Skipfish是一個google開發的網頁安全掃描工具,主要特色如下
使用方式的確很容易,用-o指定最後報表存放的資料夾名稱,最後帶目標網頁,這邊用靶機來測試
Skipfish -o folder http://192.168.1.86
執行後會先顯示一些提示,可以直接Enter繼續執行
Welcome to skipfish. Here are some useful tips:
1) To abort the scan at any time, press Ctrl-C. A partial report will be written
to the specified location. To view a list of currently scanned URLs, you can
press space at any time during the scan.
2) Watch the number requests per second shown on the main screen. If this figure
drops below 100-200, the scan will likely take a very long time.
3) The scanner does not auto-limit the scope of the scan; on complex sites, you
may need to specify locations to exclude, or limit brute-force steps.
4) There are several new releases of the scanner every month. If you run into
trouble, check for a newer version first, let the author know next.
More info: http://code.google.com/p/skipfish/wiki/KnownIssues
掃描需要很長的時間,像下面這張圖就已經是跑了49分鐘還沒結束的狀況,從紀錄看來已經掃描出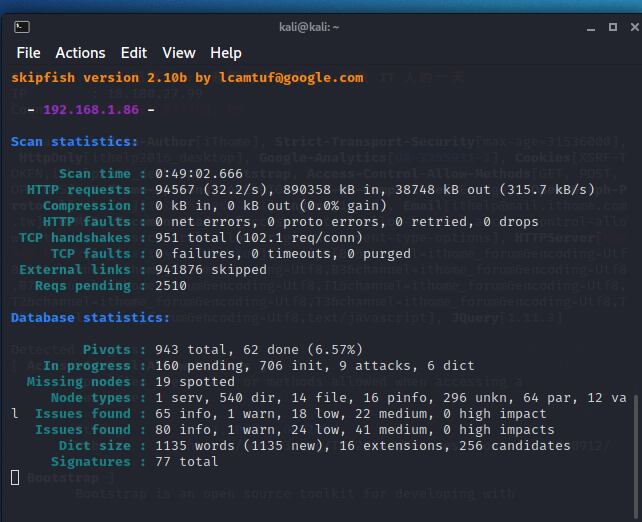
如果要中斷掃描,可以按Ctrl + C,工具會結束並標明是由使用者中斷,且掃描的所有紀錄都會被放在執行時所指定的資料夾
[!] Scan aborted by user, bailing out!
[+] Copying static resources...
[+] Sorting and annotating crawl nodes: 1141
[+] Looking for duplicate entries: 1141
[+] Counting unique nodes: 1077
[+] Saving pivot data for third-party tools...
[+] Writing scan description...
[+] Writing crawl tree: 1141
[+] Generating summary views...
[+] Report saved to 'folder/index.html' [0x9d5cc49b].
[+] This was a great day for science!
儲存的結果可以直接透過瀏覽器來打開
open folder/index.html
接著就可以用瀏覽網頁的方式,點開問題來看細節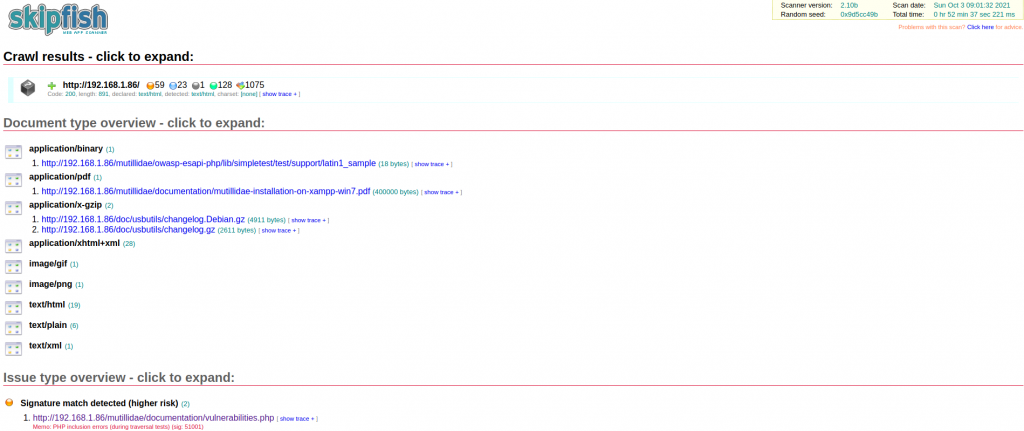
細節顯示了完整的HTTP請求與回應,但具體的問題是什麼其實還是看不懂,而且整體掃描時間很長,這次的測試環境都是在區網內,要是去測試外網的網站,那需要的時間必定會長許多,所以其實工具在一開始執行的時候也有提到,如果需要在複雜站點上做測試,需要自行指定排除某些掃描行為。

