Amazon Elastic MapReduce(EMR)是可以在EC2 instance 或 Amazon EKS cluster上執行Hadoop運算的託管服務(managed service)。可以做到分散式儲存的Hadoop適合用來執行PB等級的大型/複雜分析運算,而AWS EMR則提供了方便的操作介面可以快速佈建出Hadoop環境供使用者使用,節省了一步步安裝Java再安裝Hadoop,之後還要再設定master node 與 slave node 的網路環境與core-site等設定檔。而且Hadoop豐富的生態系資源也可以在EMR上配置,像是前一個介紹的Glue所執行的Spark環境,也可以在EMR上安裝。
而現在或許會有了新的疑問,那Glue 與 EMR應該要選用哪一個呢?
除了用資料量大小來做判斷,也可以依照使用者對環境存取的需求來決定。Glue是無伺服器服務所以底層環境是交由AWS來管理;EMR則讓使用者可以直接存取低層的環境設定,也能更有彈性的使用 Spark 以外的分析工具。
進入服務介面可以直接點選「建立叢集」
或是左方工具欄可以找到叢集分頁進入建立分頁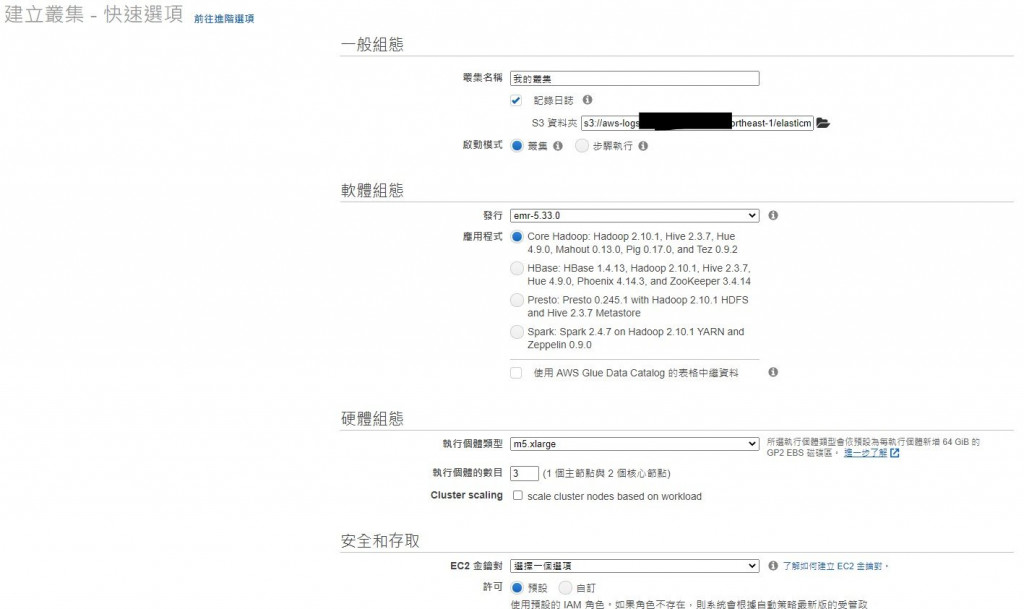
建議可以先至S3按照使用需求建立對應的bucket方便之後上傳資料與log查詢
最基本環境上可以先建立四個bucket分別儲存 分析資料、分析指令、分析結果和log記錄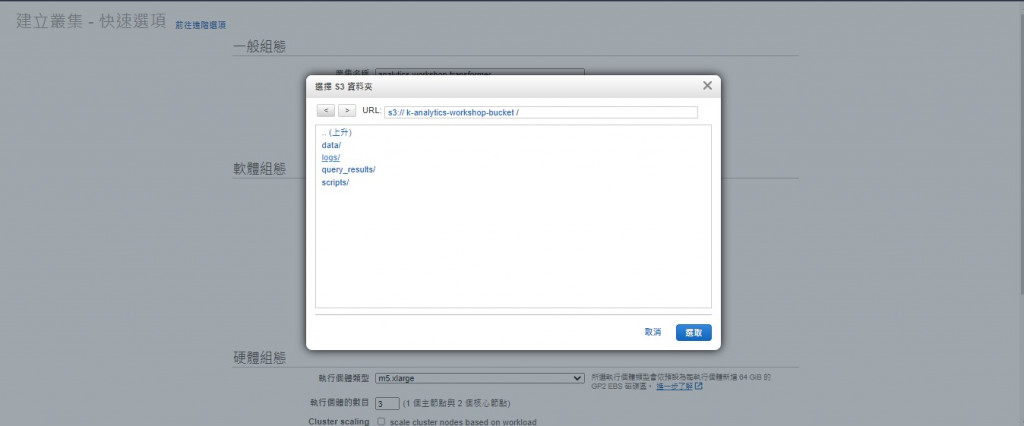
啟動模式下方叢集cluster與步驟執行step的差別是:
叢集會一直開著,而選用步驟執行,會在步驟跑完後將運算叢集停止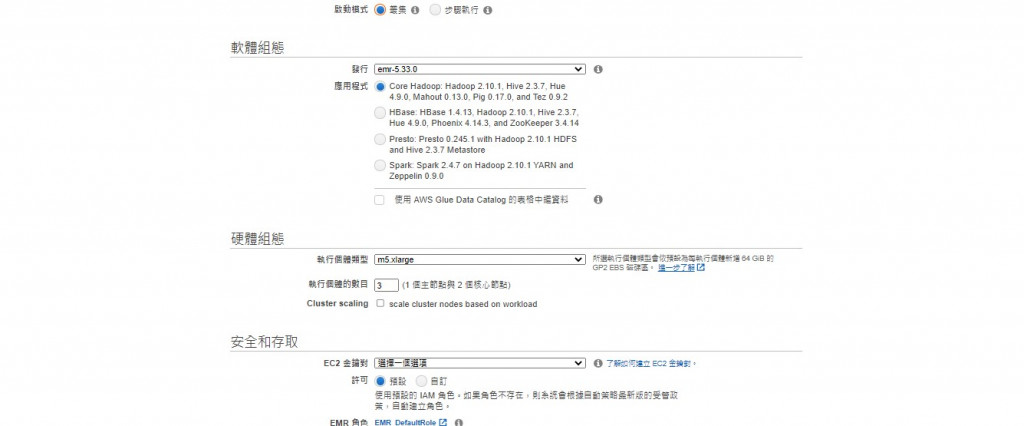
已進入生產階段的話可以直接選用叢集,還再測試開發或是希望按需執行可以選用步驟執行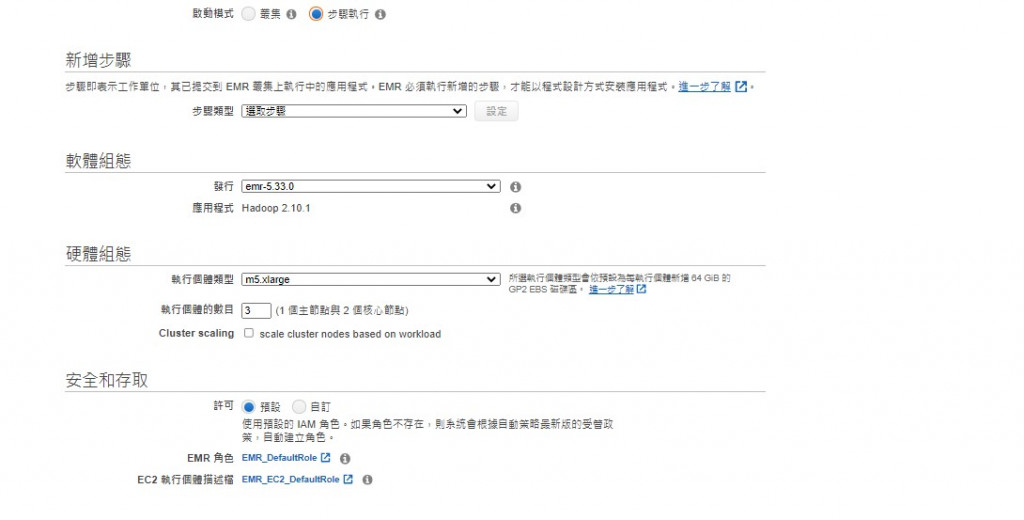
有不同步驟類型可以選擇,步驟類型就相當於指定要執行的應用程式,注意,叢集中同一時間允許閒置或執行的步驟的上限為256 個步驟。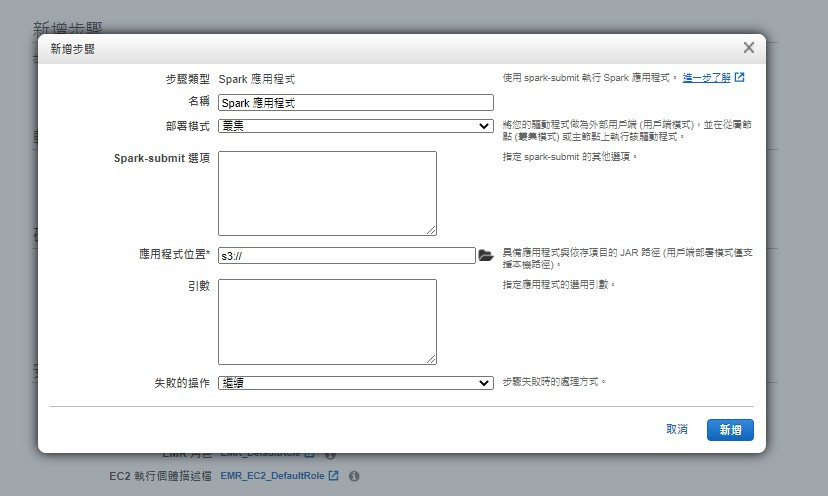
將準備好要執行的分析程式碼上傳至預先建立的bucket中,在這個步驟時方便選用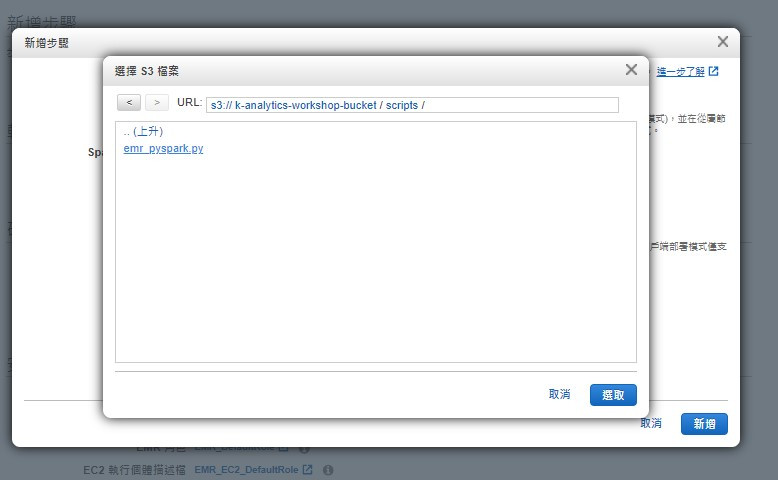
指定執行失敗時的處理方式,建議測試開發時可以選用終止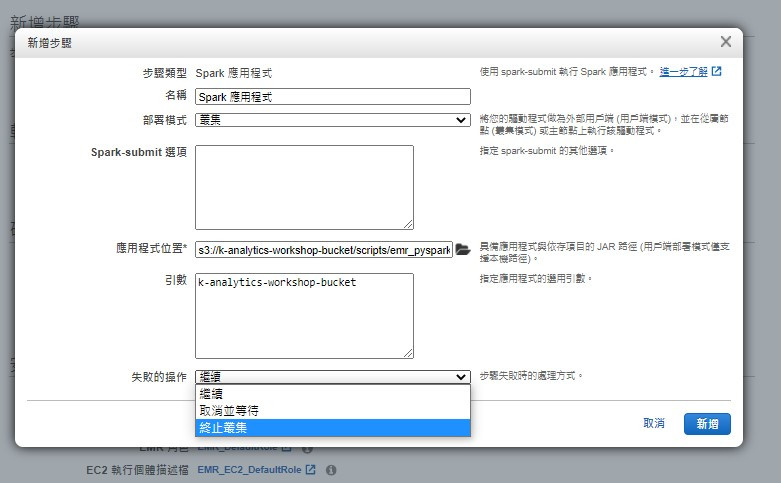
最後選定執行的Role,可以選用預設自動建立,或是預先於IAM建立好擁有適當服務權限的Role(例如 S3)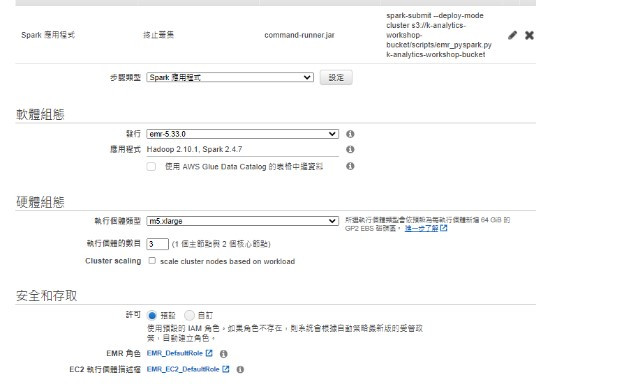
確定組態設定後就可以點選建立


 iThome鐵人賽
iThome鐵人賽