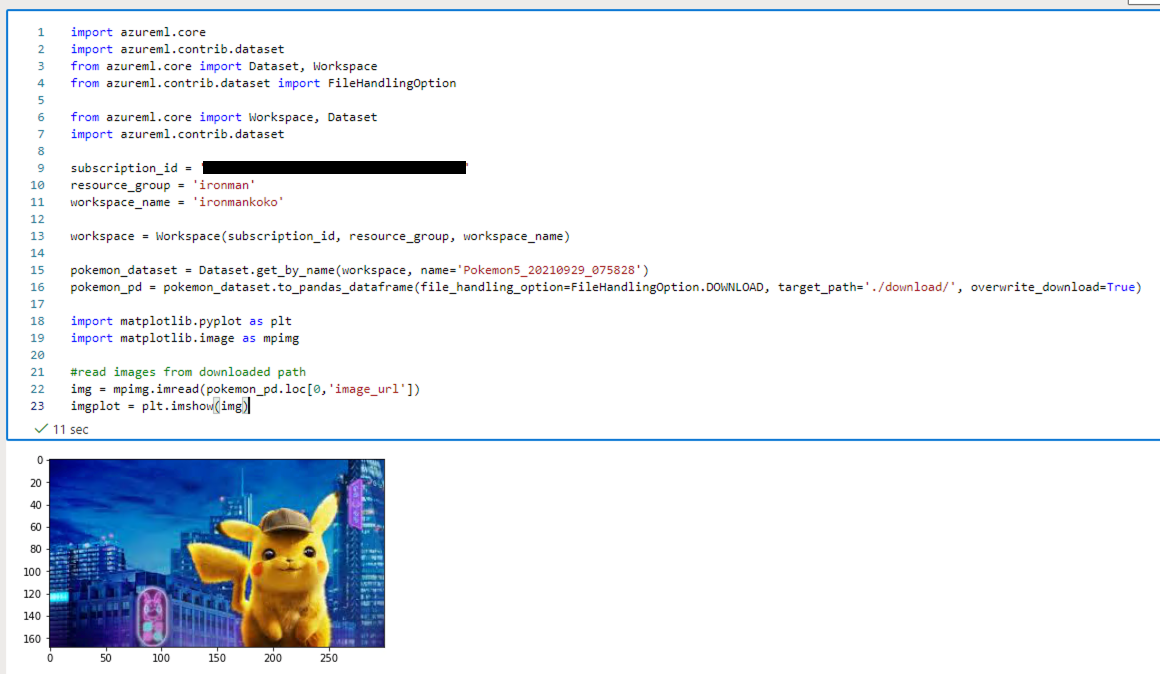
以上就是連續三天的資料標記和取用啦!有沒有覺得更貼近真實世界 AI 專案的需求了呢?
明天我們開始來談 AML 多人協作的功能,這個是組建一個 AI 團隊不可或缺的功能!


 iThome鐵人賽
iThome鐵人賽