最後的這幾篇文章想要來介紹一下yolo,主要是用deep learning來做物件偵測(object detection)。
YOLO其中一個特點是他是one stage method(region-free),全稱是“you only look once”,也就是一次處理物件的位置與類別分辨;另一種方式為two stage method(region-free),方法是先偵測照片中的物體位置,裁剪之後再放入分類器判斷是什麼物體。
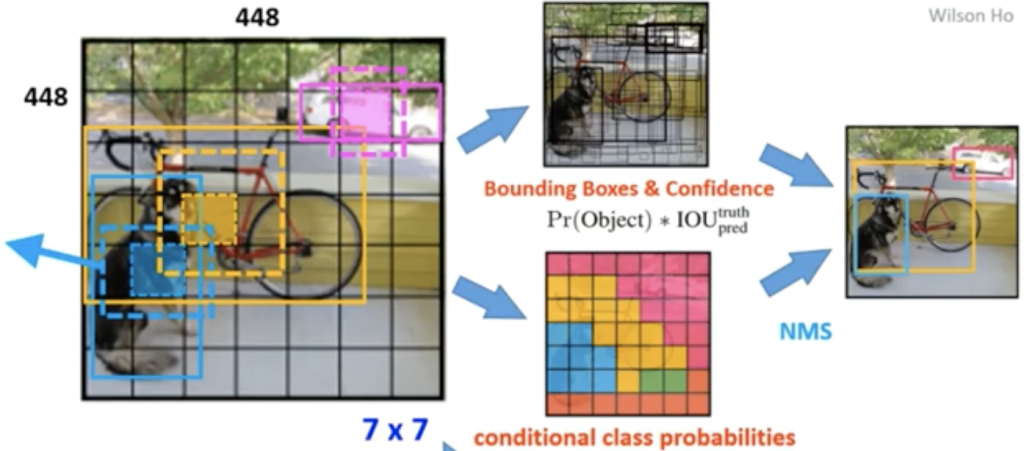
YOLO的主要原理是切割照片成S*S的窗格(grid),每個grid都會偵測出B個框框(bounding boxs)來定義物體的位置,bounding boxs的資訊包含:(x,y)中心座標,w 寬度,h 高度, conference 物體在框框里的把握度,公式如下圖: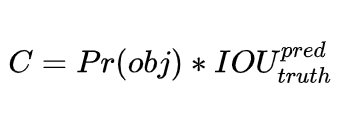
所謂的Pr(object)是窗格內是否有物體的機率,如果有就是1,沒有則是0,IOU則是intersection over union,也就是計算bounding boxs和物體實際位置的交集/聯集比。
另外每個窗格(grid)也會預測物體類別,用one-hot encoding來表示,明天再來細講相關的損失函數還有架構。
[reference]
https://www.youtube.com/watch?v=sq_OfIhb5Oc

