今天來講一下yolo v1的架構與損失函數,架構如下: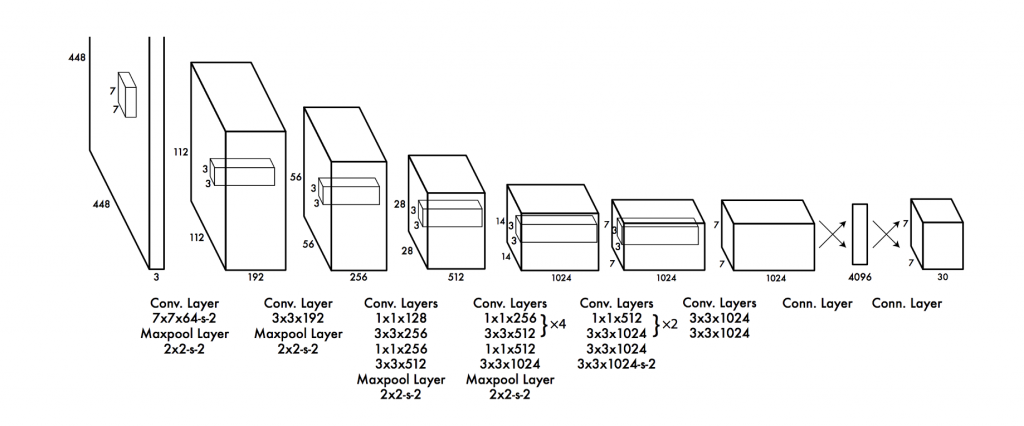
首先先把圖片改變成448 * 448的大小,yolov1總共有24層convolutional layers來擷取圖片特徵,最後兩層
fully connected layers則負責預測物體類別,最後輸出7 * 7 * 30的向量,7來自於切的grid數量,30則是因為輸入的dataset有20個類別加上x,y,w,h,confidence,兩個bounding box(20+5*2)。
loss function看起來非常可怕,我們來拆解一下: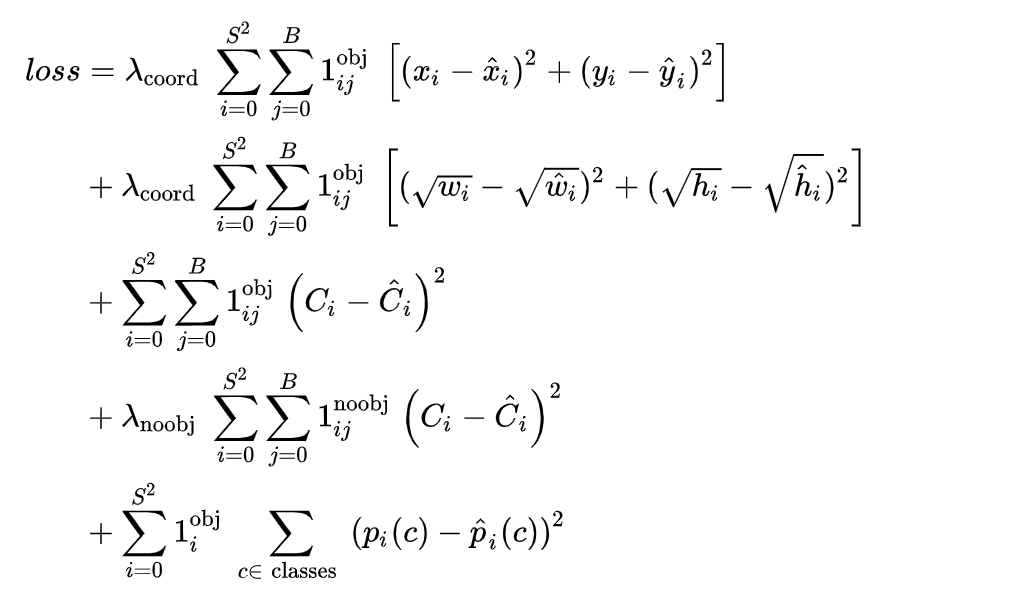
總共有五項,中心概念是輪過所有grid的每一個bounding box去計算MSE,第一項針對(x,y)中心座標,第二項針對w,h 寬與長,第三項針對confidence,第四項只有在bounding box不包含物體中心時才計算,最後一項則是分類誤差。
[reference]
https://medium.com/@ankushsharma2805/yolo-v1-v2-v3-architecture-1ccac0f6206e
https://zhuanlan.zhihu.com/p/37850811
https://zhuanlan.zhihu.com/p/58066901
https://zhuanlan.zhihu.com/p/94986199
https://www.youtube.com/playlist?list=PLANbacZNzD9FOcLenvcfgE7R4QdHgOXSq

