如同近年被熱烈討論的 微服務架構* 與 CQRS架構*,AWS上推廣的資料分析原則之一也是建議要將資料儲存與資料處理解耦,白話意思就是儲存資料由專門的系統負責;資料處理也交由另外專門運算的系統來執行,每個系統各司其職。當然這個架構不一定符合所有的應用需求,但以資料分析的應用情境來看,解耦的好處之一是:資料能夠以它更接近原始的樣貌被儲存著,當使用者有多元的分析需求時(,比如說同一個公司的行銷部門與研發部門要對同一份產品使用資料集產出不同的分析報告),這樣不同的分析程序都能觸及最原始的資料,避免後續不同資料流的分析處理相互影響而導致結果失真,導致決策者做出失準的決定。
在AWS上最常見的資料儲存服務S3就常擔任分析資料流中那唯一真實資料源single source of truth*的角色,例如前一篇所介紹的Athena查詢服務就是將儲存工作交由S3負責,而Athena專門執行分析查詢等任務。
下圖為AWS分析中的一個典型快速分析架構,就是串接S3、Athena與Glue。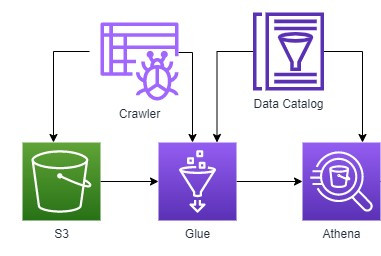
資料存進S3之後,就可以建立編目程式/Crawler(可參考Day13*)
利用編目程式在Glue中創建Data Catalog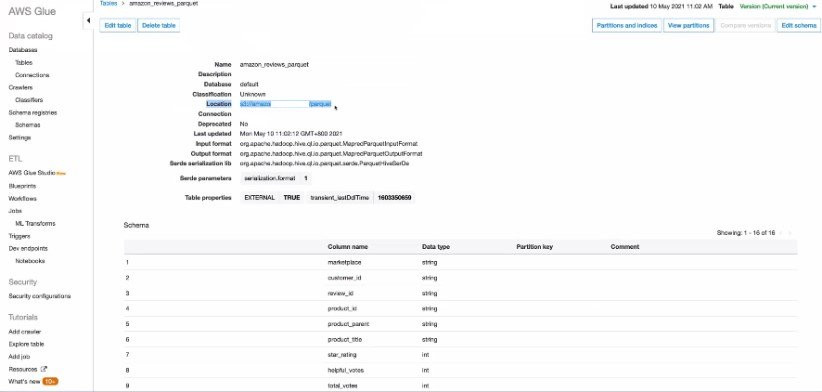
確認Data Catalog建立之後就可以進入Athena服務頁面,透過網頁編輯器來下SQL查詢語法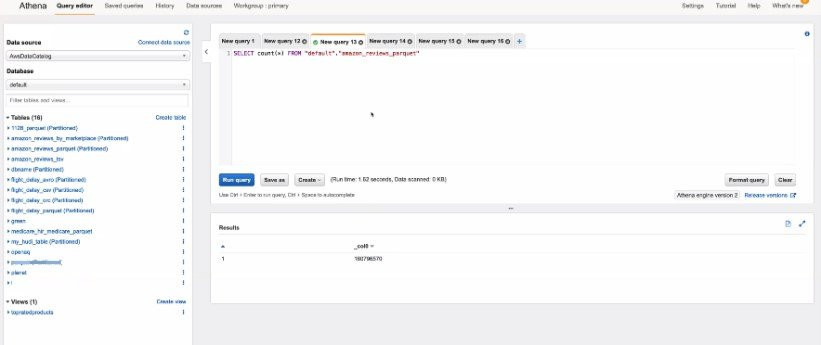
如果S3中是以壓縮檔來儲存的話可以大幅降低語法的掃描資料量
選用parquet等column-based 壓縮檔時也提升聚合語法的效能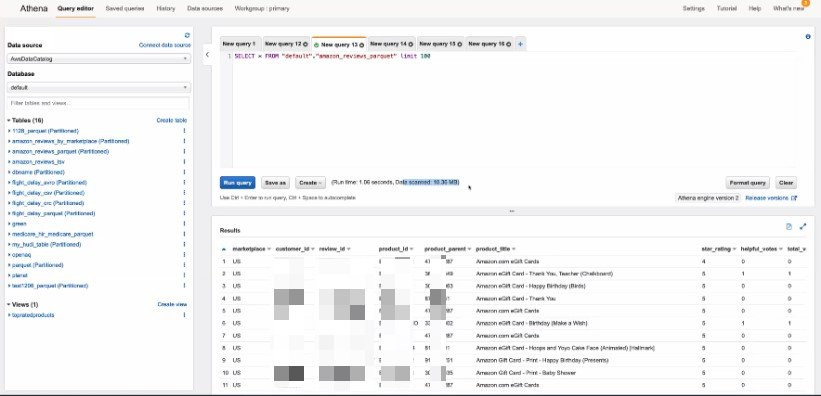
有返回資料就是有掃描資料量,可以再編輯器下方查看
注意Athena是掃描的資料量是收費的標準,所以值得一提的節省用量方法是在Data Catalog中建立partition key,partition key相當於S3中的資料夾名稱(實際上就是prefix)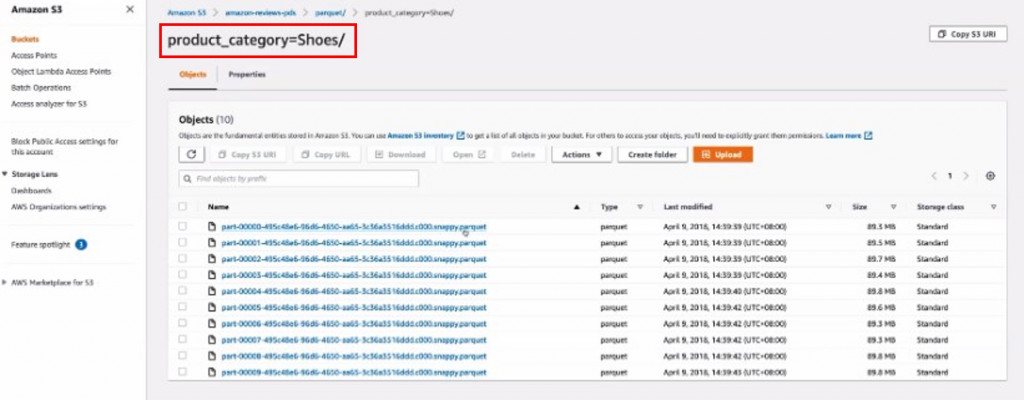
如果在S3儲存檔案時按照Key=Value 的prefix格式儲存,編目程式執行時會將prefix建立在Glue catalog 的partition key 欄位,方便在Athena下SQL時使用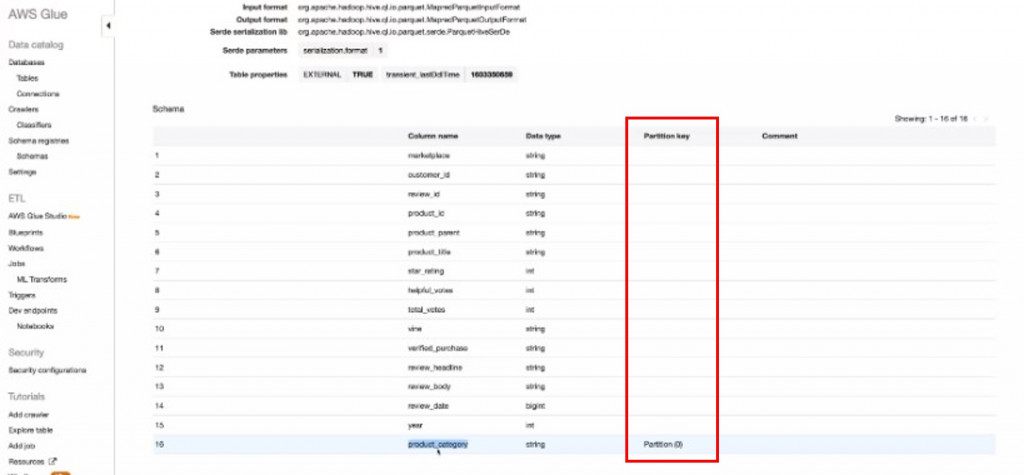
*微服務架構( https://zh.wikipedia.org/wiki/%E5%BE%AE%E6%9C%8D%E5%8B%99 )
*CQRS架構( https://en.wikipedia.org/wiki/Command%E2%80%93query_separation )
*Single source of truth ( https://en.wikipedia.org/wiki/Single_source_of_truth )
*Day13( https://ithelp.ithome.com.tw/articles/10271765 )

