好的,講解完 Requests 套件的基本介紹後,終於要進入真實情況的爬蟲應用拉!
但我們一步一步來,先從簡單的開始,運用我們前面提到的基本應用來做個小爬蟲。
所以我們要來爬什麼呢?
我們來爬股票吧!畢竟股票一直都是人氣很高的項目,不管在任何領域
爬蟲前要注意:爬下來的資料在你打算使用的地方,是否有違反該網站的申明。
總之爬蟲前要記得詳閱網站規章喔
我們要抓的是台灣證券交易所的資料,我們操作前確認一下使用條款,確認沒問題我們就開始囉!
抓資料前我們得先看看要透過哪個 URL 才能取得資料,那怎麼找呢?
連線至台灣證券交易所。
點選上方交易資訊,選擇個股日成交資訊。
來到此頁面。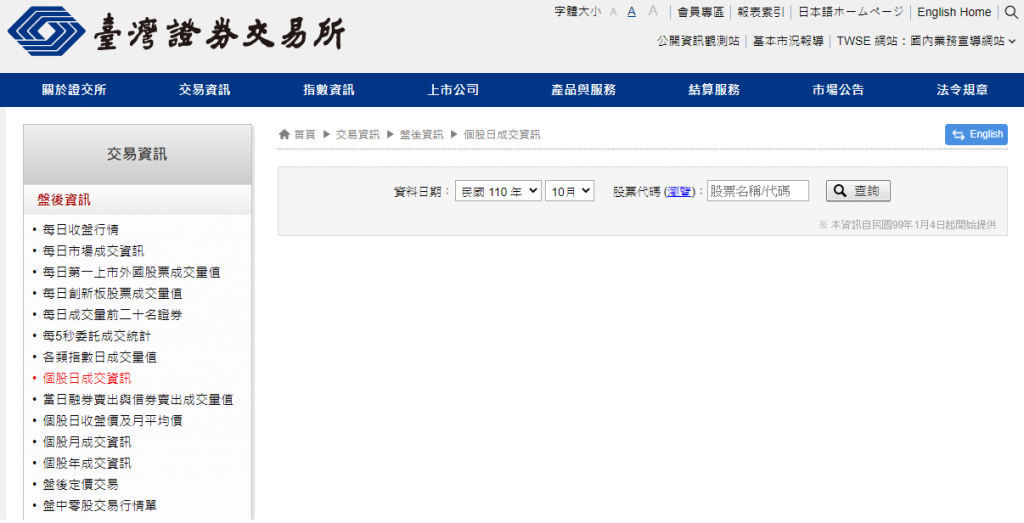
依照網頁提供的介面操作,輸入股票代碼後點擊查詢按鈕,確認資料是我們想要的。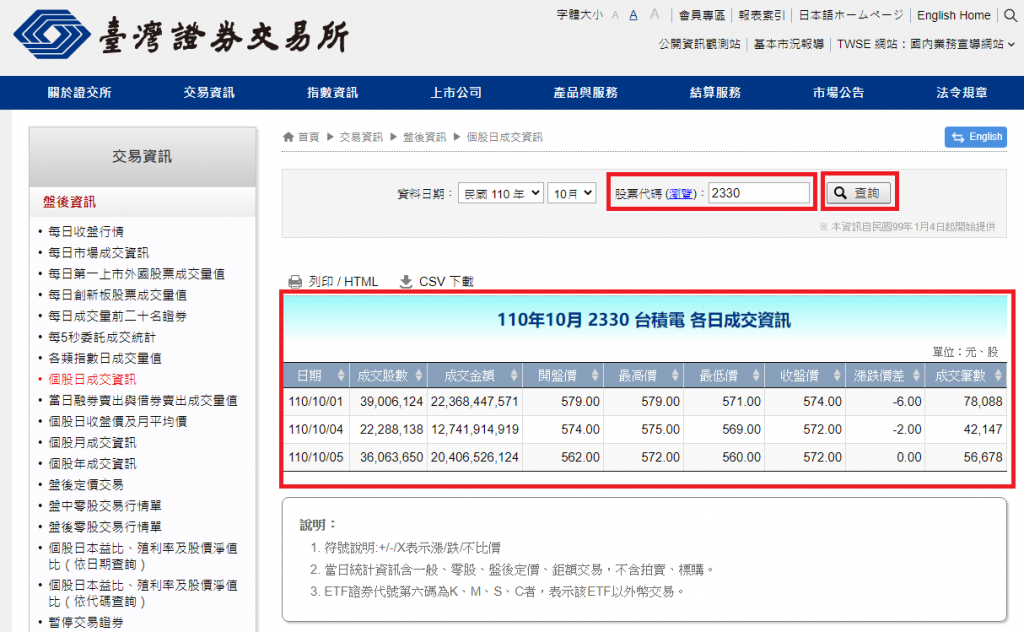
確認無誤後,開啟開發人員工具(Chrome 快捷鍵為 F12)。依照圖片紅框項目,選取欄位 Network、Fetch/XHR。請確保圖片第二排左邊之紅框紅燈是恆亮狀態(表示有在記錄網頁的行為),若有其他雜其砸八的 URL 一直跳出來擾亂請點擊第二排右邊之禁止符號(clear 的意思)。
Fetch/XHR:主要是陳列 AJAX 的 HTTP Request / Response。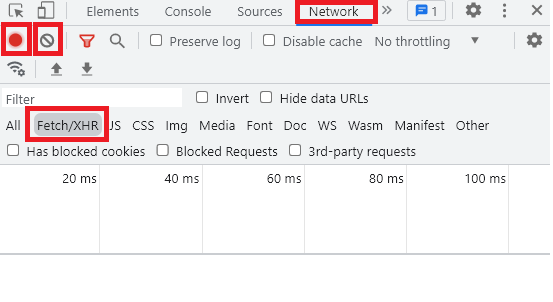
重複步驟4,依序確認左列清單得到的 Response(Preview 欄位會幫你把資料整理好,比較好看)。所以我們確定第一個清單項目就是我們要的,如下圖。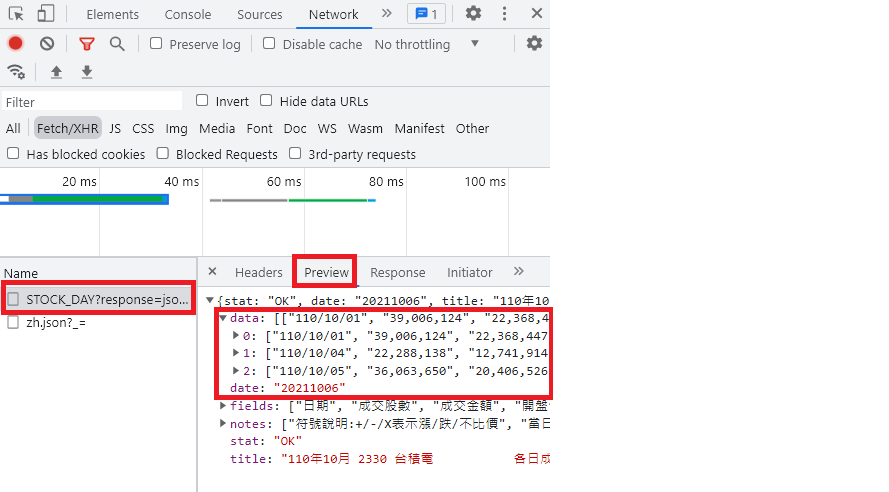
點選 Headers,看 General 的 Request URL 及 Method 與 Response Headers 的 Content-Type 可以知道:
https://www.twse.com.tw/exchangeReport/STOCK_DAY。response=json&date=20211006&stockNo=2330。不管我們 Query 的 date 是幾號,他的 server 是整個月份的日成交資訊都回給你,這點要注意一下喔!從上面的已知資訊,我們程式可以這樣寫
import requests
url = "https://www.twse.com.tw/exchangeReport/STOCK_DAY"
res = requests.get(url, params={
"response": "json",
"date": "20211006",
"stockNo": "2330"
})
# 把 JSON 轉成 Python 可存取之型態
res_json = res.json()
# 我們要的每日成交資訊在 data 這個欄位
daily_price_list = res_json.get("data", [])
# 該欄位是 List 所以用 for 迴圈印出
for daily_price in daily_price_list:
print(daily_price)
輸出:
比對一下跟使用瀏覽器得到的結果一樣就是沒問題囉!
以上就是尋找目標 URL 及抓取個股每日成交資訊,程式部分因為只是個範例,可以再依照自己需求去做變化!



