動態模型我們會使用 LSTM-based 架構,並分成兩種:
如 Day20 中提過的,動態模型的輸入特徵為 32 維的特徵向量。Basic LSTM 中的 last-frame only 與 mean-pooling over time 使用的是相同的模型架構,差別在於 last-frame only 只取第二層 LSTM 最後一個時間點(timestamp)的輸出輸入至輸出層;而 mean-pooling over time 則是對第二層 LSTM 所有時間點的輸出做 mean-pooling 取平均後輸入至輸出層,此做法是希望藉由參考到LSTM所有時間點的輸出來使網路能夠學習到足夠且情緒鮮明的資訊。架構如圖 1。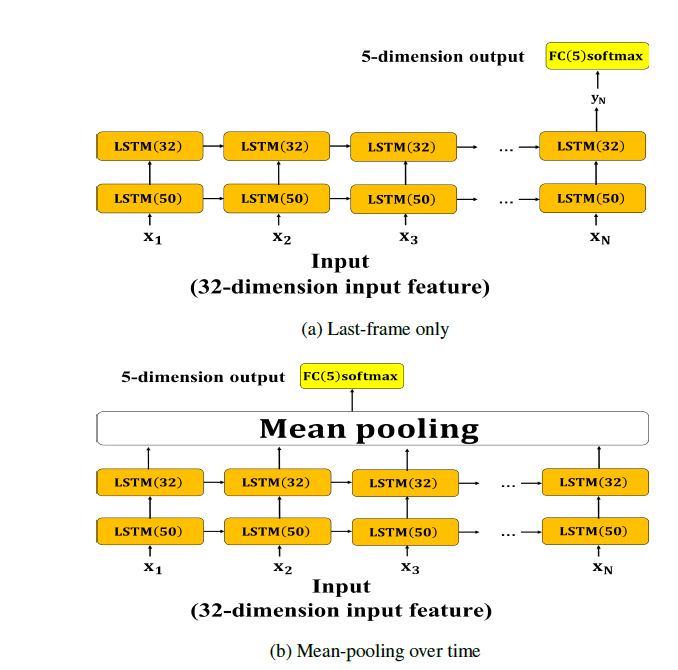
圖 1: LSTM 動態模型架構圖。兩層 LSTM 使用的激活函數為 tanh、ReLU
兩種架構的分類結果如表 1。
Model | UA recall (tanh) | UA recall (ReLU)
------------- | -------------
Last-frame only | 37.0% | 20.0%
Mean-pooling over time | 40.6% | 20.0%
表1: Basic LSTM 分類結果
在使用 keras 套件建構 LSTM 模型時直接使用 LSTM layer 就可以了,需要注意的地方在於如果是 last-frame only 的話最後一層的 LSTM layer return_sequences 這個參數要設成 False;mean-pooling over time 則是設為 True。
# last-frame only
dynamic_input = Input(shape=[max_length, args.dynamic_features], dtype='float32', name='dynamic_input')
lstm1 = LSTM(60, activation='tanh', return_sequences=True, recurrent_dropout=0.5, name='lstm1')(dynamic_input)
lstm2 = LSTM(60, activation='tanh', return_sequences=False, recurrent_dropout=0.5, name='lstm2')(lstm1)
output = Dense(args.classes, activation='softmax', name='output')(lstm2)
model = Model(inputs=dynamic_input, outputs=output)
model.summary()
# meal-pooling over time
dynamic_input = Input(shape=[max_length, args.dynamic_features], dtype='float32', name='dynamic_input')
lstm1 = LSTM(60, activation='tanh', return_sequences=True, recurrent_dropout=0.5, name='lstm1')(dynamic_input)
lstm2 = LSTM(60, activation='tanh', return_sequences=True, recurrent_dropout=0.5, name='lstm1')(lstm1)
mean = Lambda(lambda xin: K.mean(xin, axis=1))(lstm2)
output = Dense(args.classes, activation='softmax', name='output')(mean)
model = Model(inputs=dynamic_input, outputs=output)
model.summary()
另外因為資料集中幾乎每一筆語音檔長度都不會一樣,為了輸入到模型進行訓練通常會使用 **padding (補值,一般是補 0)**的方式將所有語音檔補成相同的長度,這部分可以使用 tf.keras.preprocessing.sequence.pad_sequences 這個 function 來達成。
從表中可以得知,不管是哪一種方法 basic LSTM 的效果都滿差的,因此希望透過 attention 機制找出一段語音中情緒顯著的部分來提升準確率。

