接續介紹昨天建立的EMR叢集:
建立的叢集可以在左方工具欄的叢集分頁找到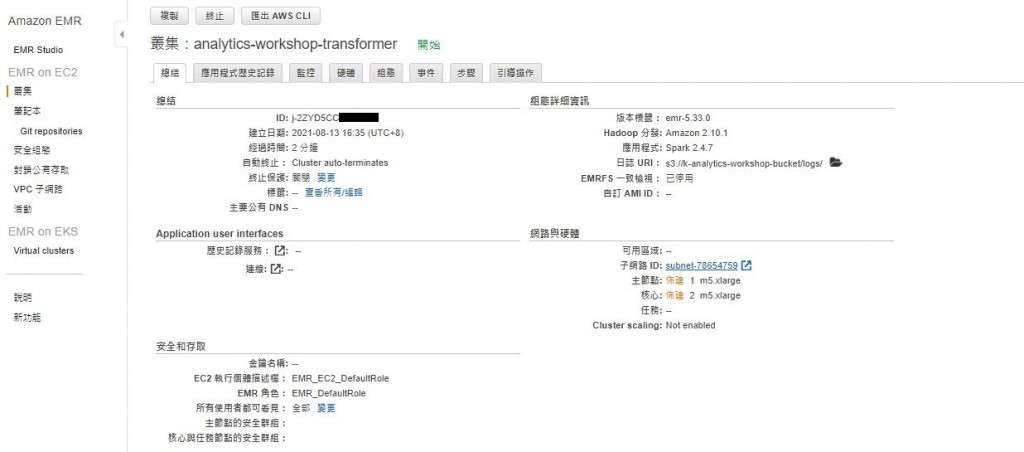
步驟的狀態可以到「步驟」分頁查看,可以看到叢集會分兩步驟:
先建立好Hadoop後再安裝Spark程式後執行分析任務
Hadoop設定大約需要6-8分鐘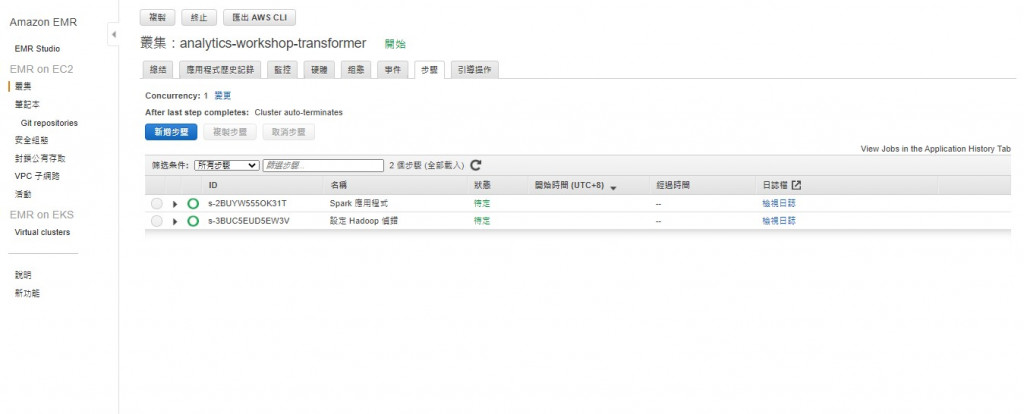
因為建立時選用的是步驟執行,可以看到狀態還是「待定」
然後會看到執行步驟會由下而上依序轉換成「已完成」,然後就會叢集就會終止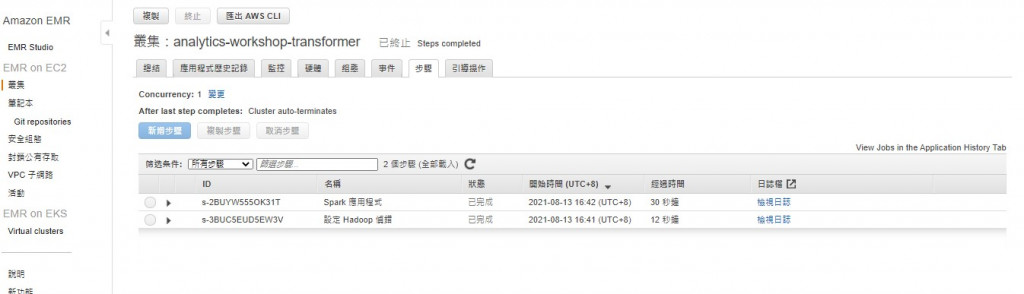
Log記錄會存到建立叢集時指定的S3 bucket中,點選後會轉跳到對應頁面
如果執行失敗了也可以到log記錄去看
EMR的服務頁面可以當作Hadoop3的 9870 port來用,相當方便,
而分析處理完的結果也是到S3 對應的bucket中查詢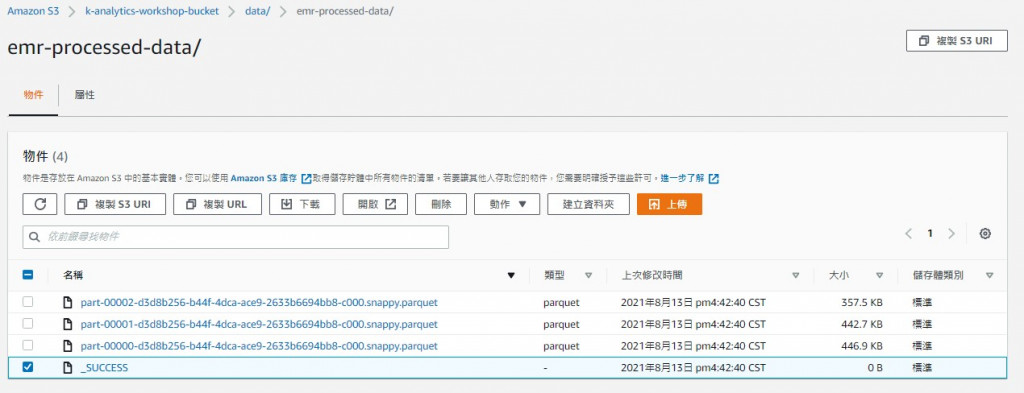
當然因為批次執行大量檔案的分析,檔案是以壓縮檔儲存(這裡是parquet檔),
所以比起直接到S3察看EMR的ETL結果,更常見的架構是在EMR後串接像是Hive或Athena等查詢工具來進一步分析資料
AWS上方便的查詢工具就是Athena(後續會介紹),
進入到Athena服務頁面可以在左方選定資料源後在右方編輯器下SQL查詢語句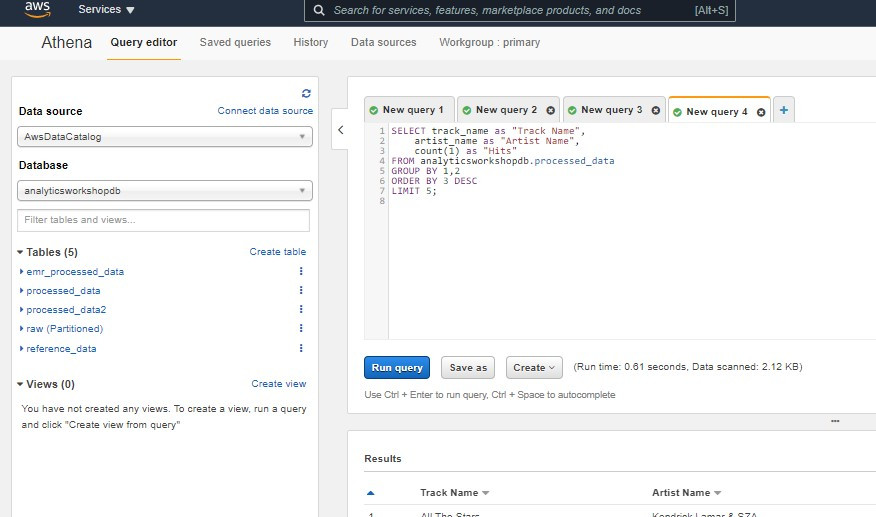
*Hadoop( https://zh.wikipedia.org/wiki/Apache_Hadoop )

