集成學習 (ensemble learning) 的概念在於透過結合多個不同的模型來達到不同模型之間彼此互補的效果,簡單來說就是 「三個臭皮匠勝過一個諸葛亮」。
為了方便,我們會使用 MLP、CNN 及 RNN 來表示上述實驗所提到的 MLP(兩層隱藏層,L = 2,tanh)、multi-scale CNN with attention mechanism(tanh) 及 LSTM-RNN with attention mechanism(tanh)三種模型。
在今天的內容中我們會介紹三種 ensemble learning 的方式:
Bagging 的流程會分為三個步驟:
balanced bootstrap sampling),共進行 k 輪選取,建構出 k 個訓練集(每一輪建構出的訓練集,可能會缺少原始訓練集中的部份樣本,並且可能會包含多個重複的樣本)。圖1 為 bagging 訓練過程的流程圖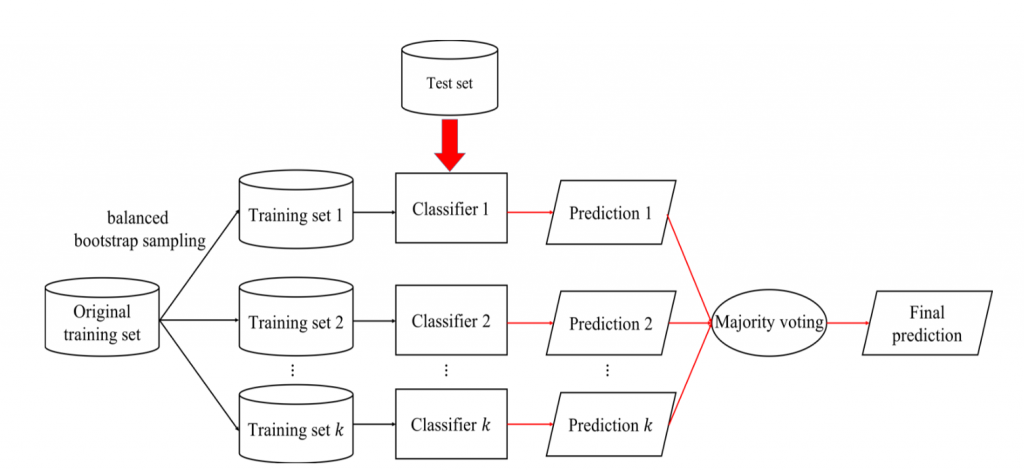
圖1: Bagging訓練過程流程圖。黑色箭頭表示訓練階段,紅色箭頭表示測試階段
除了一般的 bagging之 外,我們也會對 bagging 的訓練過程做部份的調整並比較不同 bagging 之間的結果。對於 bagging 訓練過程的調整包含以下三種:
在每一輪的訓練過程中隨機從三種分類器(MLP、CNN、RNN)中選出一種做為此輪的分類模型。random missing data 的機制。此機制會根據遺失率(missing ratio)m(設定為 10%)隨機丟棄部份的資料,經過 random missing data 的機制所產生的資料集稱為不完整訓練集(incomplete training set),其資料總數會比原始訓練集少。random missing feature 的機制。此機制與 random missing data 類似,差異點在於此步驟是隨機的將部份特徵值丟棄。靜態模型與動態模型特徵向量維度的變化如下:
經過以上三個部份的調整後,bagging 的訓練過程如圖 2。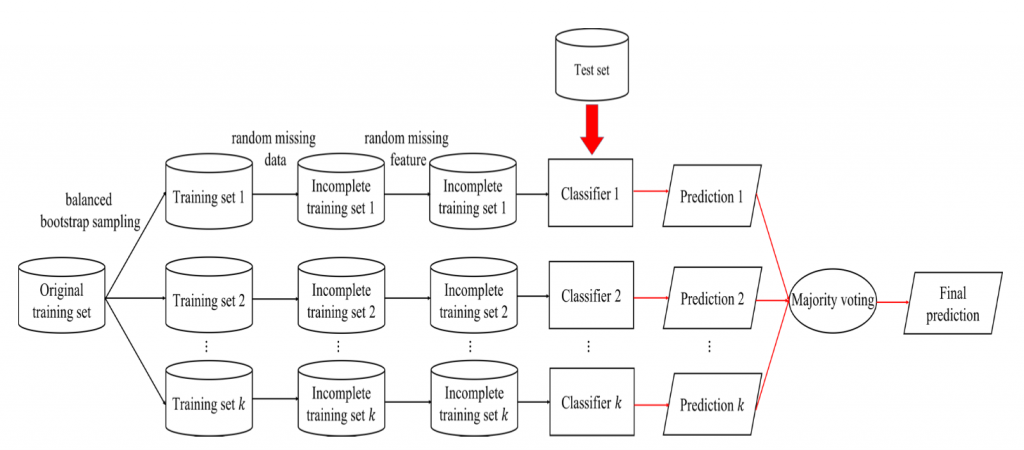
圖2: 調整過後bagging訓練過程流程圖。黑色箭頭表示訓練階段,紅色箭頭表示測 試階段
我們先透過下表來觀察一般的 bagging 結果
Base classifier | # bootstrap (k) | UA recall
------------- | -------------
MLP | 10,20 | 45.8%,46.0%
CNN | 10,20 | 45.4%,45.6%
RNN | 10,20 | 45.7%,45.9%
表1: 一 般bagging實驗結果 。# bootstraps (k)表示 balanced bootstrap sampling 次數
而經過調整過後的 bagging 結果如表2。
Adjust method | Base classifier | # bootstrap (k) | UA recall
------------- | -------------
Bagging with random base classifier | MLP or CNN or RNN | 10,20,30| 46.2%,47.5%,48.0%
Bagging with random base classifier and random missing data | MLP or CNN or RNN | 10,20,30 | 47.0%,47.7%,48.2%
Bagging with random base classifier and random missing data and random missing feature | MLP or CNN or RNN | 10,20,30 | 45.9%,47.3%,47.7%
表2: 調整過後bagging實驗比較。# bootstraps (k)表示 balanced bootstrap sampling 次數
從結果中可得知一般的 bagging 無法提升效能而調整後的 bagging 能夠提升至 48.2%。主要原因為一般的 bagging 差異性只來自於不同的訓練集,導致 bagging 過程中每一輪訓練得到的分類器差異性不大無法達到互補的效果。
進一步觀察表 2 可發現加入 random missing data 後 UA recall 有些微的提升而再加入 random missing feature 後 UA recall 反而是下降的,主要原因應是將部份的特徵丟棄之後可能使神經網路無法藉由剩下的特徵學習到不同類別間的差異,導致分類器的辨識能力降低。
明天將續介紹另外兩種 ensemble learning 的方法。

