各位早安,書接上回我們已經成功抓到網頁的原始碼了,今天我們要把它變成有用能閱讀的資訊
那我們解析網頁就要用到 bf4 的功能了
先把印出全部 html 刪掉 因為我們不用知道全部
把這裡刪掉
接下來我們要解析它
在下面加上
data = bs4.BeautifulSoup(request.text, "html.parser")
print(data)
我們建立 data 變數用來存放經過 bs4 解析過的資料 request.text
然後解析的格式用 "html.parser"
然後印出 data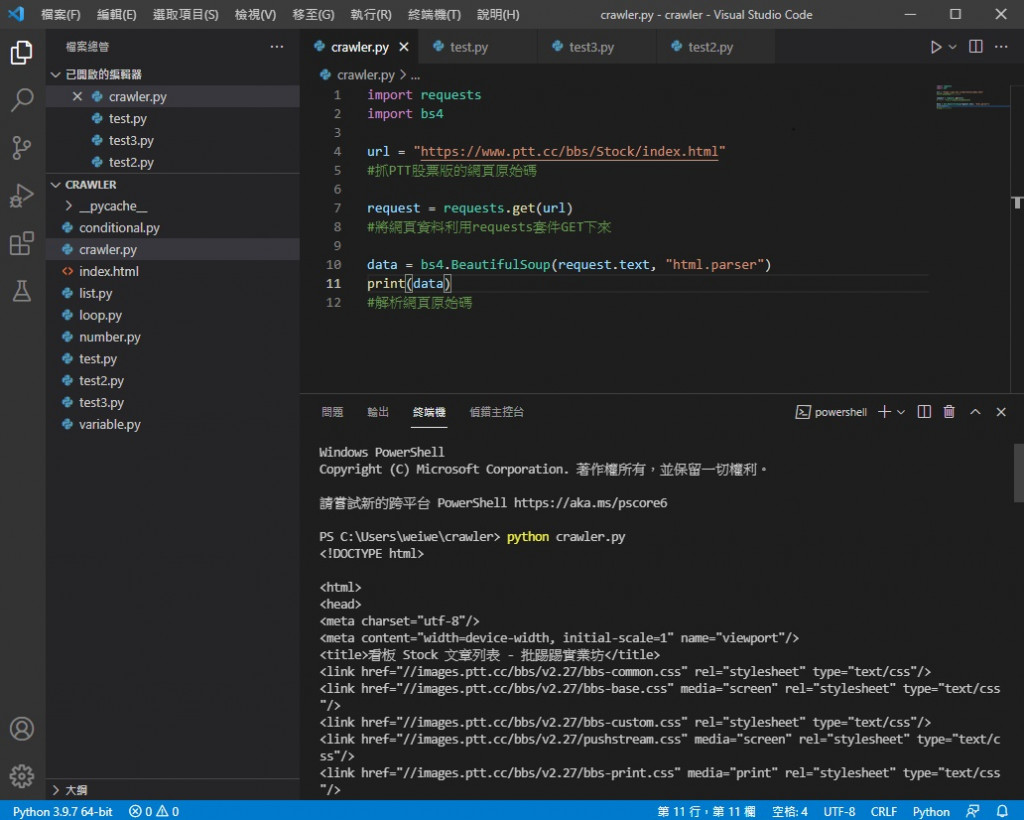
可以看到雖然還是看不懂 但是跟之前不同了
這是經過 bs4 解析整理過後的樣子
我們先試著抓抓看最明顯的網頁標題
也就是這個東西
接下來我們開瀏覽器到網頁原始碼的地方
網頁標題的原始碼就在這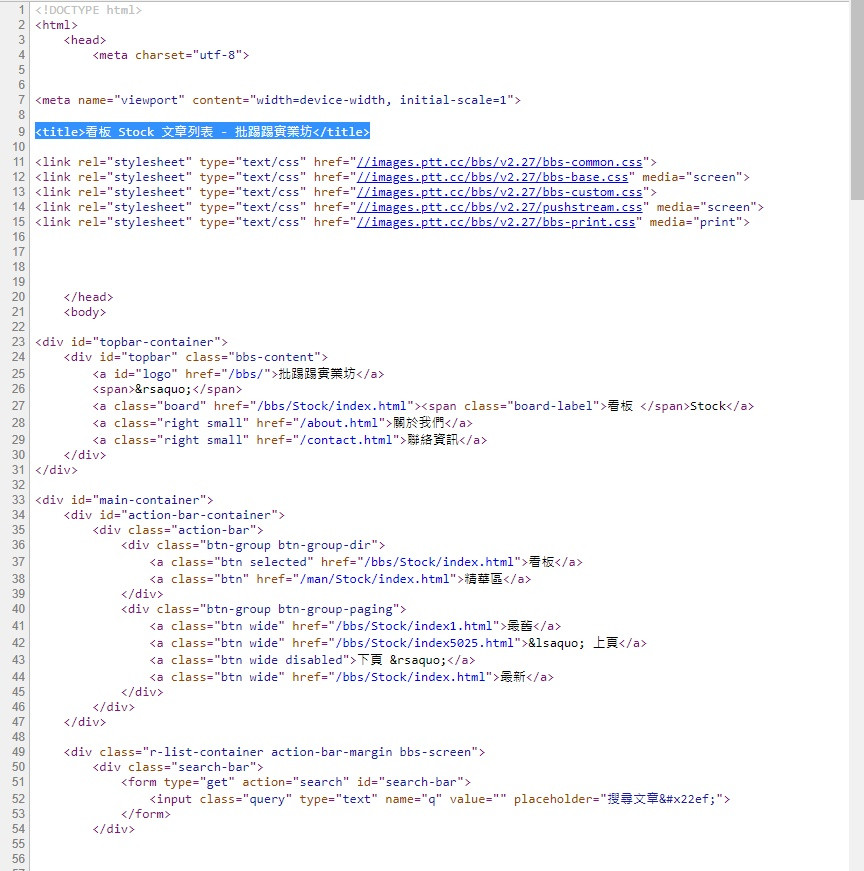
它的標籤是 title
所以我們把 print(data) 加上 .title
變成
print(data.title)
現在程式碼
import requests
import bs4
url = "https://www.ptt.cc/bbs/Stock/index.html"
#抓PTT股票版的網頁原始碼
request = requests.get(url)
#將網頁資料利用requests套件GET下來
data = bs4.BeautifulSoup(request.text, "html.parser")
print(data.title)
#解析網頁原始碼
執行結果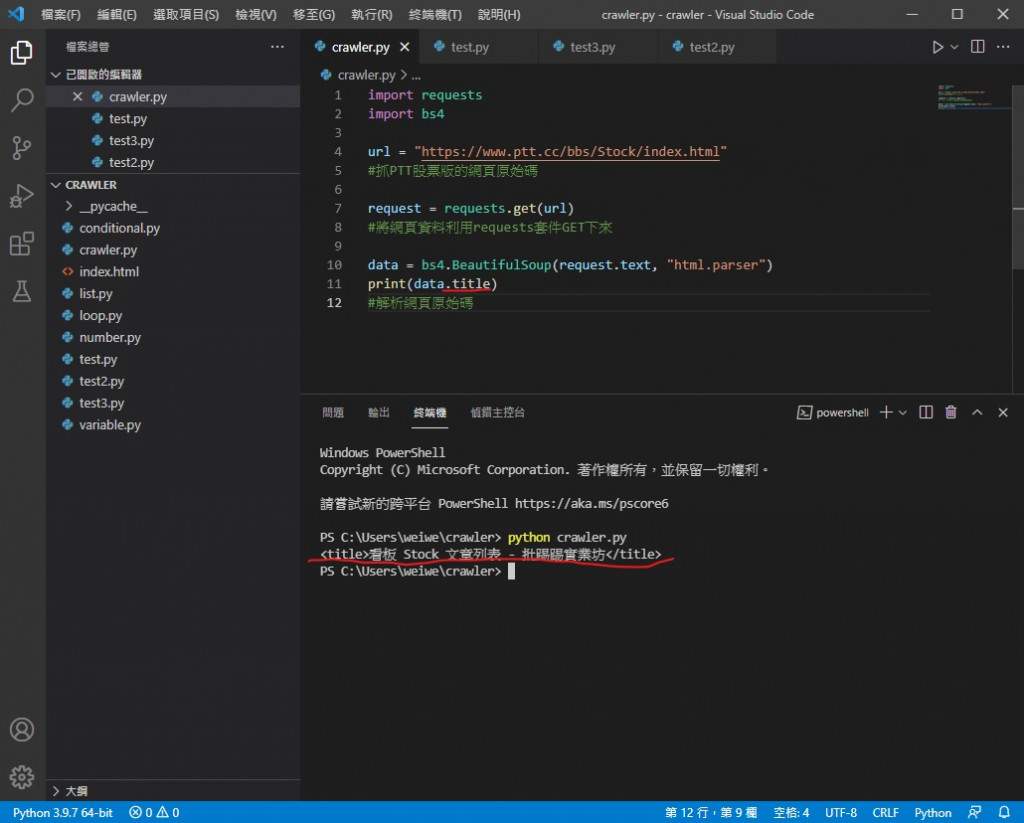
可以看到成功印出來了
那如果不希望它旁邊有標籤
就在 print(data.title) 裡面加上 .text
變成
print(data.title.text)
執行結果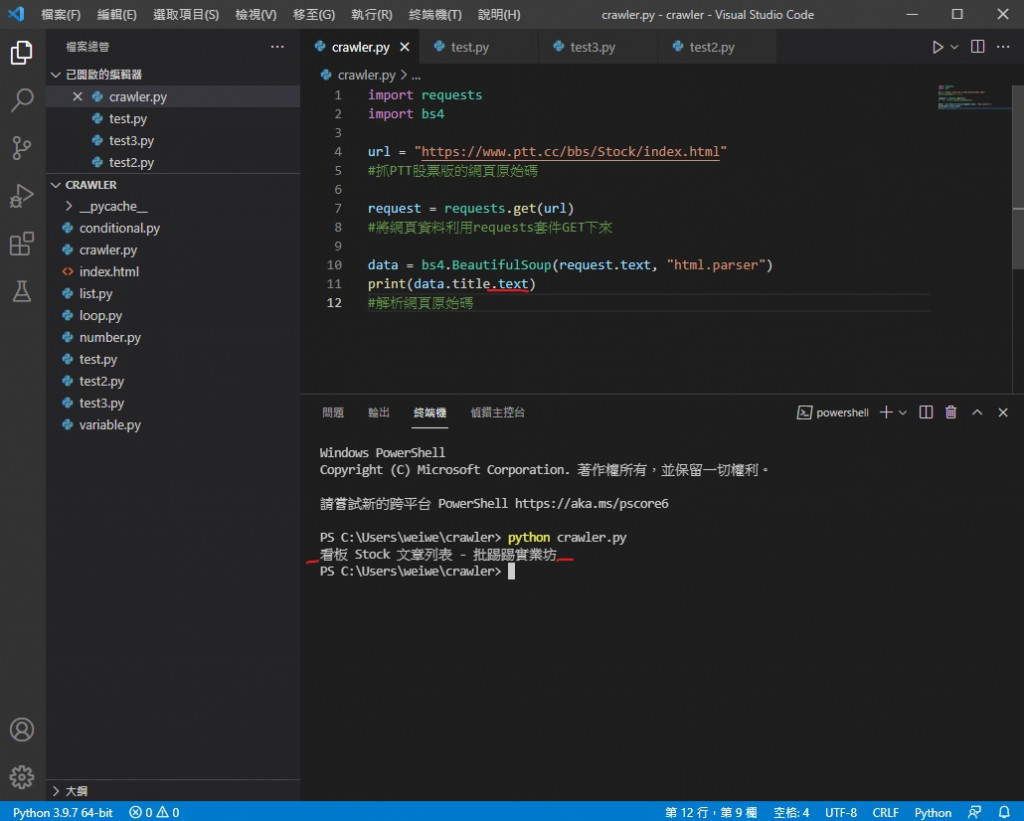
可以看到成功去掉標籤了
從以上我們可以看出 在我們抓取資料時 要一層一層指定我們要的資料
今天的程式碼
import requests
import bs4
url = "https://www.ptt.cc/bbs/Stock/index.html"
#抓PTT股票版的網頁原始碼
request = requests.get(url)
#將網頁資料利用requests套件GET下來
data = bs4.BeautifulSoup(request.text, "html.parser")
print(data.title.text)
#解析網頁原始碼
今天我們知道怎樣解析資料並指定到想要的位置
明天我們要來以文章標題做目標進行更進階一點的爬取資料]
鯨魚的屍體放著會腐敗發酵最後爆炸喔
如果可以的話你希望知道自己死掉的日期好好安排剩下時間還是不知道開心度日呢


 iThome鐵人賽
iThome鐵人賽