第四個要討論的V是準確性Veracity,在資料處理的過程中,資料會從原本的原始資料raw data經過不同軟體的轉置、擷取、篩選等運算,處理後資料processed data透過網路在不同的裝置與伺服器間傳輸、儲存。(資料轉換過程可參考DAY7*的 Lake House架構圖) 經過的處理越多、經手的人員越多,就會讓最終的資料使用者(決策者)思考資料準確性的問題,因為可靠的決策需要來自可信的資料,處理後資料的意義是否還有具有代表性都有可能會被質疑。
如何確保資料在運算處理過程中的準確性,是從另一個角度來檢視ETL的過程,處理後資料的真實性/一致性有兩種方式來定義:ACID 與 BASE。
ACID*(Atomicity, Consistency, Isolation, and Durability):
強調資料具有強一致性
主要是關聯式資料庫中,確保交易(transaction)在邏輯轉換不會失真所規定得四大特性。
BASE*( Basically Available Soft state Eventually):
強調資料的最終一致性
主要是非關聯式資料庫中,因為重視資料的可用性,所以犧牲掉一點對一致性的要求,當然適用的資料也會是像經緯度這種比較不會被影響的資料類型。
在速度的部分介紹「執行ETL處理」的應用,真實性的部分介紹「查詢ETL處理結果」的服務。
Amazon Athena是可以使用ANSI SQL執行互動式查詢的無伺服器服務。Athena底層使用Presto,不需要繁複的設定就可以查詢從存在S3的資料,當使用者只是需要快速分析一份資料或產出一份報表時就非常適合。
每次登入使用Athena的user都在某個工作群組workgroup之下,預設使用primary workgroup
Workgroup可以用來限制/控制掃描量,如果是因為頂到預先建立的限制而被終止的SQL將不會收費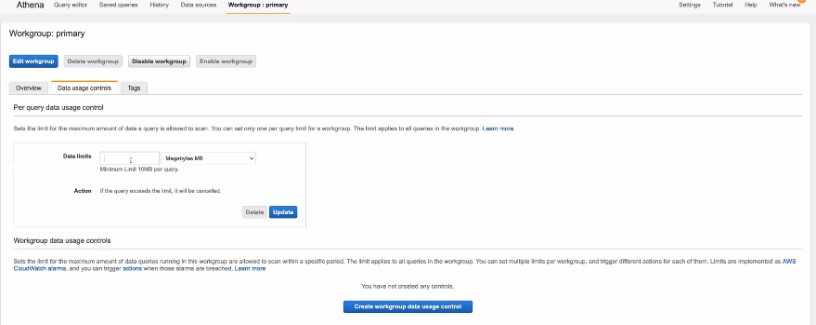
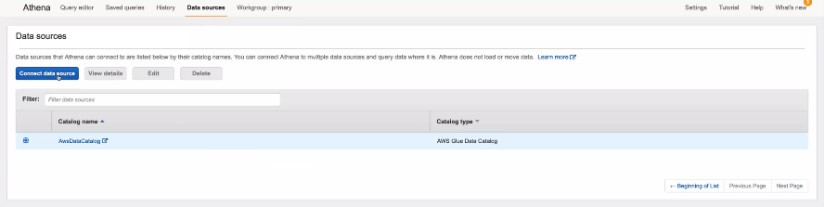
如果第一次使用時無法查詢也可能是需要設定workgroup
如果不是第一次進入Athena,會直接進入查詢編輯器的頁面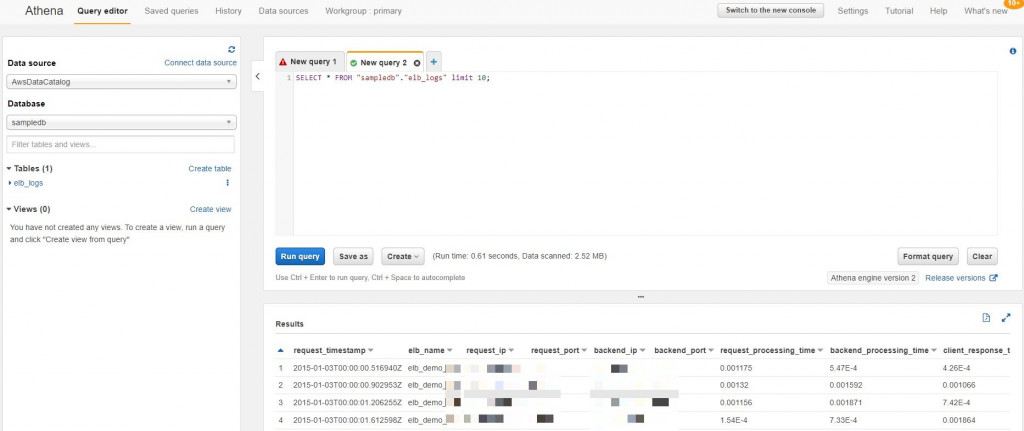
在中央編輯區下SQL指令即可,查詢結果會出現在下方,
編輯器左方Data Source可以設定資料庫,可以加入多個來源執行聯合查詢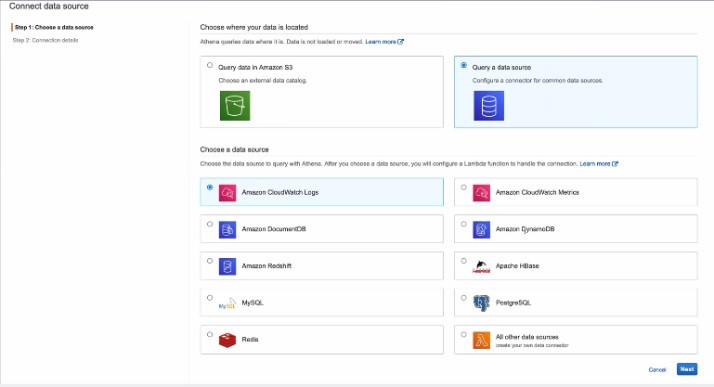
Athena的服務主要是集成Glue Data Catalog的功能,Athena利用data catalog的虛擬資料表中的中繼資料,來查詢S3中的資料,架構大概如下。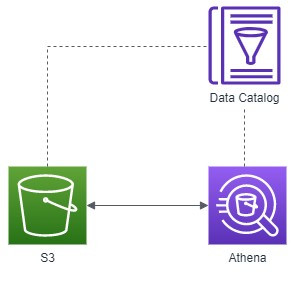
值得注意的是,Athena是按照數據掃描量收費,所以壓縮資料可以節省費用,查詢失敗不收費。
查詢結果會可以從Result右方的小檔案圖示下載,也同時會存在S3。
*ACID( https://zh.wikipedia.org/wiki/ACID )
*DAY7( https://ithelp.ithome.com.tw/articles/10267527 )
*BASE( https://zh.wikipedia.org/wiki/%E6%9C%80%E7%BB%88%E4%B8%80%E8%87%B4%E6%80%A7 )

