今天剛好找到一個有趣的文字識別模型,想來和大家介紹一下~
PaddleOCR是百度研究出來的文字識別模型,主要可以把圖片當成input然後判斷裡面的文字,實際用python操作起來非常的容易,大家有空可以自己玩一下,因為本身模型非常小,用cpu也是可以跑得動的呦!接下來就直接來用python實作吧!
下載paddleocr之前需要先裝paddle,可以把它想像成是基礎架構,如果用gpu跑的人記得把code換成:
!python -m pip install paddlepaddle**-gpu**==2.0.0 -i https://mirror.baidu.com/pypi/simple
# GitHub repo installation of paddle
!python3 -m pip install paddlepaddle==2.0.0 -i https://mirror.baidu.com/pypi/simple
接下來下載paddleocr
!pip install "paddleocr>=2.0.1" # Recommend to use version 2.0.1+
from paddleocr import PaddleOCR,draw_ocr
from matplotlib import pyplot as plt
import cv2 #opencv
import os
直接開始蓋model,使用gpu的把use_gpu改成True,或是刪掉因為default就是True,另外paddleocr支援多國語言識別,大家也可以把lang換掉玩玩看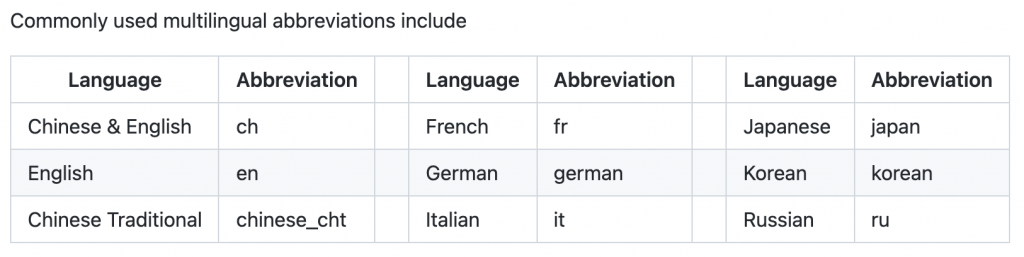
# Setup model
ocr_model = PaddleOCR(lang='en',use_gpu=False)
放入一張圖片分析一下:
img_path = os.path.join('.', 'test.jpg')
# Run the ocr method on the ocr model
result = ocr_model.ocr(img_path)
來看看識別結果,回傳的資料為文字的位置,文字內容,與準確度:
result

也可以單獨把文字列出來,最後放上原圖比較:
for res in result:
print(res[1][0])
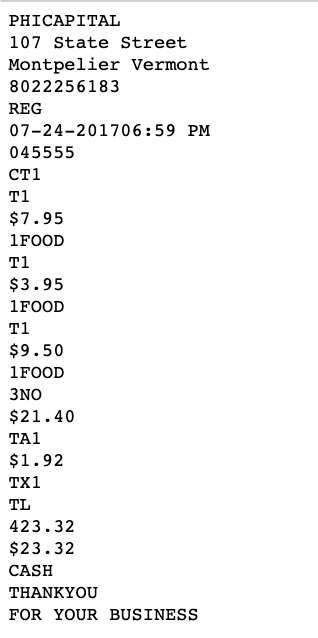

這個方便程度還有準確度真的是非常的神奇啊~
[reference]
https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.3/doc/doc_en/quickstart_en.md#paddleocr-quick-start
https://pypi.org/project/paddleocr/
https://www.youtube.com/watch?v=t5xwQguk9XU
不知道有沒有人在安裝的時候遇到問題 “an error in building wheel for PyMuPDF.”
謝謝文章分享

