=== 書接上回,[Day 27] Edge Impulse + BLE Sense實現影像分類(上) ===
在前面有提及在增加「學習區塊(Learning Block)」時,系統會推薦使用「遷移學習」。進到「遷移學習(Transfer Learning)」頁面時,系統預設「訓練次數(Training Cycles)」為20,「學習率(Learning Rate)」為0.0005,「資料擴增(Data Augmentation)」為不勾選。若勾選則會自動增加一些資料變化性讓模型訓練後能更強健。而預設模型會選用「MobileNetV2 96x96 0.35 dropout」。此時按下【Start Training】後,會得到一組很糟的訓練結果,準確率只有50%,而損失則有1.06,更糟的是會發現右下角的裝置效能,推論時間要7,231ms,且竟要使用346.8KB的RAM和574.4KB的FLASH(即模型參數區加模型推論程式碼部份),明顯超過了Arduino Nano 33 BLE Sense SRAM 256KB的限制(FLASH未超過1MB容量)。
所以此時需重新點擊【Choose a different model】來重新選擇較小的模型,如MobileNetV1 96x96 0.1(0.1代表Dropout比例),它只需使用53.2KB的RAM和101KB的ROM(等同於FLASH)。再重新按下【Start Training】後,可得推論時間423ms,使用RAM 66.0KB和FLASH 106.8KB,明顯小了許多。而精確度問題,稍後再解釋。完整步驟如圖Fig. 28-1所示。
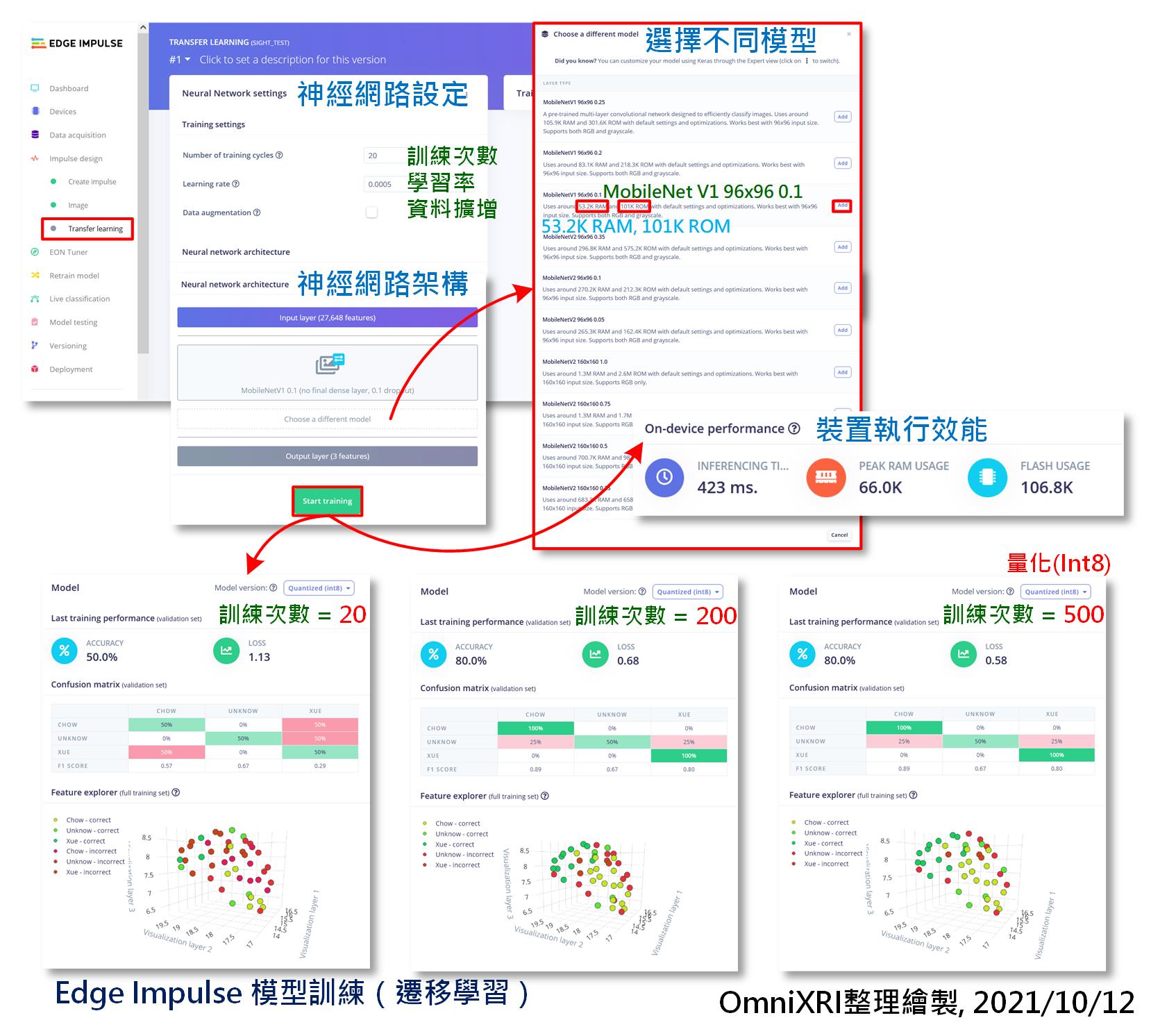
Fig. 28-1 Edge Impulse模型訓練(遷移學習)。(OmniXRI整理繪製, 2021/10/12)
以下簡單列出目前內建的10種模型及RAM和ROM的使用量,由Table 28-1中可得知,BLE Sense開發板只能支援前3種模型。
Table 28-1 遷移學習模型使用資源表(OmniXRI整理製表, 2021/10/13)
| Model Name | RAM | ROM | BLE Sense |
|---|---|---|---|
| MobileNetV1 96x96 0.25 | 105.9K | 301.6K | O |
| MobileNetV1 96x96 0.2 | 83.1K | 218.3K | O |
| MobileNetV1 96x96 0.1 | 53.2K | 101K | O |
| MobileNetV2 96x96 0.35 | 296.8K | 575.2K | X |
| MobileNetV2 96x96 0.1 | 270.2K | 212.3K | X |
| MobileNetV2 96x96 0.05 | 265.3K | 162.4K | X |
| MobileNetV2 160x160 1.0 | 1.3M | 2.6M | X |
| MobileNetV2 160x160 0.75 | 1.3M | 1.7M | X |
| MobileNetV2 160x160 0.5 | 700.7K | 982.4K | X |
| MobileNetV2 160x160 0.35 | 683.3K | 658.4K | X |
如果想要使用其它更小的模型,則必須切換到專家模式(Expert),手動方式定義模型,如你不是非常精通這些程式運作,建議不要隨意更動。以下列出在專家模式下MobileNetV1 96x96 0.1時的模型源碼,以供參考。
# MobileNetV1 0.1 (no final dense layer, 0.1 dropout) 專家模式模型原始程式
import math
from pathlib import Path
import tensorflow as tf
from tensorflow.keras import Model
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, InputLayer, Dropout, Conv1D, Flatten, Reshape, MaxPooling1D, BatchNormalization, Conv2D, GlobalMaxPooling2D, Lambda
from tensorflow.keras.optimizers import Adam, Adadelta
from tensorflow.keras.losses import categorical_crossentropy
sys.path.append('./resources/libraries')
import ei_tensorflow.training
WEIGHTS_PATH = './transfer-learning-weights/edgeimpulse/MobileNetV1.0_1.96x96.color.bsize_96.lr_0_05.epoch_66.val_accuracy_0.14.hdf5'
INPUT_SHAPE = (96, 96, 3)
base_model = tf.keras.applications.MobileNet(
input_shape = INPUT_SHAPE,
weights = WEIGHTS_PATH,
alpha = 0.1
)
base_model.trainable = False
model = Sequential()
model.add(InputLayer(input_shape=INPUT_SHAPE, name='x_input'))
# Don't include the base model's top layers
last_layer_index = -6
model.add(Model(inputs=base_model.inputs, outputs=base_model.layers[last_layer_index].output))
model.add(Dropout(0.1))
model.add(Dense(classes, activation='softmax'))
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.0005),
loss='categorical_crossentropy',
metrics=['accuracy'])
BATCH_SIZE = 32
train_dataset = train_dataset.batch(BATCH_SIZE, drop_remainder=False)
validation_dataset = validation_dataset.batch(BATCH_SIZE, drop_remainder=False)
callbacks.append(BatchLoggerCallback(BATCH_SIZE, train_sample_count))
model.fit(train_dataset, validation_data=validation_dataset, epochs=500, verbose=2, callbacks=callbacks)
print('')
print('Initial training done.', flush=True)
# How many epochs we will fine tune the model
FINE_TUNE_EPOCHS = 10
# What percentage of the base model's layers we will fine tune
FINE_TUNE_PERCENTAGE = 65
print('Fine-tuning best model for {} epochs...'.format(FINE_TUNE_EPOCHS), flush=True)
# Load best model from initial training
model = ei_tensorflow.training.load_best_model(BEST_MODEL_PATH)
# Determine which layer to begin fine tuning at
model_layer_count = len(model.layers)
fine_tune_from = math.ceil(model_layer_count * ((100 - FINE_TUNE_PERCENTAGE) / 100))
# Allow the entire base model to be trained
model.trainable = True
# Freeze all the layers before the 'fine_tune_from' layer
for layer in model.layers[:fine_tune_from]:
layer.trainable = False
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.000045),
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(train_dataset,
epochs=FINE_TUNE_EPOCHS,
verbose=2,
validation_data=validation_dataset,
callbacks=callbacks)
在剛才第一次訓練後得到的結果非常差,所以最簡單的方式就是先把訓練次數加高,學習率暫不變動,保持在0.0005,如圖Fig. 28-1的下半部圖示。當訓練次數提高到100次時,精確度提升到70%,損失0.80。當再提高訓練次數到200次時,精確度已提升到80%,而損失已降至0.68。可是當訓練次數再提高至500次時,精確度已難以提升,但損失仍有略微下降至0.58,還是有所改善。這裡精確度無法再提升還有一個主因是樣本數過少導致,只需增加樣本數量及多樣性就能有所改善。
在前面建立「學習區塊(Learning Block)」時,曾說明系統預設是推薦「遷移學習(Transfer Learning)」選項,但其實也可選「影像分類(Classification (Keras))」,再按下【Save Impulse】按鈕後,左側選單就會出現「NN Classification」取代原有的「Transfer Learning」。而這個選項就是一般層數較少的「卷積神經網路(Convolutional Neural Network, CNN)」。但請注意學習區塊只須建立一種就好,不要同時建兩種。
把頁面切到「NN Classification」後,預設的「訓練次數」為10,「學習率」為0.0005,輸入層特徵數為27,648(即96x96像素x3通道之總數),輸出層為3個分類,隱藏層為2個2D卷積池化層(2D conv/pool)加上一個展平層(Flatten)和隨機丟棄層(Dropout, rate 0.25)所組成。其中第1卷積層預設卷積核3x3,32個特徵圖(Filter,Feature Map),而第2層則為16個特徵圖。
為了比較,這裡把「訓練次數」先調成20,當按下【Start Training】按鈕後,就可以開始訓練模型。第一次得到的結果,不算太理想,精確率只有70%,損失0.88,看起來好像比遷移學習好(?)。但注意一下畫面左下角的RAM使用量,竟已高達364.0KB,明顯超過BLE Sense開發板的SRAM 256KB,這樣就算完成訓練也無法佈署到開發板上。所以要將游標移到第1卷積池化層「2D conv/pool layer」按鈕上方,待出現4個小按鈕,點下編輯濾波器(Filter,就是特徵圖數量),將32改成16。同樣地把第2卷積池化層的濾波器數量改為8。再重新按下【Start Training】重新訓練一次,這次會得到一個比較好的結果精確率只有90%,損失0.63,且RAM的使用量已降到183.2KB,滿足佈署條件。但這裡大家可能會發現一個奇怪的問題,怎麼參數變少了反而得到較好的結果。其實這只是一個假像,只是碰巧這幾筆資料滿足模型,有點過擬合的味道。
接著為了和「遷移學習」作一些比較,這裡分別調整「訓練次數」為50, 100,200來求得精確率和損失。而眼尖的人大概有注意到訓練100次和200次的精確度和損失已相同,表示已收歛,再增加次數也無法改善,需從其它方向來改善。完整的操作步驟如圖Fig. 28-2所示。

Fig. 28-2 Edge Impulse模型訓練(影像分類)。(OmniXRI整理繪製, 2021/10/12)
如果想要使用其它更小的模型,則必須切換到專家模式(Expert),手動方式定義模型,如你不是非常精通這些程式運作,建議不要隨意更動。以下列出在專家模式下NN Classifier (CNN)的模型源碼,以供參考。
# NN Classifier 專家模式模型原始程式
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, InputLayer, Dropout, Conv1D, Conv2D, Flatten, Reshape, MaxPooling1D, MaxPooling2D, BatchNormalization, TimeDistributed
from tensorflow.keras.optimizers import Adam
# model architecture
model = Sequential()
model.add(Conv2D(16, kernel_size=3, activation='relu', kernel_constraint=tf.keras.constraints.MaxNorm(1), padding='same'))
model.add(MaxPooling2D(pool_size=2, strides=2, padding='same'))
model.add(Conv2D(8, kernel_size=3, activation='relu', kernel_constraint=tf.keras.constraints.MaxNorm(1), padding='same'))
model.add(MaxPooling2D(pool_size=2, strides=2, padding='same'))
model.add(Flatten())
model.add(Dropout(0.25))
model.add(Dense(classes, activation='softmax', name='y_pred'))
# this controls the learning rate
opt = Adam(lr=0.0005, beta_1=0.9, beta_2=0.999)
# this controls the batch size, or you can manipulate the tf.data.Dataset objects yourself
BATCH_SIZE = 32
train_dataset = train_dataset.batch(BATCH_SIZE, drop_remainder=False)
validation_dataset = validation_dataset.batch(BATCH_SIZE, drop_remainder=False)
callbacks.append(BatchLoggerCallback(BATCH_SIZE, train_sample_count))
# train the neural network
model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy'])
model.fit(train_dataset, epochs=20, validation_data=validation_dataset, verbose=2, callbacks=callbacks)
有了上述二種模型的訓練結果,其推論時間及使用資源可參考Tabel 28-2所示。在佈署到實際開發板前,可以利用Edge Impulse的「Model Testing」頁面來測試一下先前保留的測試集資料的推論結果。進到頁面後,只需按下【Classify All】就能得到精確度和混淆矩陣,還會顯示出不確定(Uncertain)的資料比例。系統預設「置信度門檻(Confidence thresholds)為0.6」,當低於這個門檻會被歸在不確定的範圍,當這個比例過高時,可能就會重新檢討資料集的建立及模型設計方向。這裡因為測試資料集數量太小(3分類各4筆,共12筆),所以精確度僅供參考。
Table 28-2 模型使用資源比表(OmniXRI整理製表, 2021/10/13)
| Model Name | Inference Time(ms) | Peak RAM Usage | Flash Usage |
|---|---|---|---|
| MobileNet V1 96x96 0.1 | 423ms | 66KB | 106.8KB |
| Classification (CNN) | 1,188ms | 183.2KB | 46.5KB |
在圖Fig. 28-3中,分別使用已訓練500次的遷移學習MobileNetV1模型和訓練200次(已收歛)的卷積神經網路(CNN)影像分類模型來測試。測試時分別給予不同的置信度門檻 0.6, 0.5和0.4。從圖表中可得知當門檻越低時,不確定的資料比例就會下降,推論精確度也會略微提升。而兩種模型的表現各有優劣,可能要使用更大的測試集來驗證會更準確一些。

Fig. 28-3 Edge Impulse模型訓練結果比較。(OmniXRI整理繪製, 2021/10/12)
另外雖然最後模型還是可以佈署到BLE Sense上進行推論,但這裡未能使用真正的攝影機模組取像,少了點味道,所以就先不介紹佈署和執行後的結果,希望後續拿到攝像頭後再來撰寫相關實測心得。
影像的辨識比起聲音或感測器辨識來說不僅資料維度增加至二維,同時輸入特徵及訓練的參數的數量也呈指數爆增,訓練時間更是漫長,想要得到好的辨識結果更有許多AI相關知識要學習。目前各種tinyML的開發板對於影像類應用還是有點不足,期待未來有更好的算法、更強的算力及更便宜的解決方案問世,這樣才有機會讓tinyML普及到生活各種智能應用上。
參考連結
Edge Impulse Tutorials - Adding sight to your sensors說明文件
Edge Impulse Development Board - Arduino Nano 33 BLE Sense with OV7675 camera add-on說明文件

