各位早安,書接上回我們已經搞定接下來會用到的套件的安裝了,套件是很強大的工具可以幫助我們簡化很多複雜程式碼,接下來今天我們要開始期待已久的開爬時間
但是在這之前 要麻煩你先做一件事
刪除之前的練習檔 string.py
為甚麼呢 這要從小弟我開心的測試爬蟲程式開始講起
有一天在運行我自己的 test.py 測試檔的時候不斷出現這個結果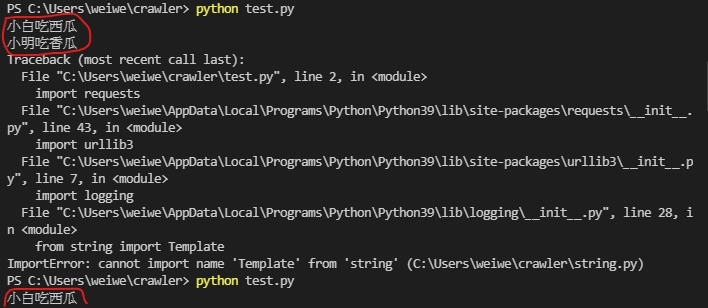
我就覺得奇怪怎麼會這樣 還跑出小明跟小白 這超眼熟的阿
後來想起來這是之前練習檔案的內容
阿奇怪怎麼我執行的是 test.py 報錯就算了反而跑出別的檔案的內容呢
後來經過我反覆確認及思考 突然想通了 原來是我取的名字太爛干擾到系統抓資料了阿
難怪會跑出 string.py 的內容
所以麻煩大家為了不要遇到問題
先找到它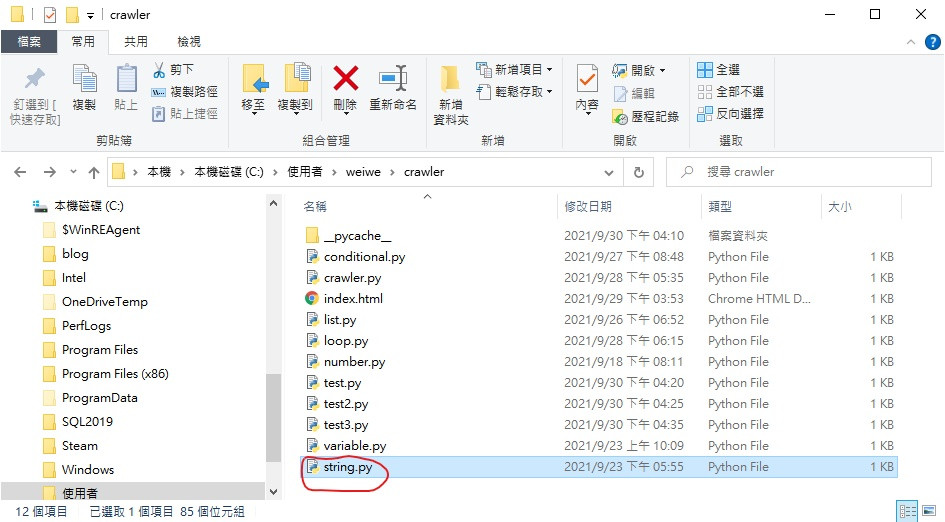
然後果斷按下刪除鍵吧
首先第一步就是打開我們好久沒用到的 crawler.py 檔案編輯器
那在我們開爬之前我們要先知道我們想要抓取那些資訊
所以今天假設我是一個想了解股票資訊的年輕人
想要抓取PPT股票版的內容了解最近的事
所以首先找到目標網頁 url (網址)
複製下來
接著先 import 要用的套件功能 requests bs4
接著建個變數放 url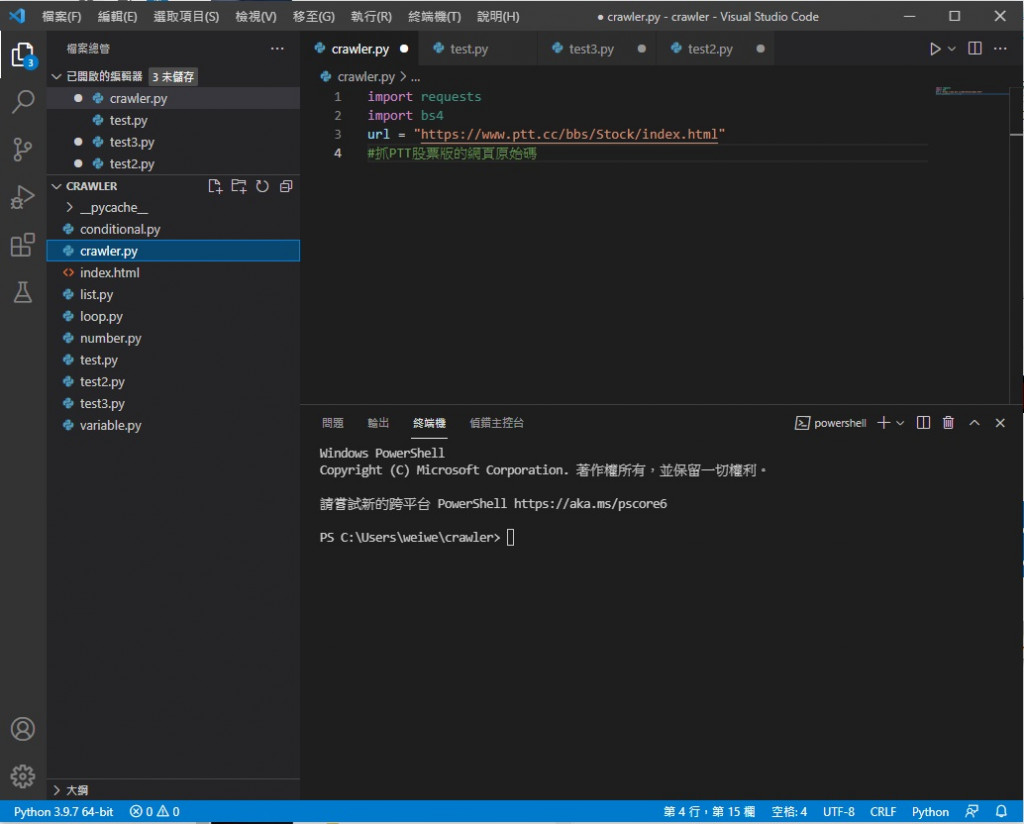
這裡補充一下在 python3 中 # (井字號) 後面的內容叫做註解 是不會被程式執行到的
接著我們要用 requests 內的方法把網頁內資料 GET 下來
再把它印出來看看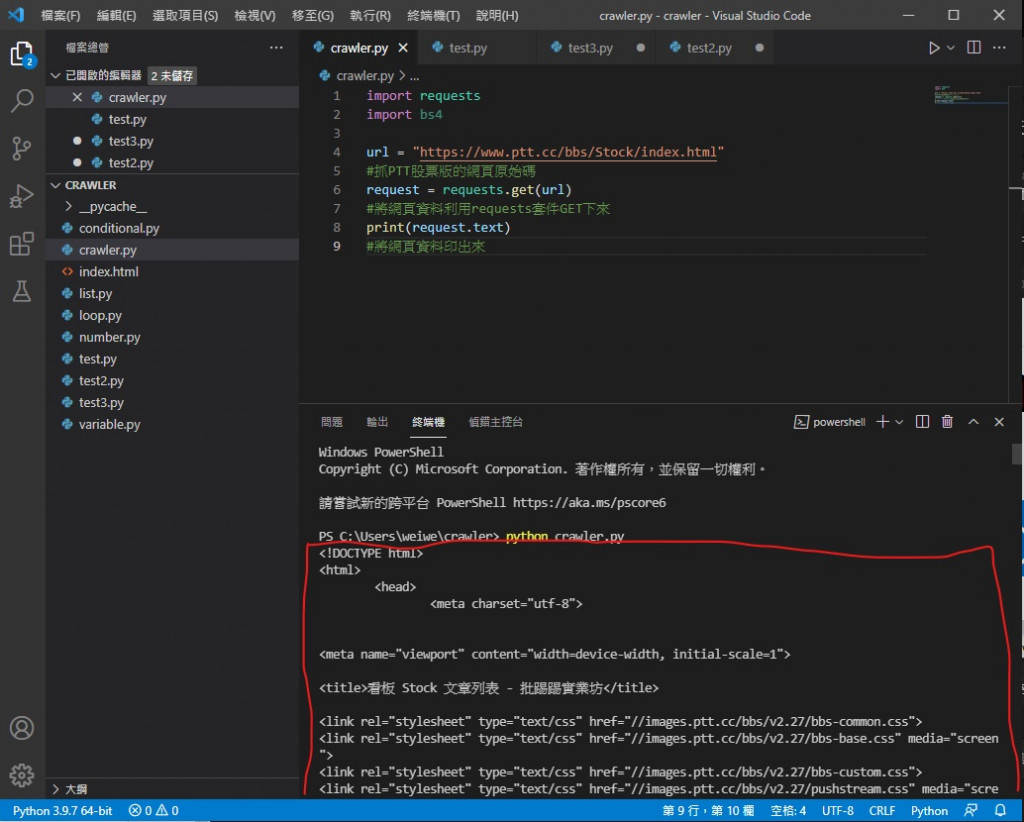
print(request.text) 意思是把 request 內的東西以文本形式印出
紅色框住的地方開始就是抓到的網頁內容 是 html 格式的網頁原始碼
我先提醒一下 這裡抓到的內容都是網頁實時更新的內容 你們跟我不一樣很正常
我們到目標網頁上看看原始碼
先對網頁點右鍵 再點檢視網頁原始碼
就會看到這樣的視窗 這就是剛剛網頁的 html 原始碼
跟剛剛我們爬蟲抓到的一樣
今天的程式碼
import requests
import bs4
url = "https://www.ptt.cc/bbs/Stock/index.html"
#抓PTT股票版的網頁原始碼
request = requests.get(url)
#將網頁資料利用requests套件GET下來
print(request.text)
#將網頁資料印出來
今天我們知道怎麼抓到資料
明天要來講解析這些資料的方法 還有怎麼抓取特定資料
就連聲控關燈也算是人工智慧喔
你覺得人工智慧發展下去會跟電影裡一樣毀滅人類嗎


 iThome鐵人賽
iThome鐵人賽